



让RAG告别断章取义,HiChunk做到了~
- 现有 RAG 评测只关心“检索-生成”两端,对中间的文档怎么切分几乎不测,导致“证据稀疏”场景下好坏难分。
- 腾讯优图提出HiCBench——第一份专门评测“切分质量”的基准,包含人工标注的多级切分点+证据稠密 QA。

- 同时给出HiChunk框架:用微调 LLM 把文档先建成多级语义树,再配一个Auto-Merge 检索算法,动态决定召回哪一层节点。
RAG 的中间层“无人区”
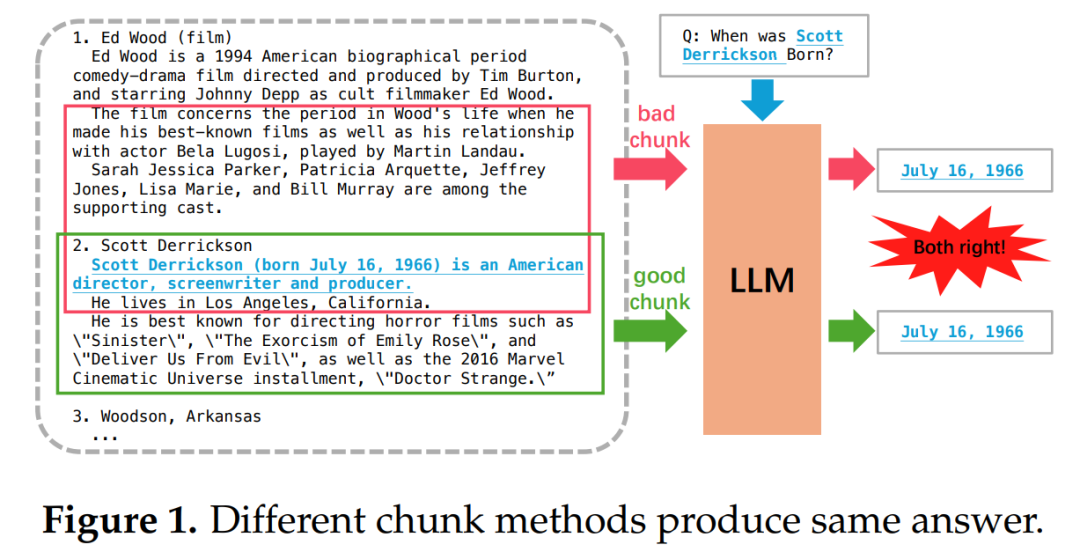 图1:同一段落用不同切分方法可能得到完全一样的 top-chunk,但证据其实被拦腰截断,现有稀疏证据 QA 无法发现。
图1:同一段落用不同切分方法可能得到完全一样的 top-chunk,但证据其实被拦腰截断,现有稀疏证据 QA 无法发现。
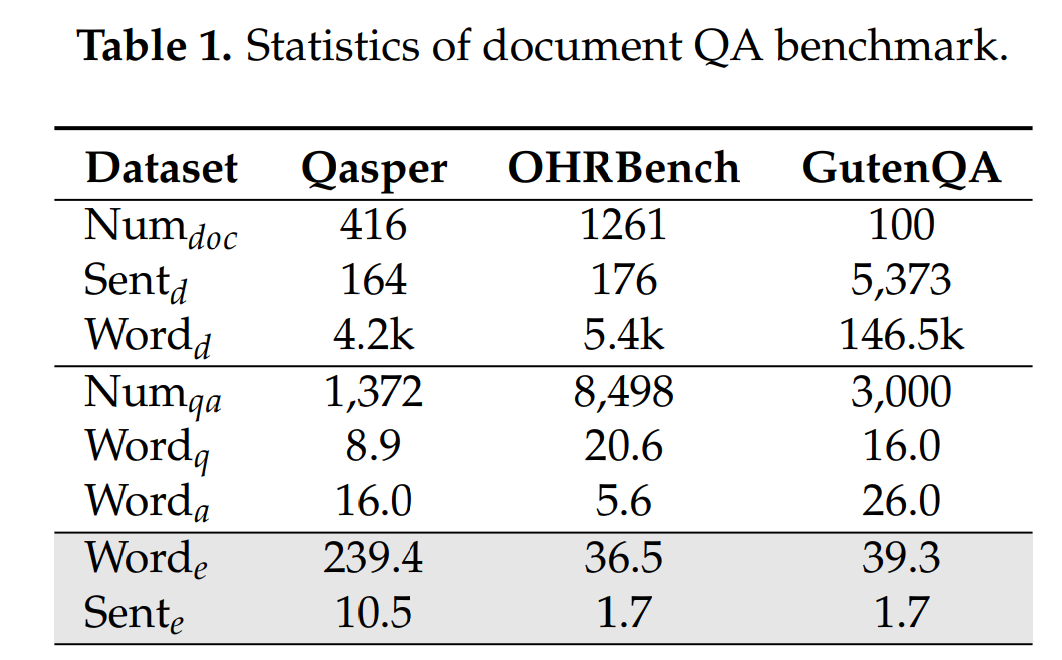
表1:主流 RAG 基准的证据极度稀疏,导致“切得好/切得差”在端到端指标上几乎无差别。
HiCBench:第一份“切分专用”评测
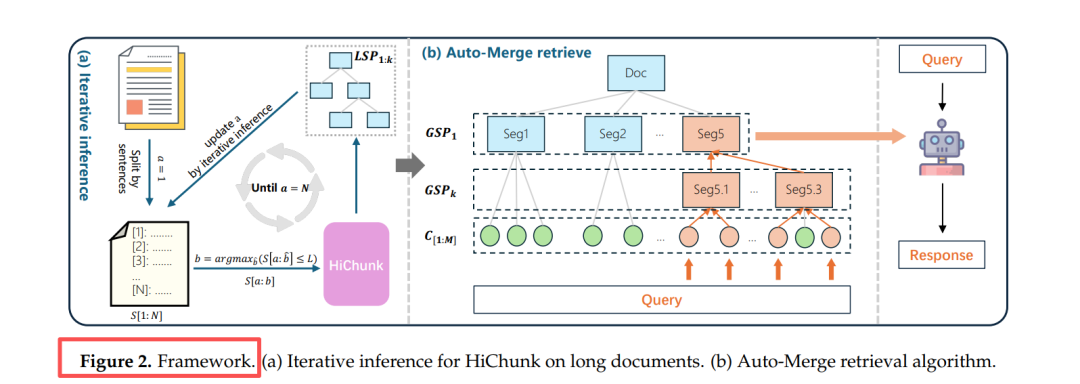 图2:HiCBench 构建流程——先人工标多级结构→再生成证据稠密 QA→保留证据占比≥10% 且 Fact-Cov≥80% 的样本。
图2:HiCBench 构建流程——先人工标多级结构→再生成证据稠密 QA→保留证据占比≥10% 且 Fact-Cov≥80% 的样本。
三种任务类型
| 类型 | 证据分布 | 用途 |
|---|---|---|
| T0 证据稀疏 | 1-2 句 | 模拟传统场景 |
| T1 单块证据稠密 | 同一语义块 512-4 096 词 | 考核“块内完整” |
| T2 多块证据稠密 | 跨 2+ 语义块 256-2 048 词/块 | 考核“跨块召回” |
关键数字
- 130 篇长文(平均 8.5 k 词)
- 1 200 人工标注多级切分点
- (659 T1 + 541 T2) QA 对,平均证据句 20+
HiChunk:把文档建成“可伸缩”的树
两级子任务
- 切分点检测:在哪句断开?
- 层级分配:这段属于 L1/L2/…/Lk?
用指令微调的 4 B 小模型(Qwen3-4B)直接生成“<sent_i> 是 L2 标题”式文本,统一解决。
超长文档怎么办?
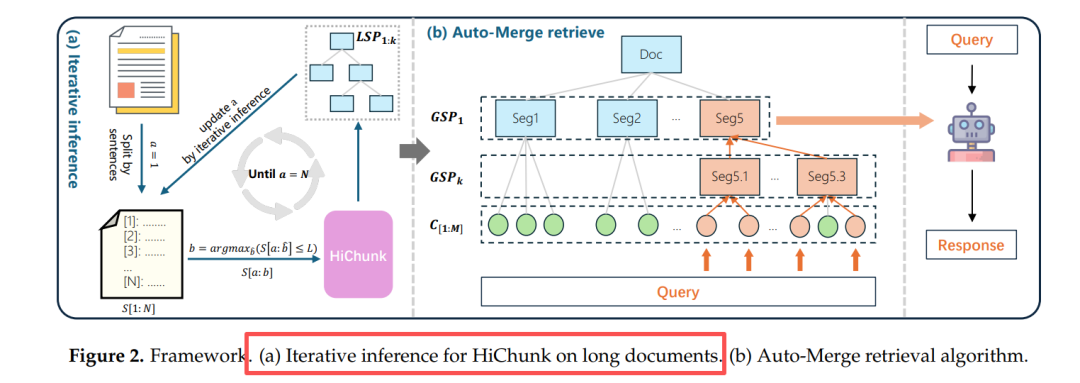 图2(a) 迭代推理:每次只看 8 k token,滑动窗口产生局部切分点,再 Merge 到全局树,解决“层次漂移”。
图2(a) 迭代推理:每次只看 8 k token,滑动窗口产生局部切分点,再 Merge 到全局树,解决“层次漂移”。
Auto-Merge:检索时自动“拼积木”
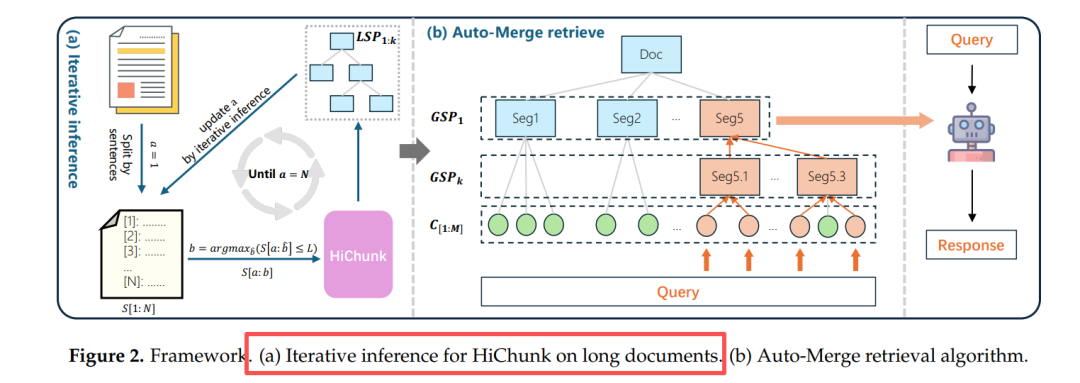 图2(b) Auto-Merge:按 token 预算 T 动态决定“子节点→父节点”是否上卷,保证语义完整又不爆长度。
图2(b) Auto-Merge:按 token 预算 T 动态决定“子节点→父节点”是否上卷,保证语义完整又不爆长度。
合并条件(同时满足):
- 已召回兄弟节点 ≥2
- 兄弟累计长度 ≥ θ*(随已用 token 自适应增长)
- 剩余预算足够装入父节点

怎么从这棵树里召回最合适的一段
实验结果
切分准确率
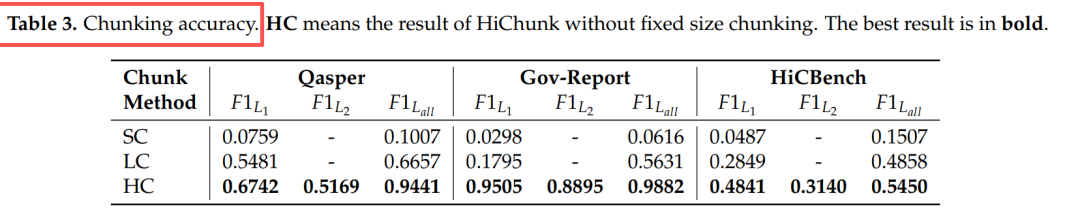
- 表3:HiChunk 在域内/域外均显著优于语义相似度或 LLM 单级切分。*
端到端 RAG(Qwen3-32B)
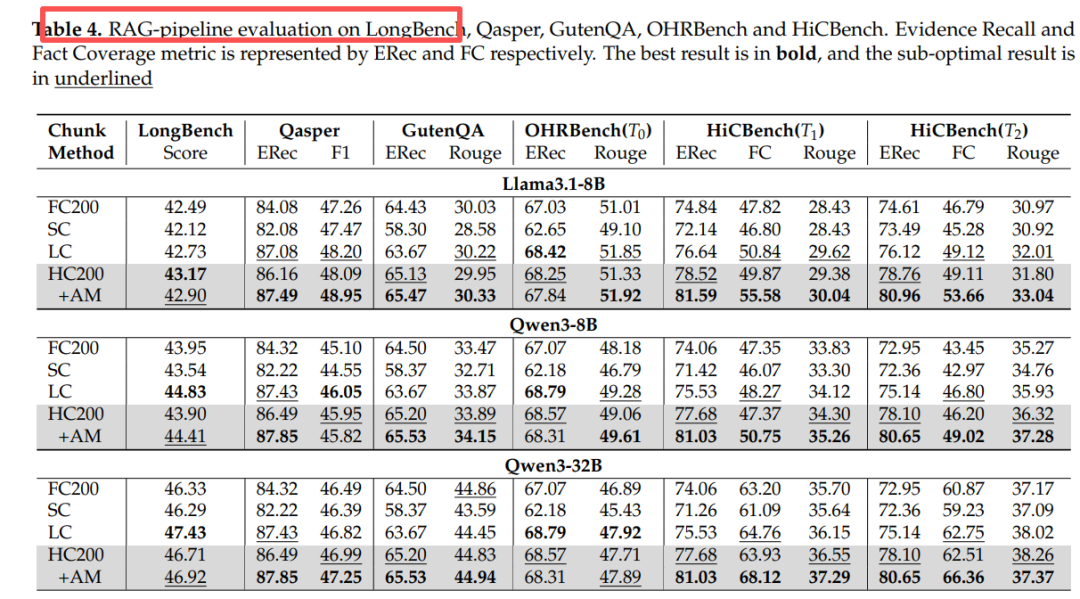 表4:证据越稠密,HC200+AM 优势越大;在稀疏数据集(GutenQA、OHRBench)上与基线持平,证明“不伤害”原有能力。
表4:证据越稠密,HC200+AM 优势越大;在稀疏数据集(GutenQA、OHRBench)上与基线持平,证明“不伤害”原有能力。
token 预算影响
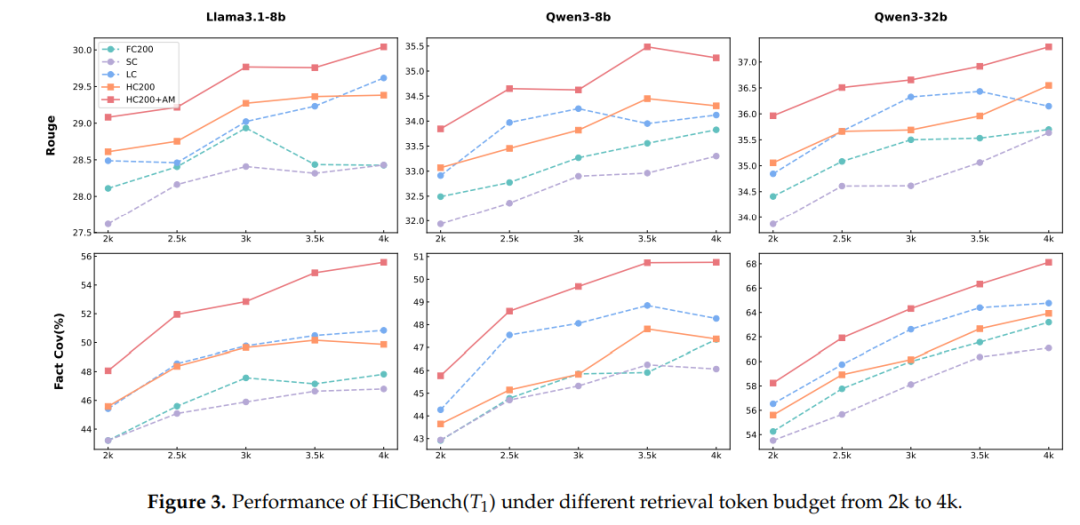
图3:2 k→4 k token 预算下,HC200+AM 的 Rouge、Fact-Cov 全程高于其他切分策略。
最大层级消融
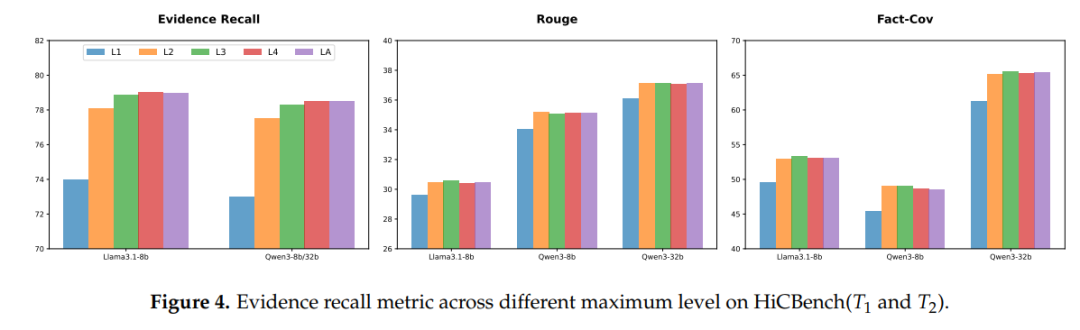
图4:只保留 L1 时证据召回掉 8%+;L3 后收益饱和,建议默认 3 级。
耗时
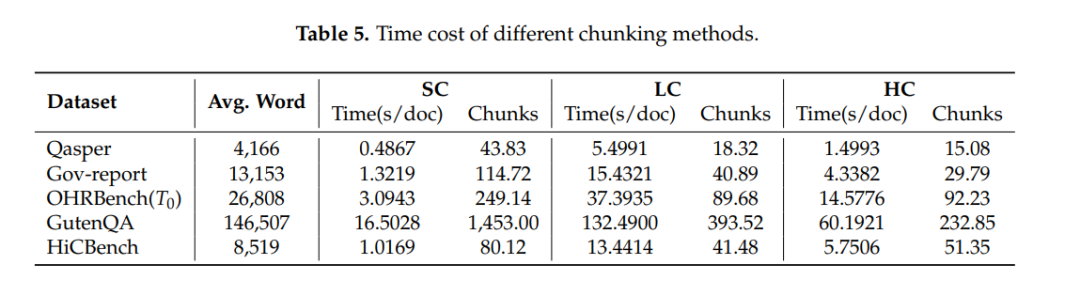
表5:HC 在保证最高质量的同时,速度是 LC 的 2×+ 快,可在线部署。
https://arxiv.org/pdf/2509.11552
HiChunk: Evaluating and Enhancing Retrieval-Augmented Generation with Hierarchical Chunking
Code: https://github.com/TencentCloudADP/HiChunk.git
Data: https://huggingface.co/datasets/Youtu-RAG/HiCBench
每天一篇大模型Paper来锻炼我们的思维已经读到这了,不妨点个👍、❤️、↗️三连,加个星标⭐,不迷路哦
大模型教程:https://blog.youkuaiyun.com/python1222_/article/details/153068612?spm=1011.2415.3001.5331


















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









