






DataFrame:行列索引+多维数组
DataFrame既有行索引(index)、也有列索引(columns)
DataFrame常用于表达二维数据,但可以表达多维数据。
import pandas as pd
import numpy as np
data=np.random.randint(60,100,size=(2,3))
name=['虎酱','刀酱','阿龙']
text=['期中','期末']
df=pd.DataFrame(data,index=text,columns=name)
# print(df.max()) #三人的最高成绩
# print(df.describe()) #三人两次考试的所有数据
#25%,50%,75% 就是将列内的数值由小到大排列并分成四等份,处于25%、50%、75%三个分割点位置的数值。
df.loc['Row_sum']=df.apply(lambda x:x.sum(),axis=0) #增加新的行
row_sum = df.loc["Row_sum",:]
row_sum_argmax = row_sum[row_sum == row_sum.max()].index #获得总成绩最高对应的索引
df['col_sum']=df.apply(lambda x:x.sum(),axis=1) #增加新的列
print('优秀的',row_sum_argmax)
print(df)
output:
优秀的 Index(['刀酱'], dtype='object')
虎酱 刀酱 阿龙 col_sum
期中 72 96 96 264
期末 74 96 67 237
Row_sum 146 192 163 501
Process finished with exit code 0obj.axes #获取行及列索引
obj.T # 行与列对调
obj. info() #打印DataFrame对象的信息
obj.head(i) #显示前 i 行数据
obj.tail(i) #显示后 i 行数据
Pandas索引
df[列关键字索引值或列表] #例如:df[['虎酱','刀酱','阿龙']]
df.loc[行关键字索引值或列表] #例如:df.loc[['期中','期末']]
df.iloc[行位置参数或列表,列位置参数或列表]
#例如:
# print(df.iloc[1,:]) #索引为1所在行的所有内容
# print(df.iloc[1:,]) #索引为1以及索引为1之后的所有内容
# print(df.iloc[:,1]) #索引为1所在列的所有内容
重新索引: df.reindex(index=[...])
删除列:df.drop(3) #删除索引为3的列
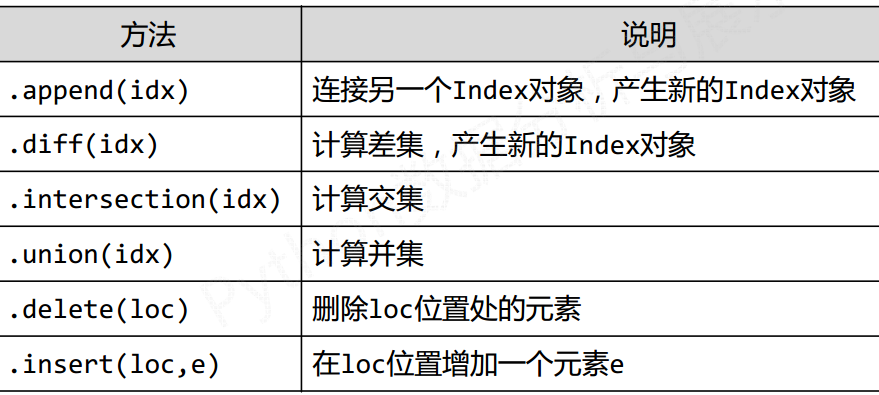
索引的类型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









