1.scrapy框架
创建项目:scrapy startproject 项目名
创建爬虫:cd 项目名下 ,scrapy genspider 爬虫名 allowed_domains(网站)
开启爬虫:scrapy crawl 爬虫名
2.requests模块
proxies = {"http": "http://127.0.0.1:8080"}
headers = {"User-Agent": "xxx", "Cookie": "cookie_str"}
cookie_dict = {i.split("=")[0]:i.split("=")[1] for i in cookie.split("; ")}
request.get(url,headers=headers,proxies=proxies,cookies=cookie_dict,timeout=3)
request.post(url,data=data)
proxies={协议:协议+ip+端口}
verify=False
timeout=3
retrying模块的使用
@retry(stop_max_attempt_number=3)
def _parse_url(url)
response = requests.get(url, headers=headers, timeout=3)
assert response.status_code == 200
return response
def parse_url(url)
try:
response = _parse_url(url)
except Exception as e:
print(e)
response = None
return response
3.requests中session类如何使用
session=requests.Session()
session.post(url,data)
session.get(url)带上之前的cookie
4.response常用属性
response = requests.get(url)
response.url # 当前响应的url地址
response.text # str,修改编码方式response.encoding='gbk'
response.content # bytes,修改编码方式response.content.decode('utf8')
response.status_code # 响应状态吗
response.request.headers # 当前响应的请求头
response.headers # 响应头
response.body # 响应体,也就是html代码,默认是byte类型
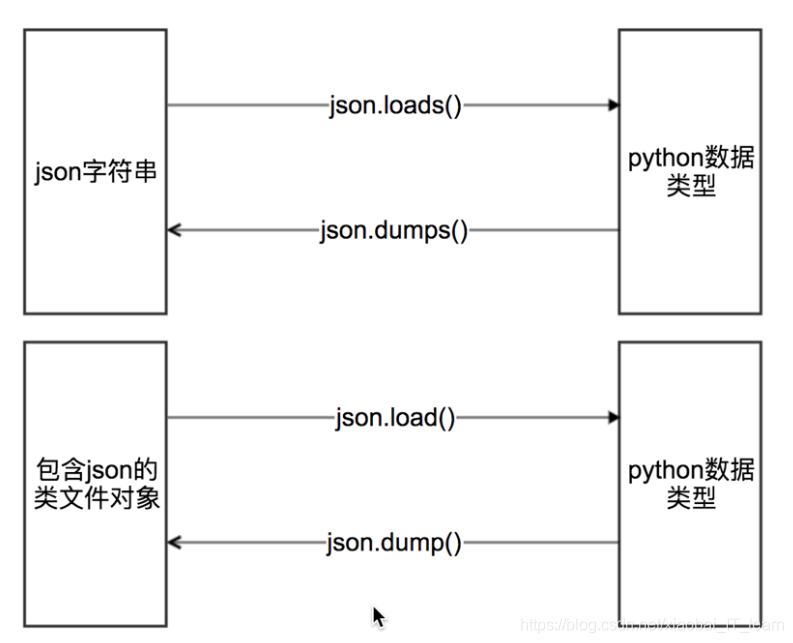
5.json和字典数据的转换
json_str = json.dumps(mydict,indent=2,ensure_ascii=False)
my_dict = json.loads(json_str)
with open("temp.txt","w") as f:
json.dump(mydict,f,ensure_ascii=False,indent=2)
with open("temp.txt","r") as f:
my_dict = json.load(f)







 本文详细介绍了scrapy爬虫框架的使用,结合requests模块,讲解了retrying模块在请求重试中的应用,深入探讨了requests中session类的运用。同时,还涵盖了response对象的常见属性及其重要性。最后,文章阐述了JSON数据与Python字典之间的转换技巧,包括json.dumps、json.loads和json.load方法。
本文详细介绍了scrapy爬虫框架的使用,结合requests模块,讲解了retrying模块在请求重试中的应用,深入探讨了requests中session类的运用。同时,还涵盖了response对象的常见属性及其重要性。最后,文章阐述了JSON数据与Python字典之间的转换技巧,包括json.dumps、json.loads和json.load方法。

















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









