







 本文使用pandas对2012年美国总统竞选赞助数据进行分析,包括数据加载、预处理、异常值处理、党派和职业分类、赞助金额统计等,揭示了赞助金额、赞助次数与候选人之间的关系。
本文使用pandas对2012年美国总统竞选赞助数据进行分析,包括数据加载、预处理、异常值处理、党派和职业分类、赞助金额统计等,揭示了赞助金额、赞助次数与候选人之间的关系。
美国总统竞选赞助数据分析
本文内容参考阿里云天池实验室,在原有基础上添加了一些结论的分析。
原案例地址
数据来源
1、首先导入相关的python数据分析的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
2、数据的载入和预览
2.1 数据载入
由于文件较大,数据被分为三个文件,分别导入。
data_01 = pd.read_csv('./data_01.csv')
data_02 = pd.read_csv('./data_02.csv')
data_03 = pd.read_csv('./data_03.csv')
2.2 数据合并
data=pd.concat([data_01,data_02,data_03])
data.head()
显示前五行

2.3 数据预览
data.info()

cintbr_st列含有4和空值,而contbr_employer和contbr_occupation这两列中含有较多空值,后续如果使用此数据需要进行处理。
各字段含义
- cand_nm – 接受捐赠的候选人姓名
- contbr_nm – 捐赠人姓名
- contbr_st – 捐赠人所在州
- contbr_employer – 捐赠人所在公司
- contbr_occupation – 捐赠人职业
- contb_receipt_amt – 捐赠数额(美元)
- contb_receipt_dt – 收到捐款的日期
data.describe()
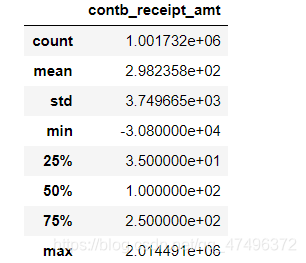
从describe方法输出的结果可以看出赞助金额的一系列统计分析数值,从结果中可以发现赞助金额的最小值为负值,必定为异常值,需要后续处理。
3.数据清洗
3.1 缺失值处理
由于我们后续需要使用contbr_employer,contbr_occupation这两列,所以此处我们用not provided填充缺失值。
data["contbr_occupation"].fillna('not provied', inplace=True)
data["contbr_employer"].fillna('not provied', inplace=True)
预览数据信息,缺失值没有了

3.2 数据筛选
#赞助金额中有负数,为了简化分析过程,我们限定数据集只有正出资额。
data = data[data['contb_receipt_amt']>0]
#查看各个候选人获得的赞助总金额
- List item
#选取候选人为Obama、Romney的子集数据
3.3 数据转换
3.3.1 党派分析(利用字典映射进行转换)
#首先获取竞选人的名单
data["cand_nm"].unique()
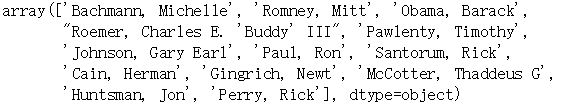
#通过搜索引擎等途径,获取到每个总统候选人的所属党派,建立字典parties,候选人名字作为键,所属党派作为对应的值*
parties = {
'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









