




目录
三、为什么不建议将超大 JSON / 图结构数据作为 Redis 主存储
四、为何 MongoDB 更适合作为大 JSON / 图结构数据的主存储
五、推荐架构:MongoDB 主存储 + Redis 分层缓存
🌟 MongoDB is the right database.
🌟 Redis is an optional accelerator, not a storage engine.
七、总结:不要用“最快的数据库”,去解决“最不适合它的问题”
干货分享,感谢您的阅读!
在业务系统中,我们常常需要管理 体积庞大、结构复杂、更新频率低但读取频繁 的 JSON 数据。例如:
-
大型流程图定义(Graph Schema)
-
AI 对话流程图(Node + Edge)
-
业务配置图谱
-
多节点、属性复杂的 JSON 配置树
这些数据往往几十 KB 到数 MB,不适合作为结构化表数据拆解,而是以整体文档形式进行存储、更新和查询。
如何在读流量大、性能要求高、数据规模不断增长的场景中合理选择存储方案?固然会先想到 Redis 与 MongoDB 。

我们从架构、性能、成本、扩展性等多个维度对 Redis 与 MongoDB 进行深度对比,并给出最终选型策略。
一、业务背景与需求分析
在生产系统中,典型需求包括:
(一)数据特征
-
单文档体量大:几十 KB ~ 1MB+
-
结构嵌套深:节点、边、属性形式的树/图结构
-
更新频率低:配置类数据通常“写少读多”
-
读非常频繁:每次流程执行、任务触发都依赖该数据
-
按主键查询为主:通常是
id或biz_code
(二)技术目标
-
高频读取时仍需保持 低延迟 和 高吞吐
-
避免业务数据库压力
-
数据规模未来可能继续增长
-
具备良好的可维护性、扩展性和成本控制能力
在这种情况下,一般不会选择本地缓存(难以跨服务共享、极大 JSON 占内存、更新同步困难),真正需要权衡的是 Redis 和 MongoDB。
(三)为什么不建议放本地缓存?
Java 后端 JVM 内存是有限的。如果一个图的 JSON 是几十 KB ~ 几百 KB,多个业务就可能是几百 MB,一旦 GC 压力大,会导致:
-
Full GC 变频繁
-
延迟飙升
-
服务重启时缓存丢失
-
多实例部署时缓存不一致
并且在实际环境中,你肯定是多副本部署(k8s / 云环境)。每个实例本地缓存一份 → 不一致、难同步,如果想避免这些问题本身也要额外去承担实时更新维护的成本。
二、Redis vs MongoDB:技术能力深度对比
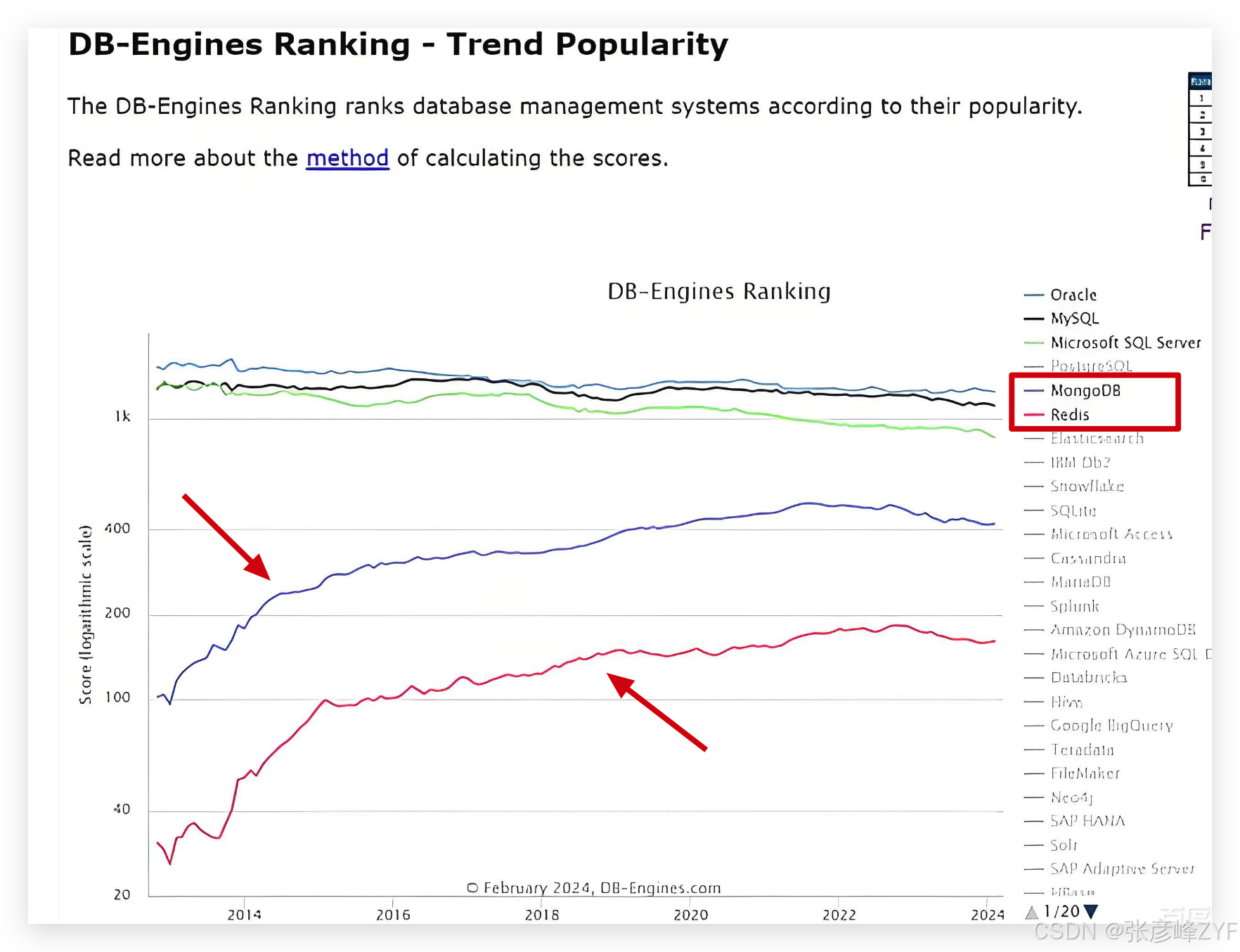
(一)架构层面对比
| 能力项 | Redis | MongoDB |
|---|---|---|
| 存储类型 | 内存数据库 | 文档数据库(内存 + 磁盘) |
| 适用内容 | 缓存、会话、计数、KV 数据 | 大 JSON 文档、结构化配置、查询类数据 |
| 数据持久化 | 可选 RDB/AOF,但以内存为主 | 原生持久化(WiredTiger 引擎) |
| 数据模型 | Key-Value | BSON 文档(复杂结构支持极好) |
MongoDB 更适合存 大 JSON 文档 和复杂结构化内容,Redis 适合 高频短小数据 的极速查询。
(二)性能与延迟对比
1. 吞吐
-
Redis QPS:10万+
-
MongoDB QPS:1万 IOPS 量级(取决于索引、机器)
2. 延迟
| 操作 | Redis | MongoDB |
|---|---|---|
| 读延迟 | 0.1–0.5 ms | 1–5 ms(内存命中) |
| 写延迟 | 0.5–1 ms | 2–10 ms(含写入磁盘 Journal) |
→ 如果追求极致延迟(亚毫秒级),Redis 是更快的。
→ 但对于大型 JSON 文档(几十 KB),Redis 的开销并不比 MongoDB 小,因为 Redis 会:
-
在内存中存全量 JSON 字符串
-
网络传输体积大
-
需要序列化/反序列化(JSON <-> String)
MongoDB 原生 BSON 读写效率更高。
(三)存储与成本对比
Redis 存储成本极高:
-
所有数据驻留内存
-
大 JSON 文档意味着占用大量内存
-
内存成本高(尤其是云上)
举例:存 1GB JSON 数据 → Redis 需 1GB 内存(甚至更多)
MongoDB 更适合大文档:
-
按需加载文档
-
内存缓存(WiredTiger)自动优化
-
更易水平扩容(Shard)
因此在文档规模不断增长时,MongoDB 明显更经济。
(四)可维护性和操作复杂度
| 维度 | Redis | MongoDB |
|---|---|---|
| 数据结构管理 | 需业务手动序列化/反序列化 | 原生 JSON 模型,无需转换 |
| 版本管理 | 需自己编码控制 | 文档天然支持结构演进 |
| 查询能力 | 无查询能力,仅 key 查询 | 丰富查询、索引,非常适合配置类数据 |
| 数据分析 | 不便 | 易于使用管道分析、聚合 |
| 可扩展性 | Cluster 较复杂 | Sharding 相对成熟稳定 |
三、为什么不建议将超大 JSON / 图结构数据作为 Redis 主存储
Redis 的核心定位是内存型 KV / 数据结构引擎,并非文档数据库。当其被用于承载体量大、结构复杂、生命周期长的 JSON 文档时,会在多个关键维度上暴露系统性风险。
(一)内存占用与成本模型不可控
Redis 的数据常驻内存,且存在如下事实:
-
JSON 文档以字符串或字节数组形式整体存储
-
Redis 本身存在对象头、指针、内存碎片等额外开销
-
云环境下内存单价远高于磁盘
在大文档场景中,真实内存消耗通常是:
JSON 原始大小 × 1.3~2.0
当文档规模达到 几十 KB ~ MB 级,并随业务线、版本、历史配置累积时,Redis 内存增长将变得难以预测且难以回收,直接推高整体基础设施成本。
(二)大文档序列化链路放大请求延迟
典型访问路径为:
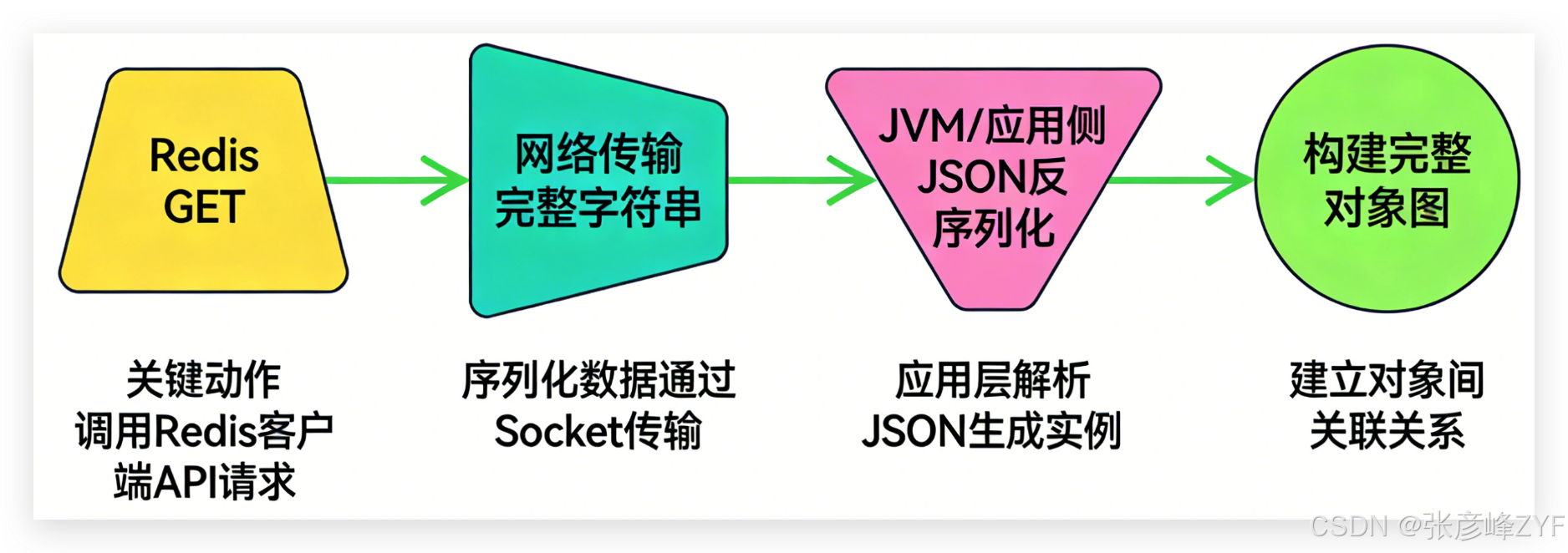
对于大 JSON 文档:
-
网络传输成本线性放大
-
JSON Parse 成本显著(CPU + GC)
-
高并发下容易形成 CPU-bound 瓶颈
这类开销并不会随着 Redis 的“快”而消失,反而在文档体量扩大后成为主导延迟因素。
(三)文档级更新导致一致性与可用性问题
Redis 不具备文档级别的结构更新能力,复杂配置的修改通常意味着:
-
整体覆盖写入
-
并发更新下需额外实现 CAS / 版本控制
-
更新期间存在短暂不一致或读旧数据的风险
在多实例、多业务并发访问的系统中,这类一致性问题会逐渐演化为隐性生产风险。
(四)Redis 无法满足配置型数据的查询与演进需求
当业务逐渐出现以下需求时,Redis 将明显力不从心:
-
按业务维度、类型、状态批量查询
-
查询最近更新、历史版本
-
按配置属性做分析或审计
Redis 只能通过 Key 设计 + 业务侧扫描 曲线救国,但复杂度与维护成本会快速上升,违背系统长期可演进性的基本原则。
四、为何 MongoDB 更适合作为大 JSON / 图结构数据的主存储
MongoDB 的设计目标之一就是高效管理结构复杂、体量较大的文档型数据,在该场景中具备天然优势。
(一)BSON 文档模型与图/流程结构高度契合
MongoDB 的 BSON 模型对以下结构具备一等支持:
-
深度嵌套的 Tree / Graph
-
Node + Edge 关系建模
-
多层属性、可选字段、动态 Schema
无需拆表、无需额外序列化协议,文档结构可直接与业务模型保持高度一致。
(二)在“内存命中”场景下,读性能完全可接受
在典型配置数据场景中:
-
数据访问模式稳定
-
热数据可长期驻留在 WiredTiger Cache
-
单文档按主键查询为主
实际生产中,MongoDB 在内存命中条件下:
-
读延迟通常处于 1~3ms
-
吞吐能力足以支撑高频配置读取场景
对于流程执行、策略决策等业务,这一延迟水平通常不是系统瓶颈。
(三)原生支持索引、查询与结构演进
MongoDB 提供:
-
多字段索引
-
范围查询、排序
-
聚合管道(用于配置分析)
同时,文档 Schema 可自然演进:
-
新字段向后兼容
-
老文档无需强制迁移
-
非侵入式支持版本升级
这使其非常适合作为长期演进的配置与图数据存储。
(四)成本结构更符合数据增长曲线
MongoDB 的数据以磁盘为主,内存作为缓存:
-
大规模数据不会线性推高内存成本
-
磁盘扩展成本远低于内存
-
Sharding 能够自然支撑规模增长
从长期 TCO(Total Cost of Ownership)角度看,更适合承载“体量不断增长”的文档数据。
五、推荐架构:MongoDB 主存储 + Redis 分层缓存
在大 JSON / 图结构数据场景中,更合理的架构是职责清晰的分层设计。
(一)架构角色划分
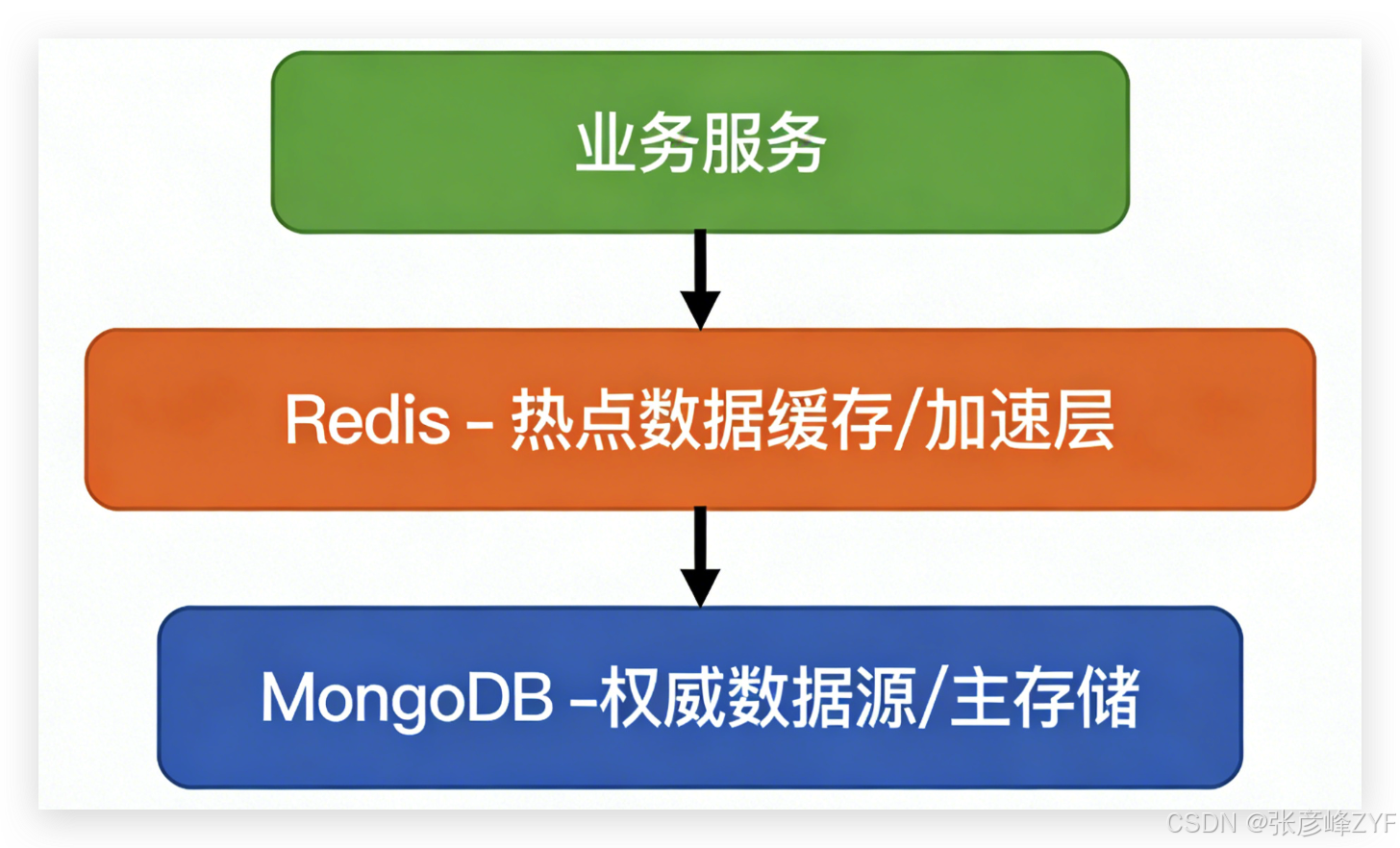
核心原则:
-
MongoDB 永远是最终一致的事实来源
-
Redis 只缓存访问频率极高、体量可控的数据
-
Redis 中的数据可以被安全地丢弃和重建
(二)Redis 的合理使用边界
Redis 更适合用于:
-
当前活跃流程图
-
热点业务配置
-
短周期、高频访问的数据子集
而不是:
-
全量图数据
-
历史配置
-
冷数据或低频访问文档
(三)架构收益总结
该架构能够同时满足:
-
性能:热点路径亚毫秒级访问
-
成本:大数据量落盘,避免内存爆炸
-
可维护性:数据模型清晰、职责单一
-
扩展性:天然支持数据规模与业务复杂度增长
六、决策结论
(一)基本准则
✔ 若数据大(>50KB),结构复杂,查询频繁
→ MongoDB 是最佳主存储
✔ 若追求极致低延迟(0.x 毫秒)且数据较小
→ 可用 Redis 做缓存,但不作主存储
✔ 若数据未来会指数级增长
→ 更应选择 MongoDB,存储成本更可控
✔ 若业务未来需要数据查询、分析、索引
→ MongoDB 远优于 Redis
(二)两句常识
对于“巨大 JSON 图数据”这种典型 配置型、结构化、高频读取、低频写入 的数据场景:
🌟 MongoDB is the right database.
🌟 Redis is an optional accelerator, not a storage engine.
七、总结:不要用“最快的数据库”,去解决“最不适合它的问题”
在系统设计中,技术选型的关键从来不是“谁更快”,而是谁更适合长期承担这类数据的职责。
- Redis 很快,但它擅长的是小而热、短生命周期、可随时丢弃的数据;
- MongoDB 不追求极致低延迟,却天生适合体量大、结构复杂、需要长期演进的文档型数据。
当面对巨大 JSON / 图结构配置时,真正需要关注的不是毫秒级差异,而是:
-
成本是否可控
-
架构是否可持续
-
系统是否能随着业务一起增长
因此,将 MongoDB 作为主存储、Redis 作为加速层,并不是折中方案,而是对数据形态和系统边界的尊重。
数据库不是比速度的赛道,而是放对位置的工程决策。
参考阅读与扩展
-
MongoDB 官方文档:Document Model & Schema Design
https://www.mongodb.com/docs/manual/core/data-modeling-introduction/ -
Redis 官方文档:Data Types & Use Cases
https://redis.io/docs/latest/develop/data-types/
-
《Designing Data-Intensive Applications》—— 关于数据模型、缓存、存储引擎取舍的经典著作
-
MongoDB Schema Design Best Practices
https://www.mongodb.com/blog/post/building-with-patterns-a-summary -
Redis Cache Patterns & Anti-Patterns
https://redis.io/docs/latest/develop/use/patterns/



















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











