







 本文解析了一个关于Scrapy爬虫中_rules属性错误的问题,通过对比官方文档和自定义Spider代码,发现重写__init__方法未调用父类初始化导致属性缺失,最终修正并分享了解决方案。
本文解析了一个关于Scrapy爬虫中_rules属性错误的问题,通过对比官方文档和自定义Spider代码,发现重写__init__方法未调用父类初始化导致属性缺失,最终修正并分享了解决方案。
按照官方的文档写的demo,只是多了个init函数,最终执行时提示没有_rules这个属性的错误日志如下:
......
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiders\crawl.py", line 82, in _parse_response
for request_or_item in self._requests_to_follow(response):
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiders\crawl.py", line 60, in _requests_to_follow
for n, rule in enumerate(self._rules):
AttributeError: 'TestSpider' object has no attribute '_rules'
出问题的spider代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from newtest.items import NewtestItem
class TestSpider(CrawlSpider):
def __init__(self,*args, **kwargs):
self.headers = {
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Accept-Encoding':'gzip, deflate',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
}
name = 'test'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
rules = (
# Extract links matching 'category.php' (but not matching 'subsection.php')
# and follow links from them (since no callback means follow=True by default).
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = scrapy.Item()
item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
item['name'] = response.xpath('//td[@id="item_name"]/text()').extract()
item['description'] = response.xpath('//td[@id="item_description"]/text()').extract()
return item
后来仔细看了下,跟官方不一样的就是自己重写了init初始化方法,而根据这个提示的日志,应该是覆盖了CrawlSpider的init方法但是没有调用父类的init导致_rules这个属性没有声明导致的。我们来看下CrawlSpider的源码:
所以如果我们的Spider是从CrawlSpider继承过来的,并且自己需要实现__init__ 方法的话,记住要调用父类的__init__方法保障能正常初始化crawlspider的属性。
修改后的代码如下:
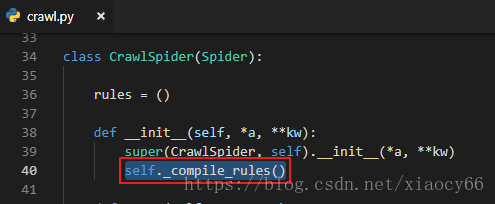
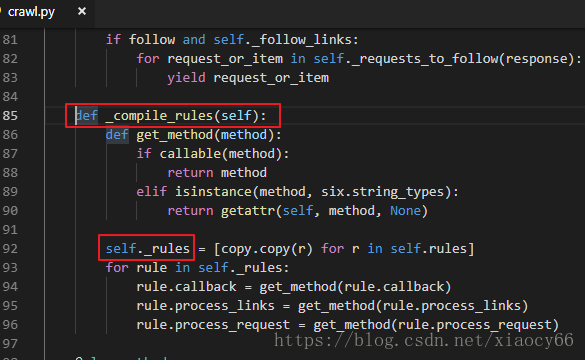
第11行的
super(TestSpider, self).__init__(*args, **kwargs)是关键:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from newtest.items import NewtestItem
class TestSpider(CrawlSpider):
def __init__(self, *args, **kwargs):
super(TestSpider, self).__init__(*args, **kwargs) # 这里是关键
self.headers = {
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Accept-Encoding':'gzip, deflate',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
}
name = 'test'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
rules = (
# Extract links matching 'category.php' (but not matching 'subsection.php')
# and follow links from them (since no callback means follow=True by default).
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = scrapy.Item()
item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
item['name'] = response.xpath('//td[@id="item_name"]/text()').extract()
item['description'] = response.xpath('//td[@id="item_description"]/text()').extract()
return item

















 5141
5141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









