






缓存能够加快读写速度,也可以降低数据库或者下游接口的压力。
一、缓存穿透
缓存穿透是指某个不存在的key一直被访问,缓存不存在,数据库也不存在数据,请求都直接访问数据库。如果并发高的情况下可能导致数据库宕掉。
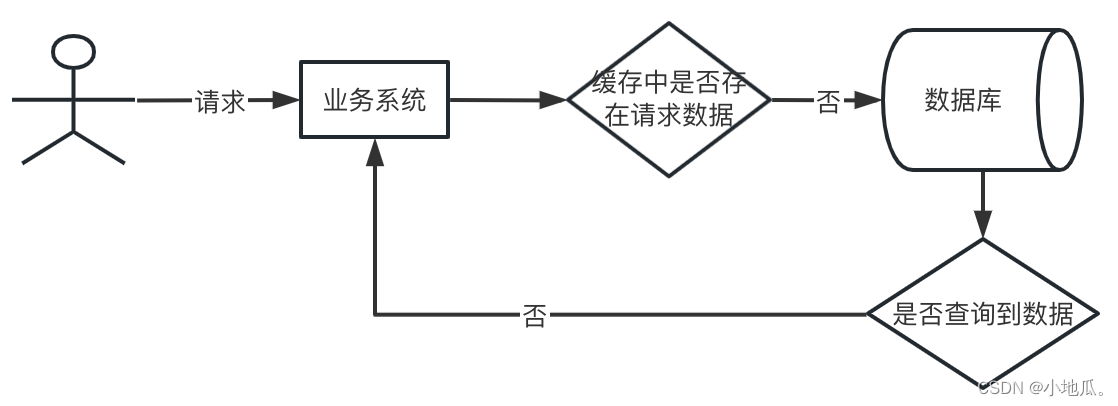
解决方案:
1.缓存空数据:key数据不存在,缓存NULL,设置短一点的过期时间。
2.布隆过滤器:使用布隆过滤器能确定某个key一定不存在或可能存在。可能存在查数据库,一定不存在就返回。适合命中率不高、数据相对固定的场景,缓存空间占用很少。布隆过滤器不能删除数据,删除需要重新初始化。
举例:一个值要放到布隆过滤器内,需要使用多个不同的hash函数生成多个hash值(3个)。比如hello生成3个hash值后的数据位置148变成1。world生成hash返回248,会覆盖hello的48位置的1。
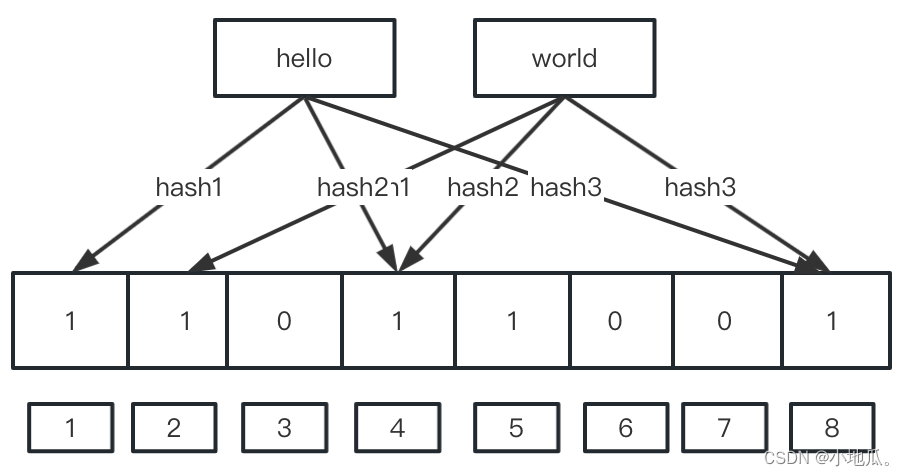
值可能存在的原因:值越多位置为1的多,某个值真实不存在经过多次hash之后位置可能都是1,程序会判断可能存在。
数组长度设置:初始化布隆过滤器设置规则预计元素为N,误差率为m%,根据这两个参数会计算出底层的bit数组大小。预计元素设置过小,查询任何key都会返回存在,误报率变高。预计元素设置过大,会浪费存储空间,效率低。
二、缓存失效(击穿)
大量请求访问同一个key对应的val,这个热点key失效了,直接请求到数据库,数据库瞬间压力过大甚至挂掉。
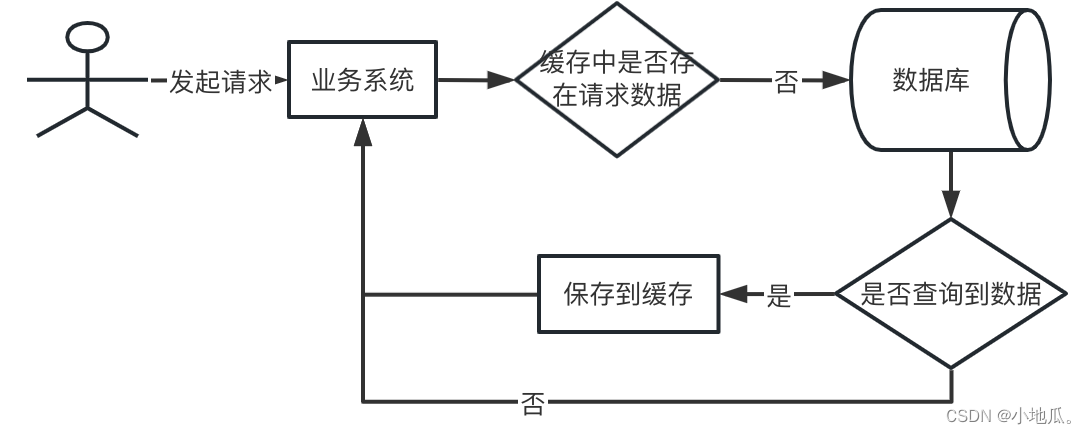
解决方案:
1.针对这种热点数据不设置过期时间。
2.key的数据更新,通过互斥锁的方式更新,先获取分布式锁,获取锁成功去请求数据库读取数据更新到缓存,获取锁失败让请求等待,使用互斥锁会保证数据一致性,可能影响一点效率。
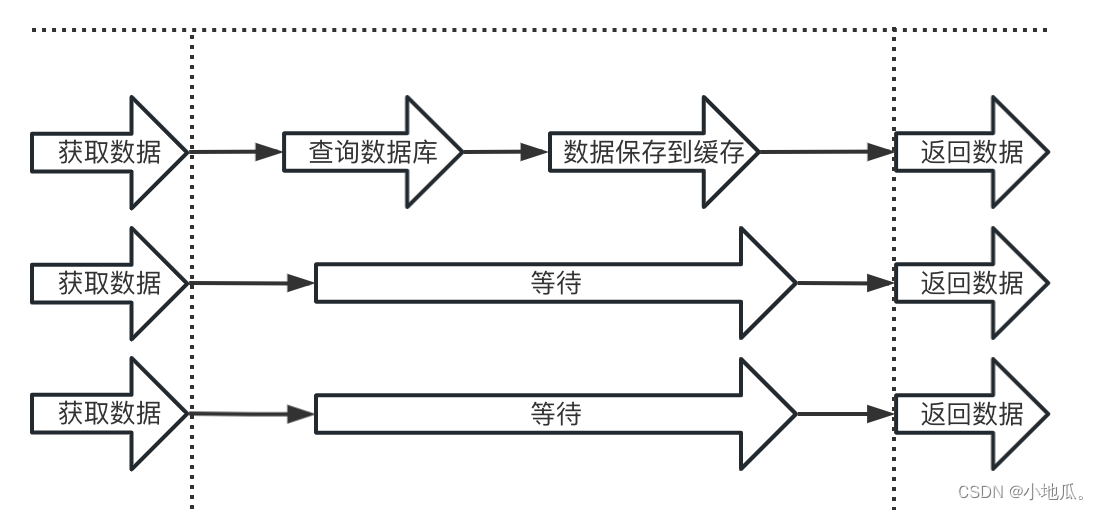
三、缓存雪崩
某个时间节点,大量key失效,导致大量请求在缓存内没有获取到数据,请求都打到数据库,高并发情况下可能导致数据库宕机。

解决方案:
1.随机值:分散key的过期时间,设置key过期时间的时候为过期时间增加随机值。避免因为同样的过期时间导致的缓存雪崩。
2.增加限流:请求的流量达到一定的阈值,直接返回,防止过多请求打到数据库。
四、缓存预热
系统启动的时候把一些缓存预先设置到缓存中,避免用到的时候在去数据库查询。或者增加缓存刷新后台,人工干预。
五、缓存降级
流量突增的情况下,系统根据关键数据自主降级,保证核心系统可用。

















 3505
3505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









