



 本文深入分析2012年美国总统竞选赞助数据,涵盖数据载入、预处理、清洗、聚合及时间序列分析,揭示两党资金来源差异。
本文深入分析2012年美国总统竞选赞助数据,涵盖数据载入、预处理、清洗、聚合及时间序列分析,揭示两党资金来源差异。

1、数据载入和总览
1.1数据来源
数据来源于阿里云天池公共数据-pandas实践-2012美国总统竞选赞助数据分析,如图所示
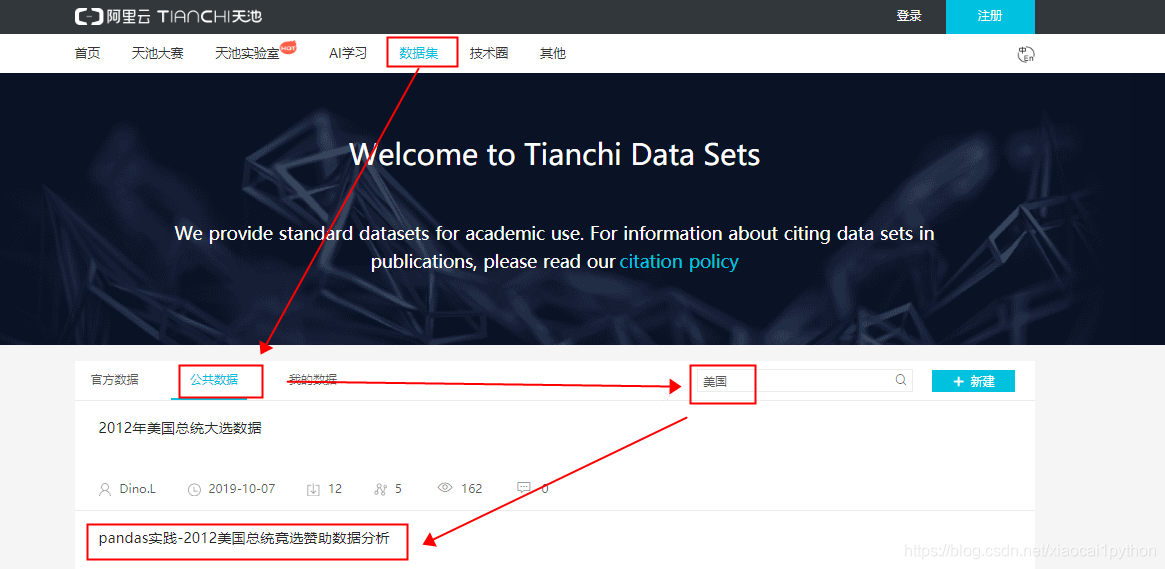
然后下载数据并保存到本地,最后读取(本次操作使用工具-jupyter notebook)
1.2数据载入(pd.read_csv)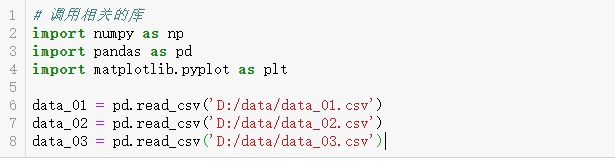 1.3数据合并(pd.concat())
1.3数据合并(pd.concat())
pd.concat()可以沿着一条轴将多个对象堆叠到一起,这里我们要把data_01.csv/data_02.csv/data_03.csv三份数据集合并为一份数据进行分析
pd.concat(objs, axis=0, join=‘outer’)
objs——合并对象
axis——默认是按0轴合并,即按列合并;aixs为1,即按行合并
join——默认join=‘outer’,还有一个可取的值是’inner’
各字段的含义:
cand_nm – 接受捐赠的候选人姓名
contbr_nm – 捐赠人姓名
contbr_st – 捐赠人所在州
contbr_employer – 捐赠人所在公司
contbr_occupation – 捐赠人职业
contb_receipt_amt – 捐赠数额(美元)
contb_receipt_dt – 收到捐款的日期
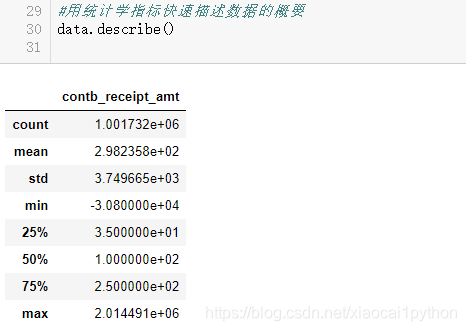
1.4 数据预览和基本统计分析
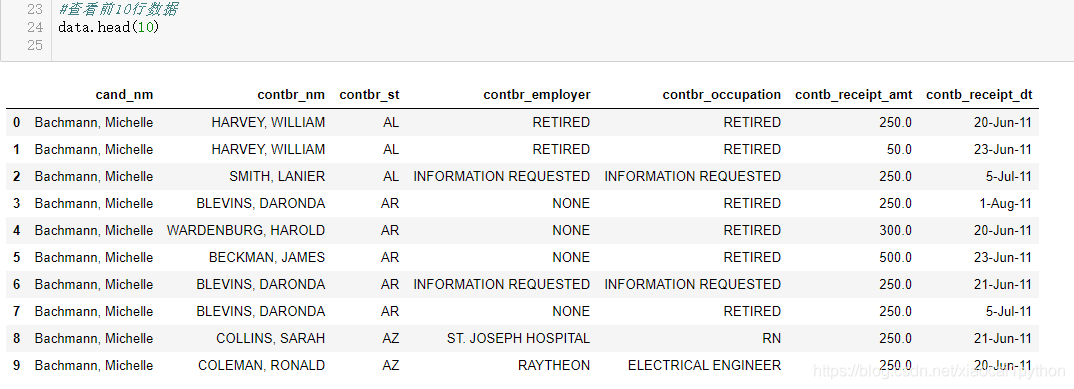
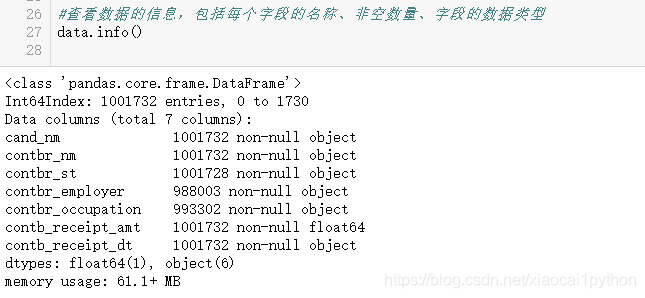
2、 数据清洗
2.1 缺失值处理 2.2 数据转换
2.2 数据转换
利用字典映射进行转换:党派分析
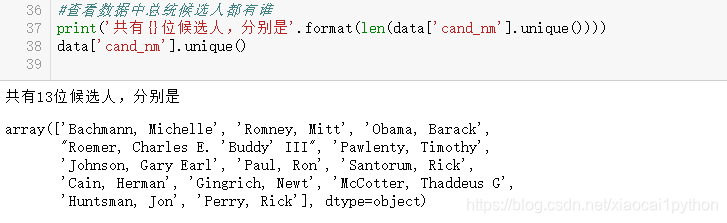
美国大选一般是民主党和共和党之争,虽然数据中没有党派这个字段,但是通过候选人名称即cand_nm,可以得到对应的党派信息

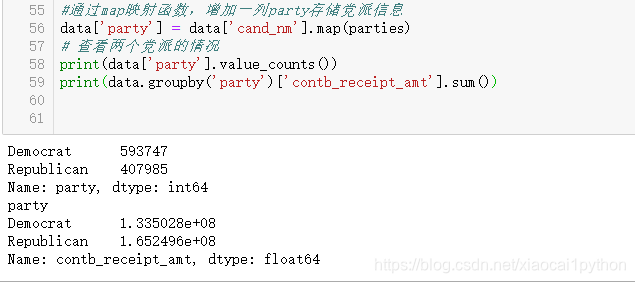
增加一列party存储党派信息
 pandas中的value_counts()可以对Series里面的每个值进行计数并且
pandas中的value_counts()可以对Series里面的每个值进行计数并且
排序,默认为降序
可以看出Republican(共和党)接受的赞助总金额更高,Democrat(民主党)获得的赞助次数更多一些
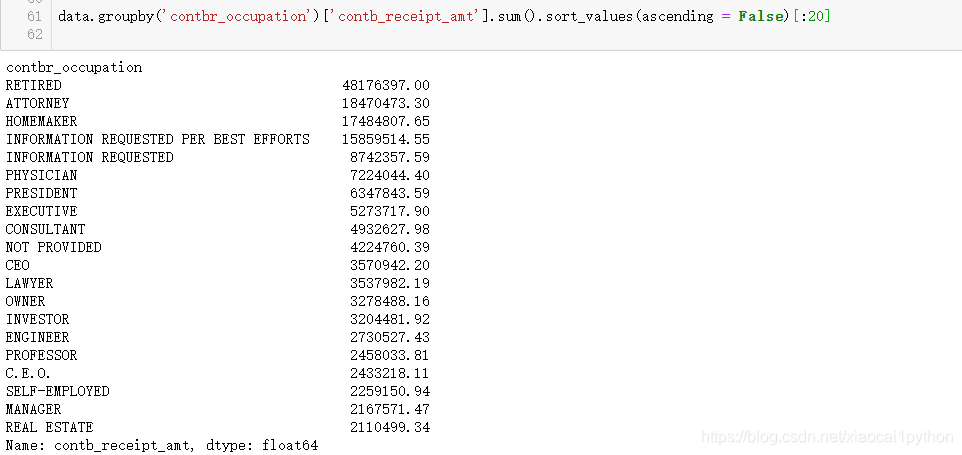
排序:按照职业汇总对赞助总金额进行排序
按照职位进行汇总,计算赞助总金额,展示前20项,发现不少职业是相同的,只不过是表达不一样而已,如C.E.O.与CEO,都是一个职业
利用函数进行数据转换:职业与雇主信息分析
许多职业都涉及相同的基本工作类型,下面我们来清理一下这样的数据(这里巧妙地利用了dict.get它允许没有映射关系的职业也能“通过”)

同样地,对雇主信息进行类似转换

2.3 数据筛选
赞助金额筛选
赞助包括退款(负的出资额),为了简化分析过程,我们限定数据集只有正出资额

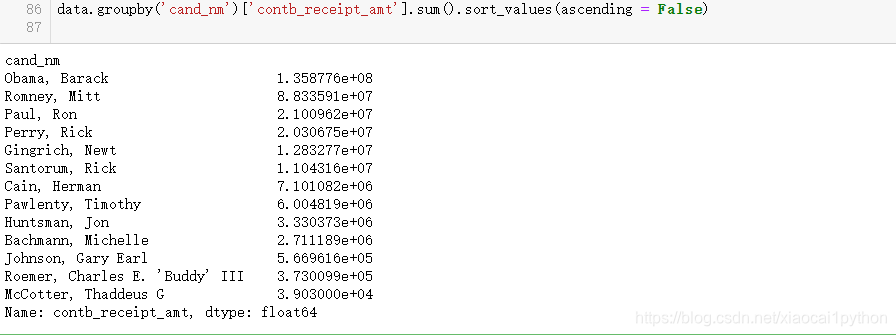
候选人筛选(Obama、Romney)
从下面可以卡出,赞助基本集中在Obama、Romney之间,为了更好的聚焦在两者间的竞争,我们选取这两位候选人的数据子集作进一步分析

copy方法,.copy()返回data的浅拷贝
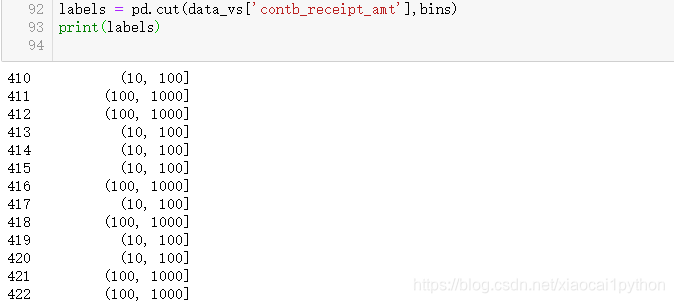
2.4 面元化数据
接下来我们对该数据做另一种非常实用的分析,利用cut函数根据出资额大小将数据离散化到多个面元中:
3. 数据聚合与分组运算
分组计算Grouping,分组运算是一个“split-apply-combine”的过程(拆分-应用-合并)
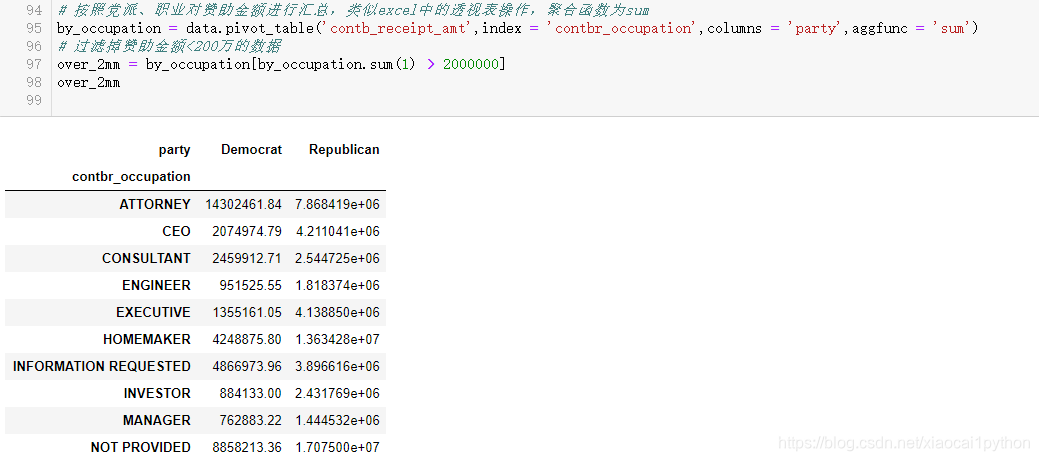
3.1 透视表(pivot_table)分析党派和职业
我们可以通过pivot_table根据党派和职业对数据进行聚合,然后过滤掉总出资不足200万美元的数据:

3.2 分组级运算和转换
根据职业与雇主信息分组运算
我们接下来了解一下对Obama和Romney总出资最高的职业和雇主。
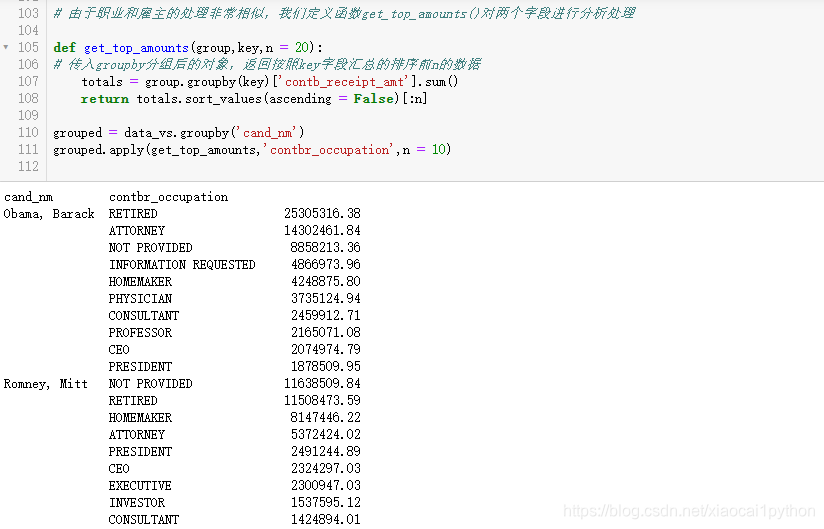
从数据可以看出,Obama更受精英群体(律师、医生、咨询顾问)的欢迎,Romney则得到更多企业家或企业高管的支持
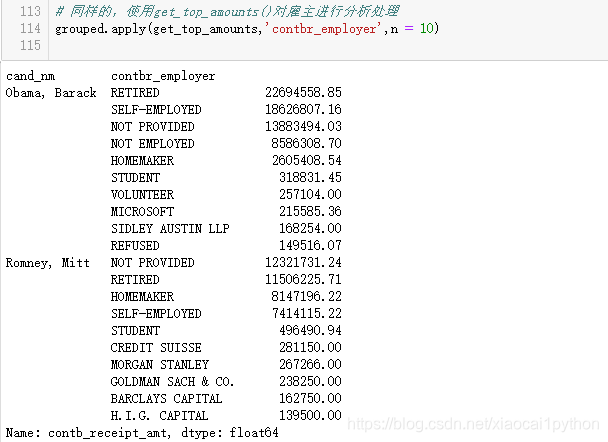
Obama:微软、盛德国际律师事务所; Romney:瑞士瑞信银行、摩根斯坦利、高盛公司、巴克莱资本、H.I.G.资本
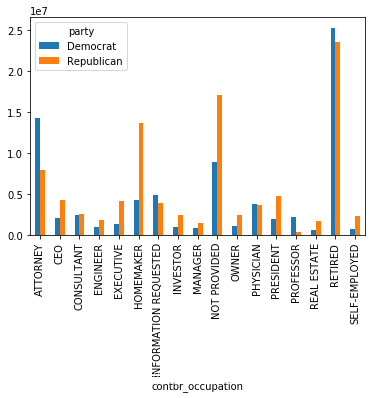
对赞助金额进行分组分析(matplotlib画图)
前面我们已经利用pd.cut()函数,根据出资额大小将数据离散化到多个面元中,接下来我们就要对每个离散化的面元进行分组分析
首先统计各出资区间的赞助笔数,这里用到unstack(),stack()函数是堆叠,unstack()函数就是不要堆叠,即把多层索引变为表格数据
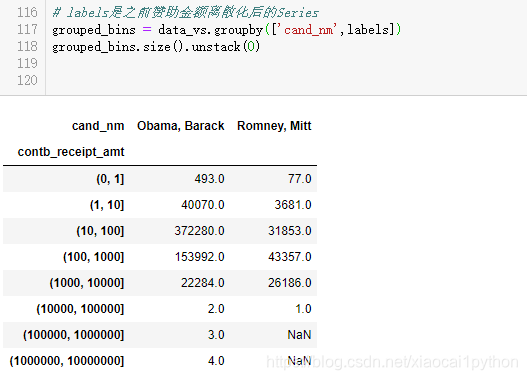
接下来,我们再统计各区间的赞助金额
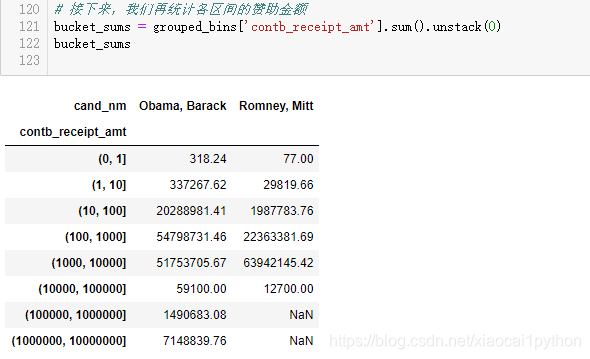

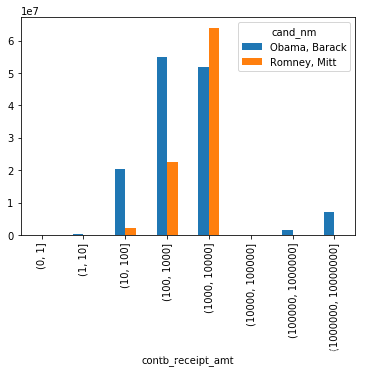
上图虽然能够大概看出Obama、Romney的赞助金额区间分布,但对比并不够突出,如果用百分比堆积图效果会更好,下面我们就实现以下。
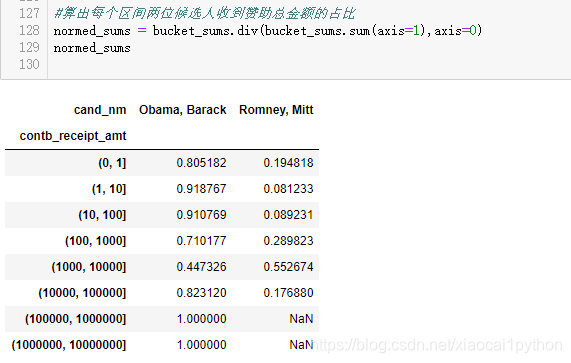

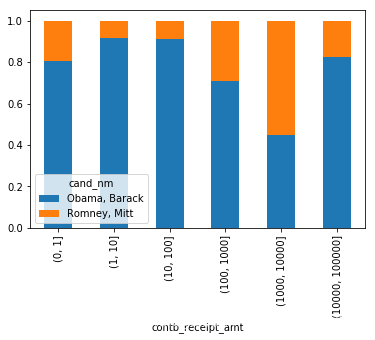
可以看出,小额赞助方面,Obama获得的数量和金额比Romney多得多
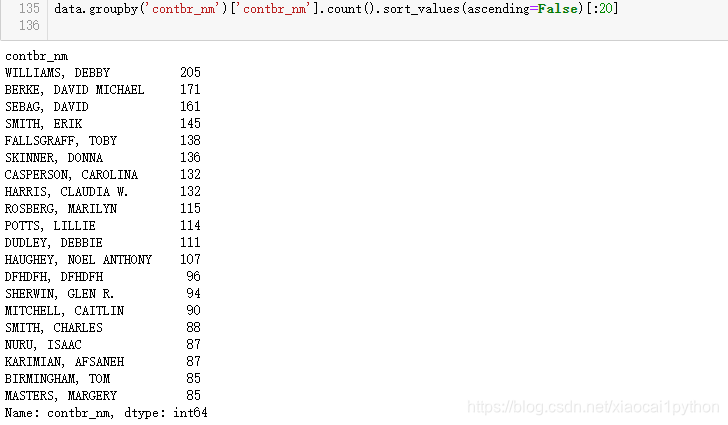
按照赞助人姓名分组计数,计算重复赞助次数最多的前20人
4.时间处理
4.1 str转datetime
我们可以使用to_datetime方法解析多种不同的日期表示形式。对标准日期格式(如ISO8601)的解析非常快。我们也可以指定特定的日期解析格式,如pd.to_datetime(series,format=’%Y%m%d’)
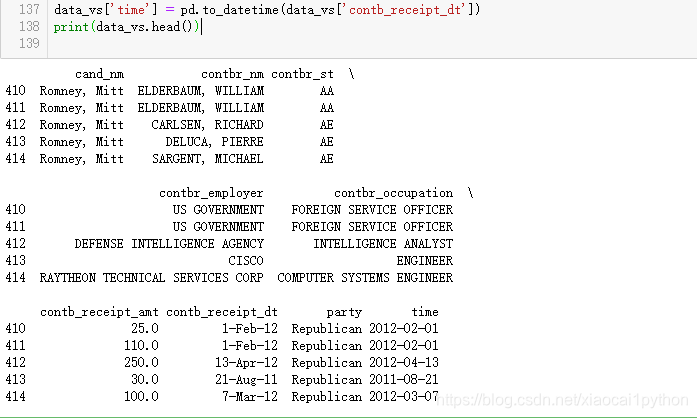
4.2 以时间作为索引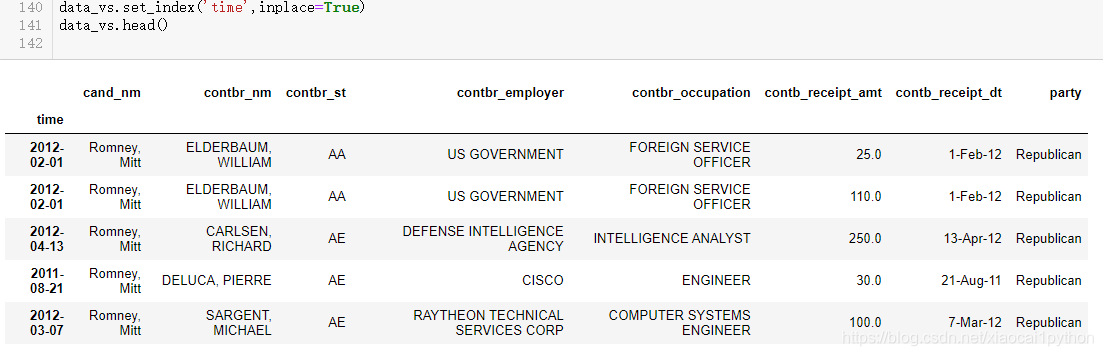 4.3重采样和频度转换
4.3重采样和频度转换
重采样(Resampling)指的是把时间序列的频度变为另一个频度的过程。把高频度的数据变为低频度叫做降采样(downsampling),resample会对数据进行分组,然后再调用聚合函数。这里我们把频率从每日转换为每月,属于高频转低频的降采样。
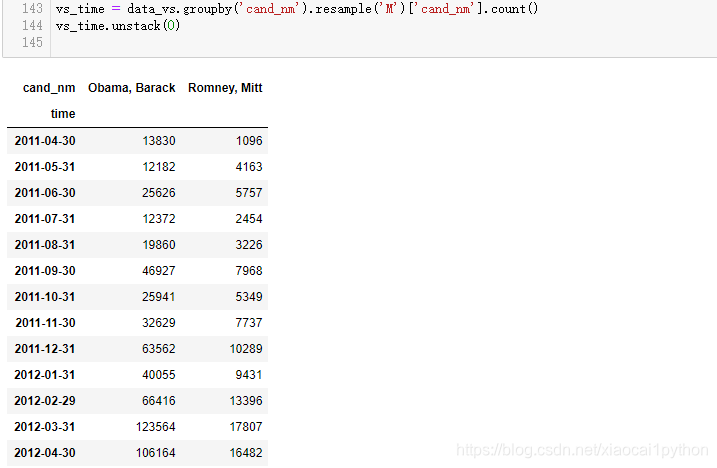
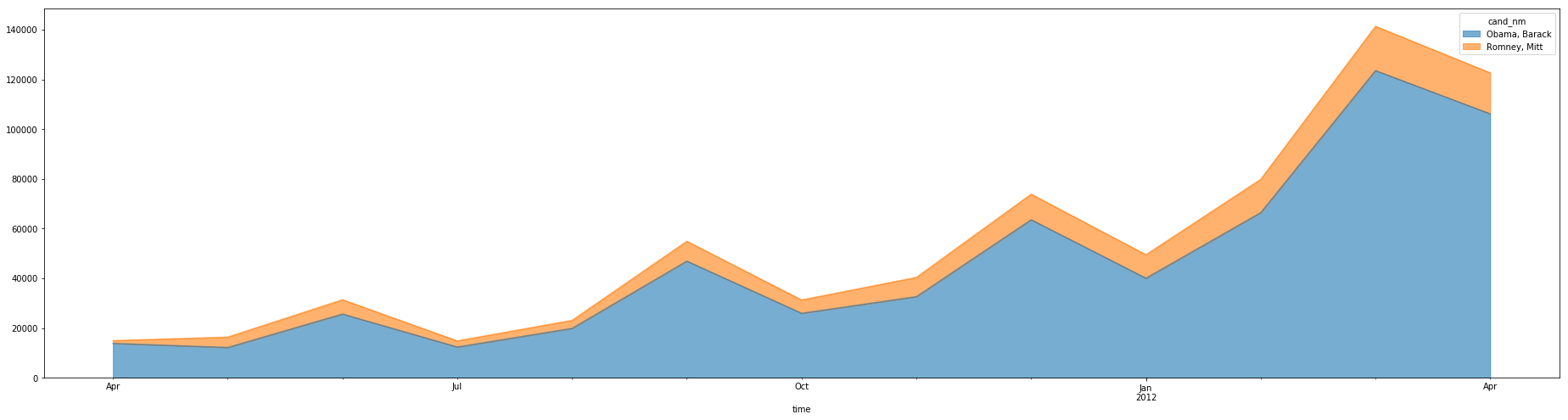
我们用面积图把11年4月-12年4月两位总统候选人接受的赞助笔数做个对比可以看出,越临近竞选,大家赞助的热情越高涨,奥巴马在各个时段都占据绝对的优势

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









