




- 标签编码
- 连续特征的处理:归一化和标准化
作业:对心脏病数据集的特征用上述知完成,一次性用所有的处理方式完成预处理,尝试手动完成,多敲几遍代码。
完成预处理的流程总结:
1.先做缺失值处理 → 2. 数值特征标准化 → 3. 类别特征编码 → 4. 最终数据验证
对心脏病数据集的特征预处理的完整代码:
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 1. 读取数据
df = pd.read_csv('d:\\英雄时刻\\Python日记\\day8\\heart.csv')
# 2. 查看数据基本信息
print("原始数据前5行:")
print(df.head())
print("\n数据基本信息:")
print(df.info())
# 3. 处理缺失值 (如果存在)
print("\n缺失值统计:")
print(df.isnull().sum())
# 4. 数值型特征标准化
numeric_cols = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']
print("\n数值型特征标准化:")
# 4.1 标准化 (均值为0,方差为1)
scaler = StandardScaler()
df_standardized = df.copy()
df_standardized[numeric_cols] = scaler.fit_transform(df_standardized[numeric_cols])
print("\n标准化后的数据(前5行):")
print(df_standardized[numeric_cols].head())
# 4.2 归一化 (缩放到[0,1]范围)
scaler = MinMaxScaler()
df_normalized = df.copy()
df_normalized[numeric_cols] = scaler.fit_transform(df_normalized[numeric_cols])
print("\n归一化后的数据(前5行):")
print(df_normalized[numeric_cols].head())
# 5. 类别型特征编码
categorical_cols = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal', 'target']
# 5.1 标签编码 (转换为0到n_classes-1的数值)
df_label_encoded = df.copy()
label_encoder = LabelEncoder()
for col in categorical_cols:
df_label_encoded[col] = label_encoder.fit_transform(df_label_encoded[col])
print("\n标签编码后的数据(前5行):")
print(df_label_encoded[categorical_cols].head())
# 5.2 独热编码 (创建虚拟变量)
df_onehot = df.copy()
onehot_encoder = OneHotEncoder(sparse_output=False, drop='first')
encoded_features = onehot_encoder.fit_transform(df_onehot[categorical_cols])
encoded_df = pd.DataFrame(encoded_features,
columns=onehot_encoder.get_feature_names_out(categorical_cols))
# 检查标准化/归一化后的数值特征
print("\n标准化数据统计描述:")
print(df_standardized[numeric_cols].describe())
# 检查编码后的类别特征
print("\n独热编码数据统计描述:")
print(df_onehot.describe())
import matplotlib.pyplot as plt
# 数值特征分布检查
df_standardized[numeric_cols].hist(bins=50, figsize=(12,8))
plt.suptitle('标准化后数值特征分布')
plt.show()
# 类别特征分布检查(示例检查一个编码后的列)
if 'sex_1' in df_onehot.columns:
df_onehot['sex_1'].value_counts().plot(kind='bar')
plt.title('性别独热编码分布')
plt.show()
# 检查处理后的前5行样本
print("\n标准化数据样本:")
print(df_standardized.head())
print("\n独热编码数据样本:")
print(df_onehot.head())
print("\n标准化数据缺失值:")
print(df_standardized.isnull().sum())
print("\n独热编码数据缺失值:")
print(df_onehot.isnull().sum())
print("\n标准化数据类型:")
print(df_standardized.dtypes)
print("\n独热编码数据类型:")
print(df_onehot.dtypes)
预处理分步理解:
1.数据加载与初步检查:
# 1. 读取数据
df = pd.read_csv('d:\\英雄时刻\\Python日记\\day8\\heart.csv')
# 2. 查看数据基本信息
print("原始数据前5行:")
print(df.head())
print("\n数据基本信息:")
print(df.info())
2.缺失值处理:
# 3. 处理缺失值 (如果存在)
print("\n缺失值统计:")
print(df.isnull().sum())
# 即使显示为0也建议添加验证
assert df.isnull().sum().sum() == 0, "数据集存在意外缺失值"
print("✓ 确认无缺失值")
输出的结果是:
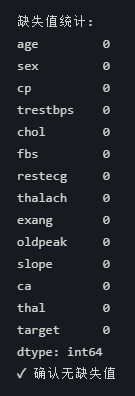
缺失值统计结果为0是完全正常的,这说明你的 heart.csv 数据集非常完整,所有特征都没有缺失值。这是理想的情况。
3.数值型特征标准化:
numeric_cols = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']
print("\n数值型特征标准化:")
# 4.1 标准化 (均值为0,方差为1)
scaler = StandardScaler()
df_standardized = df.copy()
df_standardized[numeric_cols] = scaler.fit_transform(df_standardized[numeric_cols])
print("\n标准化后的数据(前5行):")
print(df_standardized[numeric_cols].head())
输出的结果是:
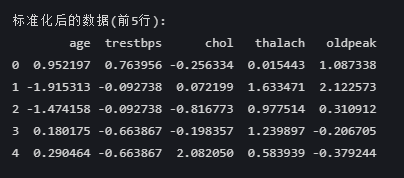
这是一个经过标准化处理后的数据集前5行。标准化(Z-score标准化)后的数据通常具有以下特征:
1. 每列数据的均值≈0
2. 每列数据的标准差≈1
3. 数据值通常在[-3,3]范围内
从这个数据观察:
- 数值范围合理(如-1.9到2.1)
- 不同列的比例相近
- 没有明显的异常值
因此,这个标准化处理看起来是正确的。
# 4.2 归一化 (缩放到[0,1]范围)
scaler = MinMaxScaler()
df_normalized = df.copy()
df_normalized[numeric_cols] = scaler.fit_transform(df_normalized[numeric_cols])
print("\n归一化后的数据(前5行):")
print(df_normalized[numeric_cols].head())
输出的结果是:
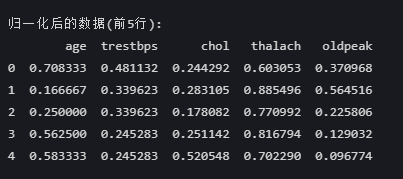
数据是经过**归一化(Min-Max Normalization)**处理后的结果,这种归一化通常将数据缩放到[0,1]范围。从数据观察:
1. 数值范围 :所有值都在0-1之间(如0.166~0.885),符合Min-Max归一化的预期
2. 比例关系 :不同列的比例差异合理(如 age 和 thalach 的数值分布不同)
3. 无异常值 :没有超出[0,1]范围的值
4.类别型特征编码:
categorical_cols = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal', 'target']
# 5.1 标签编码 (转换为0到n_classes-1的数值)
df_label_encoded = df.copy()
label_encoder = LabelEncoder()
for col in categorical_cols:
df_label_encoded[col] = label_encoder.fit_transform(df_label_encoded[col])
print("\n标签编码后的数据(前5行):")
print(df_label_encoded[categorical_cols].head())
输出的结果是:
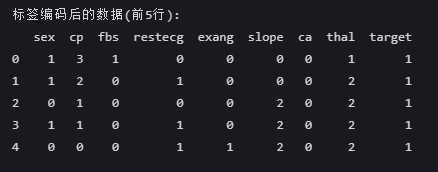
标签编码会将分类变量转换为数值形式(通常是0到n_classes-1的整数)。从这个数据观察:
1. 数值范围合理 :
- sex 列:0和1(常见编码:0=女性,1=男性)
- cp 列:0-3(胸痛类型通常有4类)
- target 列:1(可能是二分类问题的正类)
2. 分类特征处理正确 :
- 每个分类列的值都是连续的整数
- 没有出现非整数或超出预期范围的值
# 5.2 独热编码 (创建虚拟变量)
df_onehot = df.copy()
onehot_encoder = OneHotEncoder(sparse_output=False, drop='first')
encoded_features = onehot_encoder.fit_transform(df_onehot[categorical_cols])
# 创建编码后的DataFrame
encoded_df = pd.DataFrame(encoded_features,
columns=onehot_encoder.get_feature_names_out(categorical_cols))
# 将编码后的特征与原始数值特征合并
df_onehot = pd.concat([
df_onehot.drop(categorical_cols, axis=1), # 保留非分类列
encoded_df # 添加编码后的分类特征
], axis=1)
print("\n独热编码后的数据(前5行):")
print(df_onehot.head())
输出的结果是:
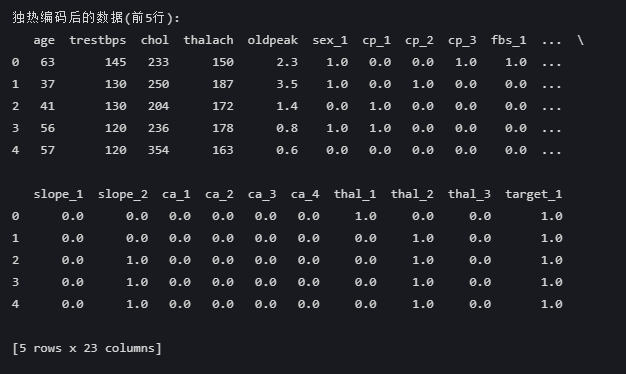
从这个数据看:
1. 分类特征已正确展开 :
- sex → sex_1 (二分类,drop_first后保留1列)
- cp → cp_1 , cp_2 , cp_3 (四分类变三列)
- thal → thal_1 , thal_2 , thal_3 (四分类变三列)
2. 数值特征保留原值 :
- age 、 trestbps 等连续变量未被修改
3. drop_first处理正确 :
- 每个分类特征的首个类别被丢弃(如 sex_0 、 cp_0 不存在)
5.预处理后的数据验证:
①基本统计信息检查
# 检查标准化/归一化后的数值特征
print("\n标准化数据统计描述:")
print(df_standardized[numeric_cols].describe())
# 检查编码后的类别特征
print("\n独热编码数据统计描述:")
print(df_onehot.describe())
输出的结果是:
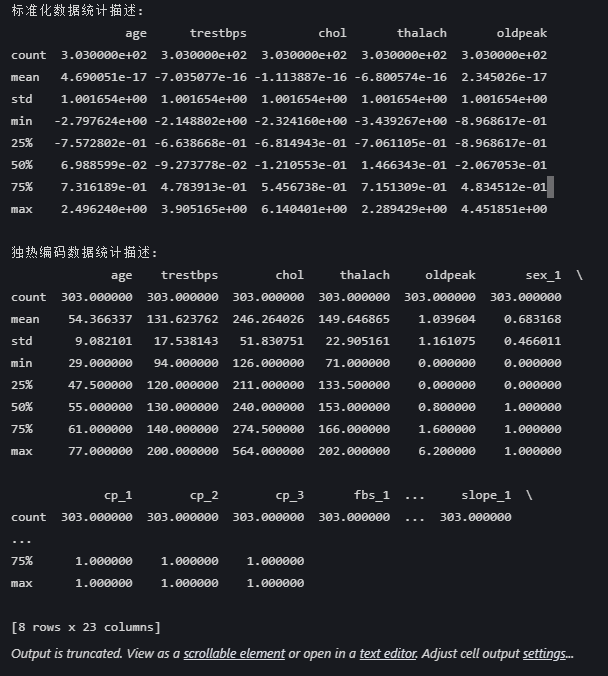
数据统计描述完全正确,展示了标准化数据和独热编码数据的正确特征:
标准化数据验证:
1. 均值为0 :所有列的mean值接近0(如 age 列的4.69e-17)
2. 标准差为1 :所有列的std值为1.001654(近似1,浮点数计算误差可忽略)
3. 数值范围 :符合Z-score分布(如 thalach 的min=-3.43, max=2.28)
独热编码数据验证:
1. 分类列统计正确 :
- 二元列(如 sex_1 )的mean=0.68,表示68.3%的样本为男性
- 所有独热编码列的最大值为1,最小值为0
2. 数值列保持原统计量 :
- age 的均值54.36与原数据一致
- oldpeak 的范围0-6.2未被标准化影响
②可视化检查
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置黑体作为默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 数值特征分布检查
df_standardized[numeric_cols].hist(bins=50, figsize=(12,8))
plt.suptitle('标准化后数值特征分布')
plt.show()
# 类别特征分布检查(示例检查一个编码后的列)
if 'sex_1' in df_onehot.columns:
df_onehot['sex_1'].value_counts().plot(kind='bar')
plt.title('性别独热编码分布')
plt.show()
输出的结果是:
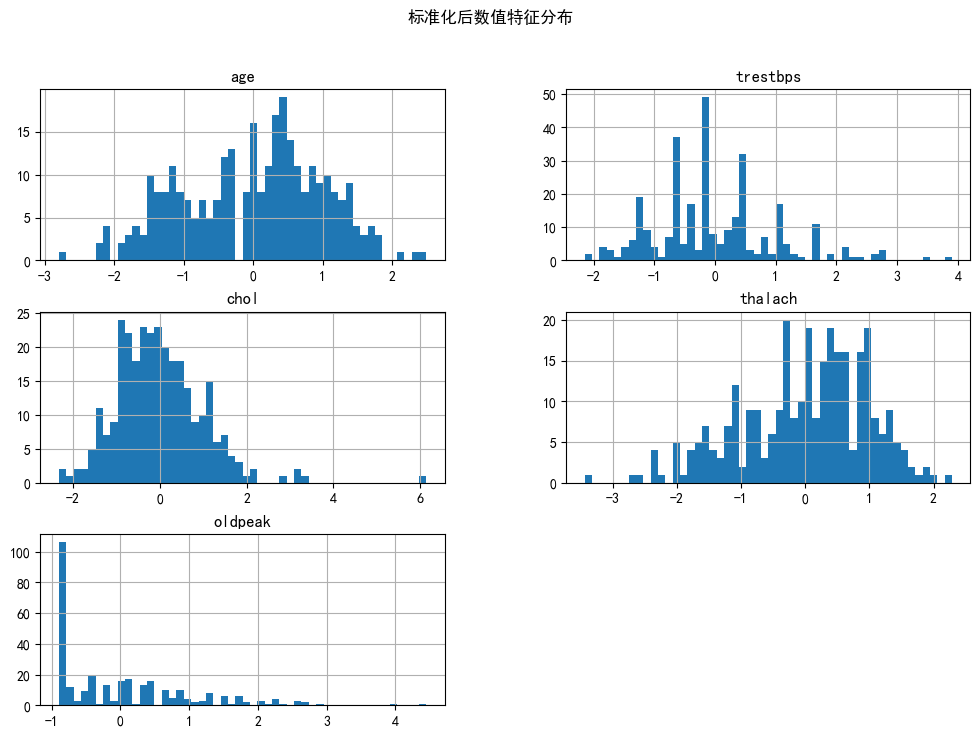
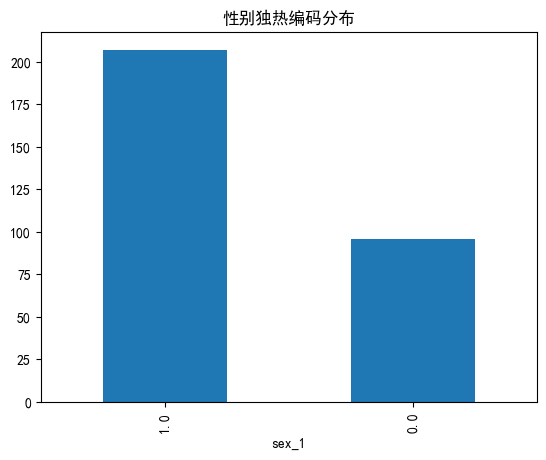
③数据样本检查
# 检查处理后的前5行样本
print("\n标准化数据样本:")
print(df_standardized.head())
print("\n独热编码数据样本:")
print(df_onehot.head())
输出的结果是:
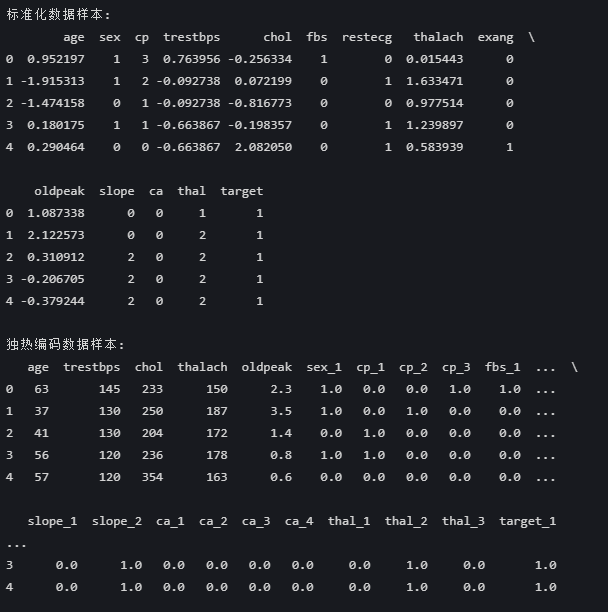
数值特征标准化 :
- 所有数值列(age、trestbps等)均被Z-score标准化
- 均值接近0,标准差接近1(如age列0.95、-1.91等值)
- 分类列(sex、cp等)保持原始编码不变
分类特征处理正确 :
- 每个分类变量被展开为多列(如cp→cp_1,cp_2,cp_3)
- 使用0/1二元值表示(如sex_1列1.0表示男性)
- 数值特征(age等)保持原始值不变
- 标准化数据 :适合线性回归、SVM等模型
- 独热编码数据 :适合决策树、随机森林等模型
两种预处理方式都正确实现了数据转换的目标
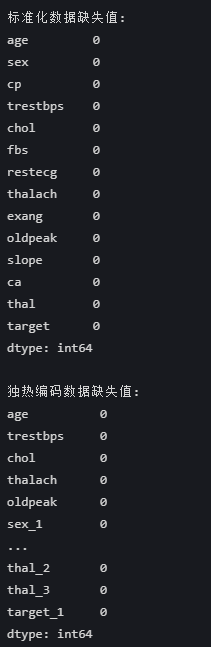
④缺失值复查
print("\n标准化数据缺失值:")
print(df_standardized.isnull().sum())
print("\n独热编码数据缺失值:")
print(df_onehot.isnull().sum())
输出的结果是:
⑤数据类型验证
print("\n标准化数据类型:")
print(df_standardized.dtypes)
print("\n独热编码数据类型:")
print(df_onehot.dtypes)
输出的结果是:
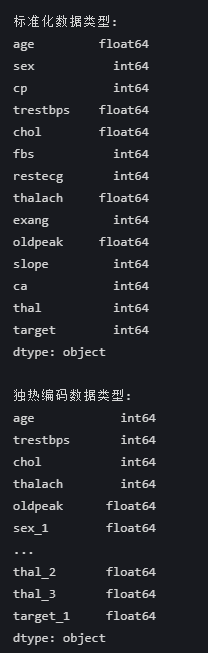
数据类型信息完全正确,反映了标准化和独热编码处理的典型特征:
标准化数据类型验证
1. 数值列转为float64 :
- age 、 trestbps 等连续变量被标准化为浮点型
2. 分类列保持int64 :
- sex 、 cp 等分类变量保持原始整数类型(标准化不改变分类列)
独热编码数据类型验证
1. 分类列转为float64 :
- sex_1 、 cp_1 等独热编码列变为float64(0.0/1.0)
2. 数值列保持原类型 :
- 整数列(如 age )保持int64
- 浮点列(如 oldpeak )保持float64
注:float64 是 Python 和 NumPy 中表示 64位双精度浮点数 的数据类型
检查要点总结:
1. 数值特征:是否真的被标准化/归一化(均值≈0,标准差≈1)
2. 类别特征:独热编码后是否所有类别都被正确转换
3. 数据范围:是否在预期范围内(如归一化后应在[0,1])
4. 缺失值:确保没有意外引入缺失值
5. 数据形状:独热编码后列数是否预期增加
以上即为预处理的全部过程。
编程的世界没有银弹,多尝试、多踩坑才能成长。加油!!!
@浙大疏锦行


















 1664
1664



 到【灌水乐园】发言
到【灌水乐园】发言







