



DOM,即文档对象模型,是一个Javascript的内容交互API。
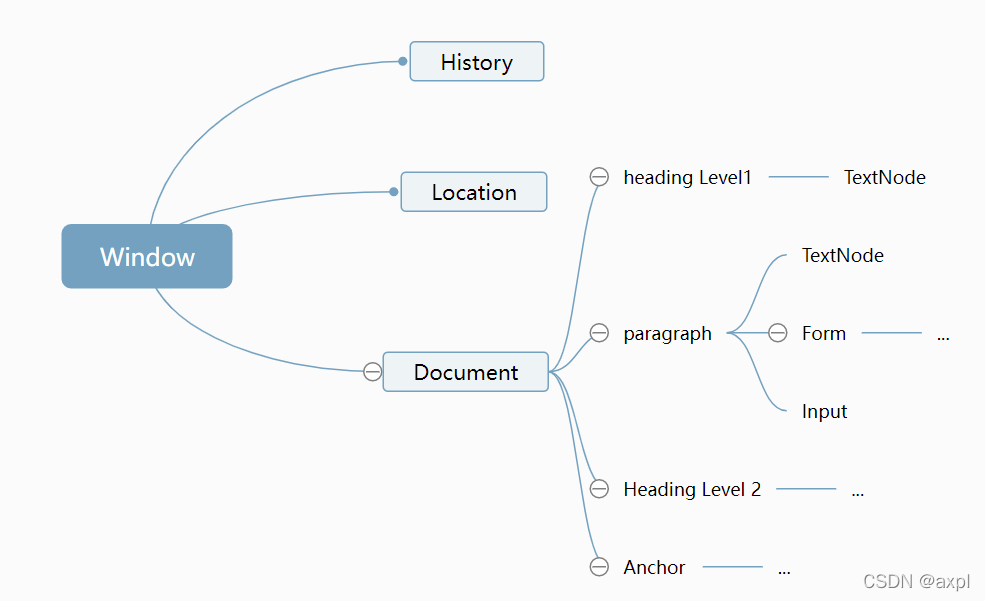
关于DOM,有些知识需要注意:
1. window对象作为全局对象,也就是说你可以通过window来访问全局对象。
-
属性在对象下面以变量的形式存放,在页面上创建的所有全局对象都会变成window对象的属性。
-
方法在对象下面以函数的形式存放,因为左右的函数都存放在window对象下面,所以他们也可以称为方法。
2. DOM为web文档创建带有层级的结果,这些层级是通过node节点组成,这里有几种DOM node类型,最重要的是Element, Text, Document。
-
Element节点在页面里展示的是一个元素,所以如果你有段落元素(),你可以通过这个DOM节点来访问。
-
Text节点在页面里展示的所有文本相关的元素,所以如果你的段落有文本在里面的话,你可以直接通过DOM的Text节点来访问这个文本
-
Document节点代表是整个文档,它是DOM的根节点。
3. 每个引擎对DOM标准的实现有一些轻微的不同。例如,Firefox浏览器使用的Gecko引擎有着很好的实现(尽管没有完全遵守W3C规范),但IE浏览器使用的Trident引擎的实现却不完整而且还有bug,给开发人言带来了很多问题。
如果你正在使用Firefox,我推荐你立即下载Firebug插件,对于你了解DOM结构非常有用。
Web上的JavaScript
Script元素
当你在网站页面上使用JavaScript的时候,需要使用SCRIPT元素:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>JavaScript!</title>
</head>
<body>
<script type="text/javascript">
// <![CDATA[
// ]]>
</script>
</body>
</html>
上述代码,严格来说SCRIPT的TYPE属性应该设置为application/javascript,但是由于IE不支持这个,所以平时我们不得不写成text/javascript或者直接去掉type。另外你也可以看到在SCRIPT元素里的注释行// ,浏览器就不会再解析成XHTML标签了。
DOM正文
访问DOM节点
我们来个例子,一个HTML里包含一段文本和一个无序的列表。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>JavaScript!</title>
</head>
<body>
<p id="intro">My first paragraph...</p>
<ul>
<li>List item 1</li>
<li>List item 1</li>
<li>List item 1</li>
<li>List item 1</li>
<li>List item 1</li>
</ul>
<script type="text/javascript">
// <![CDATA[
// ]]>
</script>
</body>
</html>
上面例子里,我们使用getElementById DOM方法来访问p段落,在SCRIPT里添加如下代码:
var introParagraph = document.getElementById('intro');
// 现在有了该DOM节点,这个DOM节点展示的是该信息段落
变量introParagraph现在已经引用到该DOM节点上了,我们可以对该节点做很多事情,比如查询内容和属性,或者其它任何操作,甚至可以删除它,克隆它,或者将它移到到DOM树的其它节点上。
文档上的任何内容,我们都可以使用JavaScript和DOM API来访问,所以类似地,我们也可以访问上面的无序列表,唯一的问题是该元素没有ID属性,如果ID的话就可以使用相同的方式,或者使用如下getElementsByTagName方式:
var allUnorderedLists = document.getElementsByTagName('ul');
// 'getElementsByTagName'返回的是一个节点集合
// - 和数组有点相似
getElementsByTagName
getElementsByTagName方法返回的是一个节点集合,和数组类似也有length属性,重要的一个特性是他是live的——如果你在该元素里添加一个新的li元素,这个集合就会自动更新,介于他和数组类型,所以可以和访问数组一样的方法来访问,所以从0开始:
// 访问无序列表: [0]索引
var unorderedList = document.getElementsByTagName('ul')[0];
// 获取所有的li集合:
var allListItems = unorderedList.getElementsByTagName('li');
// 循环遍历
for (var i = 0, length = allListItems.length; i < length; i++) {
// 弹出该节点的text内容
alert(allListItems[i].firstChild.data);
}
DOM穿梭
“穿梭”这个词主要是用来描述通过DOM查找节点,DOM API提供了大量的节点属性让我们来往上或者往下查询节点。
所有的节点都有这些属性,都是可以用于访问相关的node节点:
-
Node.childNodes: 访问一个单元素下所有的直接子节点元素,可以是一个可循环的类数组对象。该节点集合可以保护不同的类型的子节点(比如text节点或其他元素节点)。
-
Node.firstChild: 与‘childNodes’数组的第一个项(‘Element.childNodes[0]‘)是同样的效果,仅仅是快捷方式。
-
Node.lastChild: 与‘childNodes’数组的最后一个项(‘Element.childNodes[Element.childNodes.length-1]‘)是同样的效果,仅仅是快捷方式。shortcut.
-
Node.parentNode: 访问当前节点的父节点,父节点只能有一个,祖节点可以用‘Node.parentNode.parentNode’的形式来访问。
-
Node.nextSibling: 访问DOM树上与当前节点同级别的下一个节点。
-
Node.previousSibling: 访问DOM树上与当前节点同级别的上一个节点。
操作元素
在前面,我们提到了DOM节点集合或单个节点的访问步骤,每个DOM节点都包括一个属性集合,大多数的属性都提供为相应的功能提供了抽象。
例如,如果有一个带有ID属性intro的文本元素,你可以很容易地通过DOM API来改变该元素的颜色:
document.getElementById('intro').style.color = '#FF0000';
Node节点
通过DOM API创建内容的时候需要注意node节点的2种类型,一种是元素节点,一种是text节点,上一章节已经列出了所有的节点类型,这两种需要我们现在特别注意。
创建元素可以通过createElement方法,而创建text节点可以使用createTextNode,相应代码如下:
var myIntro = document.getElementById('intro');
// 添加内容
var someText = 'This is the text I want to add';
var textNode = document.createTextNode(someText);
myIntro.appendChild(textNode);

















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









