







前言
这一章主要是对gin的源码进行深入学习
一、学习经过
- 发现了一个个人博客 虽然它没怎么讲 ,但为我指了路,另外看了它的个人博客,我感觉我有点想用go完成一个自己的个人博客网站。
- 在上一篇博客的指路下我看了这篇博客,它为我指明了路口,理清了大概思路,但还是不太细致,后来自己看源码和问ai才弄明白gin的路由
- 看第二篇推荐的博客,感觉角度太高了,是从整体架构在看,看不懂,以后有机会回头再看它的思路吧。
- 看到这个博客感觉他可能讲路由讲的清晰些,不过这时我已经搞明白路由就没细看。
- 家人们发现明灯了,这个博主学习源码的记录写的特别细特别好,图文并茂,而且他的学习路线还与我规划的一样!
二、学习总结
1 Gin框架的学习
1 入口引擎
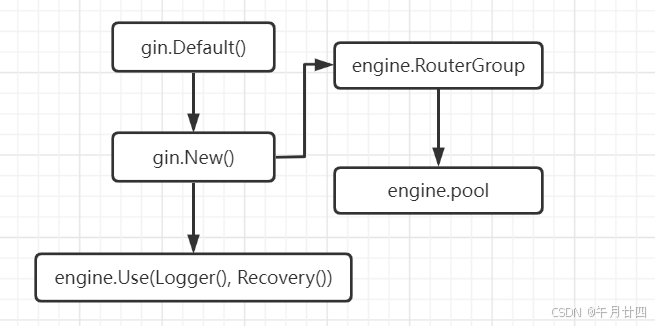
平常对gin最基础的使用都是通过gin.Default()来获取一个引擎,那么我们的源码阅读也从这里开始。
// Default returns an Engine instance with the Logger and Recovery middleware already attached.
func Default(opts ...OptionFunc) *Engine {
debugPrintWARNINGDefault() //简单的打印警告信息,不做展开
engine := New() // 真正的起点,初始化并返回一个Engine
engine.Use(Logger(), Recovery()) //放入两个中间件,一个日志一个恢复
return engine.With(opts...) //可传入一些配置函数对engine进行配置然后返回
}
type Engine struct {
RouterGroup
RedirectTrailingSlash bool
RedirectFixedPath bool
HandleMethodNotAllowed bool
ForwardedByClientIP bool
AppEngine bool
UseRawPath bool
UnescapePathValues bool
MaxMultipartMemory int64
delims render.Delims
secureJsonPrefix string
HTMLRender render.HTMLRender
FuncMap template.FuncMap
allNoRoute HandlersChain
allNoMethod HandlersChain
noRoute HandlersChain
noMethod HandlersChain
pool sync.Pool // 存放context的池,后面说context时说,用来减少GC
trees methodTrees// radix tree,保存路径与handler的映射关系,以及路径之间的父子关系
}
简单了解一下Engine最重要的三个属性,RouterGroup、pool sync.Pool和trees methodTrees
type RouterGroup struct {
Handlers HandlersChain //一个传入值为*context的函数的切片,context结构后面说
basePath string //基础路径,比如最开始创建的是"/"根路径,如果是创建了分组就是分组的路径
engine *Engine //父节点路由的Engine实体
root bool //是否为根节点路由
}
func New(opts ...OptionFunc) *Engine {
debugPrintWARNINGNew()
engine := &Engine{// 初始化engine
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/", //根节点
root: true,
},
FuncMap: template.FuncMap{},
RedirectTrailingSlash: true,
RedirectFixedPath: false,
HandleMethodNotAllowed: false,
ForwardedByClientIP: true,
RemoteIPHeaders: []string{"X-Forwarded-For", "X-Real-IP"},
TrustedPlatform: defaultPlatform,
UseRawPath: false,
RemoveExtraSlash: false,
UnescapePathValues: true,
MaxMultipartMemory: defaultMultipartMemory,
trees: make(methodTrees, 0, 9), //建立9个方法树,对应9个请求方式Get,POST等
delims: render.Delims{Left: "{{", Right: "}}"},
secureJSONPrefix: "while(1);",
trustedProxies: []string{"0.0.0.0/0", "::/0"},
trustedCIDRs: defaultTrustedCIDRs,
}
engine.RouterGroup.engine = engine// 给RouterGroup的engine初始化实例
engine.pool.New = func() any {// 创建池
return engine.allocateContext(engine.maxParams)
}
return engine.With(opts...)
}
所以我们可以通过Default来获取一个带两个中间件的engine或者New()一个最基础的engine
2 engine.Get()其他请求类似
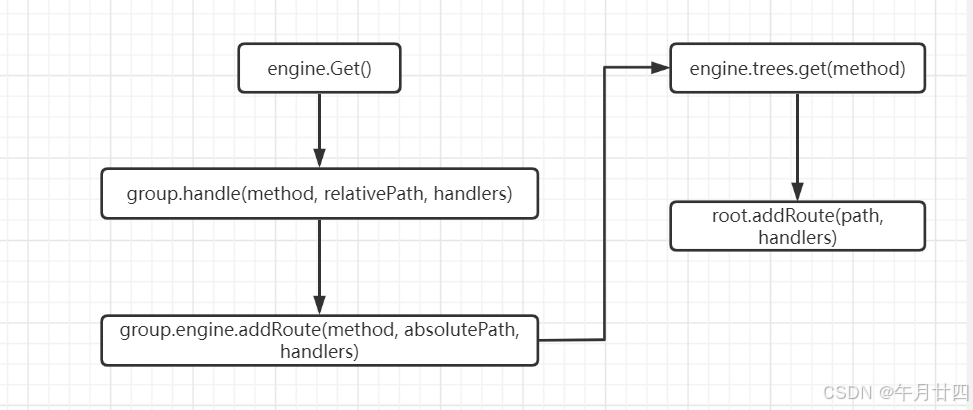
engine.Get()实际上是用的它从RouterGroup继承来的Get 方法
func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {
return group.handle(http.MethodGet, relativePath, handlers)
}
所有的请求都是调用的group.handle,区别在于传入的请求方式参数不同
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)//组合一个绝对路径
handlers = group.combineHandlers(handlers)//把对当前请求的处理函数加入到group组的处理函数切边里面
group.engine.addRoute(httpMethod, absolutePath, handlers)//往tree里面增加路径
return group.returnObj()
}
取出group的基本路径与相对路径拼一个绝对路径
func (group *RouterGroup) calculateAbsolutePath(relativePath string) string {
return joinPaths(group.basePath, relativePath)
}
新建一个处理函数切片,并将原有的和新加入的复制进去返回
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
finalSize := len(group.Handlers) + len(handlers)
assert1(finalSize < int(abortIndex), "too many handlers")
mergedHandlers := make(HandlersChain, finalSize)
copy(mergedHandlers, group.Handlers)
copy(mergedHandlers[len(group.Handlers):], handlers)
return mergedHandlers
}
获取当前请求方式的tree,然后调用node的方法将路径和handlers传进去
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
assert1(path[0] == '/', "path must begin with '/'")
assert1(method != "", "HTTP method can not be empty")
assert1(len(handlers) > 0, "there must be at least one handler")
debugPrintRoute(method, path, handlers)
root := engine.trees.get(method)
if root == nil {
root = new(node)
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
if paramsCount := countParams(path); paramsCount > engine.maxParams {
engine.maxParams = paramsCount
}
if sectionsCount := countSections(path); sectionsCount > engine.maxSections {
engine.maxSections = sectionsCount
}
}
可以分为4个部分,具体看我代码里面的注解
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++
// 第一部分,做一个空树的判断
// Empty tree
if len(n.path) == 0 && len(n.children) == 0 {
n.insertChild(path, fullPath, handlers)
n.nType = root
return
}
parentFullPathIndex := 0
walk:
for {
// Find the longest common prefix.
// This also implies that the common prefix contains no ':' or '*'
//判断最大公共前缀
// since the existing key can't contain those chars.
i := longestCommonPrefix(path, n.path)
//第二部分 若公共前缀的长度小于当前节点路径的长度,就需要分割当前节点。比如当前节点/user/add,新增一个/user/del,那么就要把公共部分/user分成一个节点,剩余的/add也要成为一个子节点
// Split edge
if i < len(n.path) {
child := node{
path: n.path[i:],
wildChild: n.wildChild,
nType: static,
indices: n.indices,
children: n.children,
handlers: n.handlers,
priority: n.priority - 1,
fullPath: n.fullPath,
}
n.children = []*node{&child}
// []byte for proper unicode char conversion, see #65
n.indices = bytesconv.BytesToString([]byte{n.path[i]})
n.path = path[:i]
n.handlers = nil
n.wildChild = false
n.fullPath = fullPath[:parentFullPathIndex+i]
}
// 第三部分,若公共前缀的长度小于新路由路径的长度,就要把新节点插入到当前节点的子节点中。还是刚刚的例子,/del也需要建立一个节点作为/user的子节点
// Make new node a child of this node
if i < len(path) {
path = path[i:]
c := path[0]
// '/' after param
if n.nType == param && c == '/' && len(n.children) == 1 {
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
continue walk
}
// Check if a child with the next path byte exists
for i, max := 0, len(n.indices); i < max; i++ {
if c == n.indices[i] {
parentFullPathIndex += len(n.path)
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// Otherwise insert it
if c != ':' && c != '*' && n.nType != catchAll {
// []byte for proper unicode char conversion, see #65
n.indices += bytesconv.BytesToString([]byte{c})
child := &node{
fullPath: fullPath,
}
n.addChild(child)
n.incrementChildPrio(len(n.indices) - 1)
n = child
} else if n.wildChild {
// inserting a wildcard node, need to check if it conflicts with the existing wildcard
n = n.children[len(n.children)-1]
n.priority++
// Check if the wildcard matches
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
// Adding a child to a catchAll is not possible
n.nType != catchAll &&
// Check for longer wildcard, e.g. :name and :names
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
continue walk
}
// Wildcard conflict
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(pathSeg, "/", 2)[0]
}
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
n.insertChild(path, fullPath, handlers)
return
}
//第四部分,若公共前缀的长度等于新路由路径的长度,说明已经到达了插入位置。若当前节点已经有处理函数,就抛出异常;否则,将新的处理函数赋值给当前节点,并更新fullPath属性。
// Otherwise add handle to current node
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
}
n.handlers = handlers
n.fullPath = fullPath
return
}
}
3 engine.Run
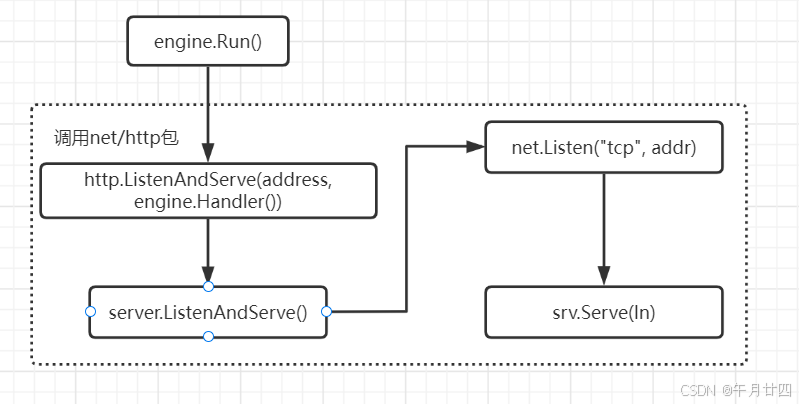
Gin的engine.Run方法本质上是对go基础包中net/http包的封装
func (engine *Engine) Run(addr ...string) (err error) {
defer func() { debugPrintError(err) }()
if engine.isUnsafeTrustedProxies() {
debugPrint("[WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.\n" +
"Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.")
}
address := resolveAddress(addr) //初始化服务器地址和端口号,默认8080
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine.Handler())//调用http.ListenAndServe进行服务监听
return
}
通过Server的ListenAndServe方法建立tcp监听
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
func (s *Server) ListenAndServe() error {
if s.shuttingDown() {
return ErrServerClosed
}
addr := s.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)//设置监听
if err != nil {
return err
}
return s.Serve(ln)//处理连接
}
对网络这一块不是很了解,只知道是建立了协程去并发的处理进来的请求
func (s *Server) Serve(l net.Listener) error {
if fn := testHookServerServe; fn != nil {
fn(s, l) // call hook with unwrapped listener
}
origListener := l
l = &onceCloseListener{Listener: l}
defer l.Close()
if err := s.setupHTTP2_Serve(); err != nil {
return err
}
if !s.trackListener(&l, true) {
return ErrServerClosed
}
defer s.trackListener(&l, false)
baseCtx := context.Background()
if s.BaseContext != nil {
baseCtx = s.BaseContext(origListener)
if baseCtx == nil {
panic("BaseContext returned a nil context")
}
}
var tempDelay time.Duration // how long to sleep on accept failure
ctx := context.WithValue(baseCtx, ServerContextKey, s)
for {
rw, err := l.Accept()
if err != nil {
if s.shuttingDown() {
return ErrServerClosed
}
if ne, ok := err.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
s.logf("http: Accept error: %v; retrying in %v", err, tempDelay)
time.Sleep(tempDelay)
continue
}
return err
}
connCtx := ctx
if cc := s.ConnContext; cc != nil {
connCtx = cc(connCtx, rw)
if connCtx == nil {
panic("ConnContext returned nil")
}
}
tempDelay = 0
c := s.newConn(rw)
c.setState(c.rwc, StateNew, runHooks) // before Serve can return
go c.serve(connCtx)
}
}
到这,一个最简单的gin的demo便可以实现了
再说一些常用的设置与操作
4 路由分组
很眼熟对吧,它跟前面的New很像,但这里只对RouterGroup进行了更新,改变了该分组的基本路径和基础的处理函数,使得该分组的路由都会带上它的基本路径和处理函数
func (group *RouterGroup) Group(relativePath string, handlers ...HandlerFunc) *RouterGroup {
return &RouterGroup{
Handlers: group.combineHandlers(handlers),
basePath: group.calculateAbsolutePath(relativePath),
engine: group.engine,
}
}
5 中间件
可以看到跟上面差不多,只不过中间件只修改了处理函数,而路由分组还修改了路径,另外返回的是IRoutes,实际上是一个接口,而RouterGroup实现了这个接口
func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes {
group.Handlers = append(group.Handlers, middleware...)
return group.returnObj()
}
6 context
type Context struct {
writermem responseWriter
Request *http.Request
Writer ResponseWriter
Params Params
handlers HandlersChain
index int8
fullPath string
engine *Engine
params *Params
skippedNodes *[]skippedNode
// This mutex protects Keys map.
mu sync.RWMutex
// Keys is a key/value pair exclusively for the context of each request.
Keys map[string]any
// Errors is a list of errors attached to all the handlers/middlewares who used this context.
Errors errorMsgs
// Accepted defines a list of manually accepted formats for content negotiation.
Accepted []string
// queryCache caches the query result from c.Request.URL.Query().
queryCache url.Values
// formCache caches c.Request.PostForm, which contains the parsed form data from POST, PATCH,
// or PUT body parameters.
formCache url.Values
// SameSite allows a server to define a cookie attribute making it impossible for
// the browser to send this cookie along with cross-site requests.
sameSite http.SameSite
}
通过介绍方法来解释结构体属性
Context.reset()
此方法用来重置context,每次处理新请求的时候,从pool中取context都要先进行重置。
Context.Copy()
新建一个context,原有context内的数据复制一份到新context中。在gin中,如果需要重开goroutine时,官方建议使用此方法,借此传递Context。
Context.HandlerName()/Context.HandlerNames()
返回处理函数的名字,前者返回最后一个,后者返回所有
func (c *Context) Next() {
c.index++
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)
c.index++
}
}
Next只能用在中间件中,索引加一的意思,其实就是执行下一个handler
func (c *Context) Abort() {
c.index = abortIndex
}
Abort直接跳到最后,也就是执行完毕,不在向下执行,直接返回,比如用户在权限验证中间件验证未通过,就可以用这个
Context.AbortWithStatus()/AbortWithStatusJSON()/AbortWithError()
此类方法即相当于Abort()时,加入code或者是正确错误返回,c.Writer中加入相关响应。
func (c *Context) Get(key string) (value any, exists bool) {
c.mu.RLock()
defer c.mu.RUnlock()
value, exists = c.Keys[key]
return
}
func (c *Context) Set(key string, value any) {
c.mu.Lock()
defer c.mu.Unlock()
if c.Keys == nil {
c.Keys = make(map[string]any)
}
c.Keys[key] = value
}
这两个方法是借助context中定义的Map结构keys来进行值的传递,让我们在中间件的执行流程中能接收和传递数据,同时考虑到并发,会使用context中定义的锁来保证数据的可靠。
读取请求传入的参数
- 动态路由参数
比如我们注册了这样一个路由:router.Get(“/app/v1/user/:userId”, xxx),其中userId这个参数就是一个动态的url参数,我们此时就可以使用c.Param(“userId”)获取对应参数,默认""。
- query参数
直接调用c.Query(“key-name”)即可,当然gin也提供了带有默认值的DefaultQuery(key, defaultValue string) string以及带有判断的GetQuery(key string) (string, bool),如果query参数的array或者map,也都不在话下,因为gin提供了QueryArray、QueryMap等。
- form表单
gin在表单参数方面也提供了类似query参数提取的方法:
PostForm(key string) (value string),根据可以提取val,限定string类型,默认没有即返回“”
DefaultPostForm(key, defaultValue string) string,没有即返回default值
GetPostForm(key string) (string, bool),带判断的返回
PostFormArray(key string) (values []string)/PostFormMap,解析array/map类型的form参数
或者当涉及到文件上传时,gin提供了FormFile(name string) (*multipart.FileHeader, error),gin的context甚至还提供了文件上传的实现-SaveUploadedFile(file *multipart.FileHeader, dst string) error,比如我们通过FormFile()拿到fh,然后调用SaveUploadedFile()即可实现文件的上传。
- json/yaml/toml/xml格式的request body
我们日常的api开发中最常用的就是通过json格式的数据作为body的传递格式,这里以json格式的body为例说明。
通常在请求体中的首部header中,Content-Type:application/json,这是较为常见的。问题来了,我们在具体的业务逻辑中又怎么获取到这些body呢。
gin的context为我们提供一系列的BindXXX方法:
Bind()/BindJSON()/BindXML()/BindYAML()
MustBindWith(obj any, b binding.Binding) error
ShouldBind()/ShouldBindJSON()…
ShouldBindWith()/ShouldBindBodyWith()
这是最基础的两个Bindxxx方法,根据官方的注解,如果追求性能,就用ShouldBindWith(),如果多次解析body,考虑重用,就用ShouldBindBodyWith()。其中ShouldBind()实际调用ShouldBindWith(),ShouldBindJSON()只是指明binding.type,MustBindWith()的解析则带有异常解析提前返回的处理,实际也是调用ShouldBindWith(),此外所有的Bindxxx()都是MustBindWith()加对应type的解析。
返回响应
- Header/GetHeader
Header()是写入到响应首部,对应签名:Header(key, value string) {}。
GetHeader()则是从请求中获取请求首部的信息,对应签名:GetHeader(key string) string {}。
- Cookie/SetCookie
Cookie()是为了获取cookie,SetCookie则是设置cookie,具体这里详细叙述,有兴趣可自行搜索。
- JSON/XML/HTML/String
这类的方法都是Render功能,只是序列化格式差异,比如我们在api中可以直接:
ctx.JSON(200, gin.H{})
ctx.String(200, gin.H{})
使用也比较简单,就是不同序列化格式而已,具体使用需要和前端同事协定好格式。
7 处理请求
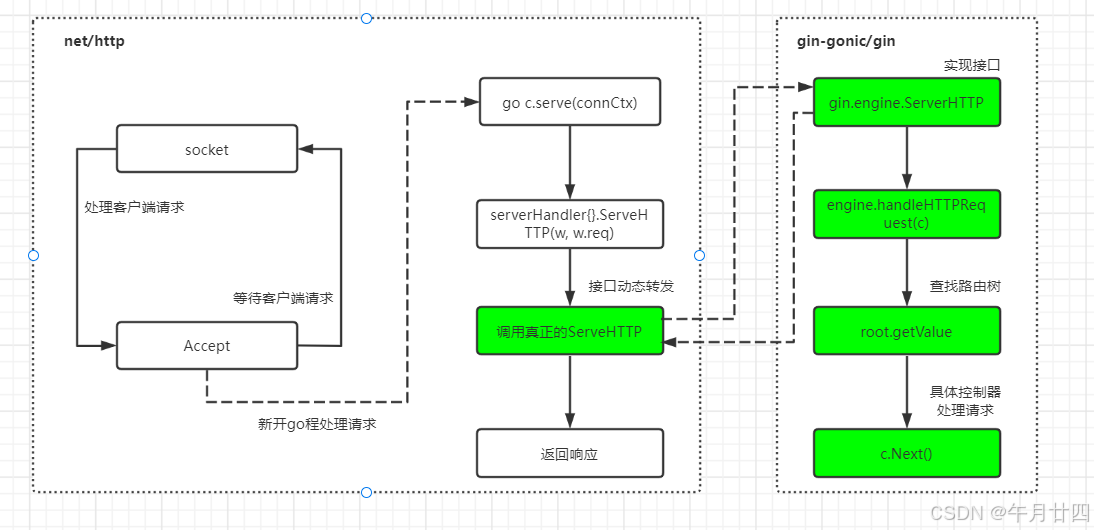
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context) //从池中捞一个对象转成context,避免频繁创建对象,减少GC
c.writermem.reset(w) // 重置并关联新的响应
c.Request = req // 关联请求
c.reset() //重置
engine.handleHTTPRequest(c)// 处理请求
engine.pool.Put(c) //将context放回pool
}
func (engine *Engine) handleHTTPRequest(c *Context) {
//第一部分,获取请求路径与方法
httpMethod := c.Request.Method
rPath := c.Request.URL.Path
unescape := false
if engine.UseRawPath && len(c.Request.URL.RawPath) > 0 {
rPath = c.Request.URL.RawPath
unescape = engine.UnescapePathValues
}
if engine.RemoveExtraSlash {
rPath = cleanPath(rPath)
}
//第二部分,在路由树中查找匹配的路由
// Find root of the tree for the given HTTP method
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
// Find route in tree
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
if value.params != nil {
c.Params = *value.params
}
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
if httpMethod != http.MethodConnect && rPath != "/" {
if value.tsr && engine.RedirectTrailingSlash {
redirectTrailingSlash(c)
return
}
if engine.RedirectFixedPath && redirectFixedPath(c, root, engine.RedirectFixedPath) {
return
}
}
break
}
// 处理方法不允许的情况
if engine.HandleMethodNotAllowed {
// According to RFC 7231 section 6.5.5, MUST generate an Allow header field in response
// containing a list of the target resource's currently supported methods.
allowed := make([]string, 0, len(t)-1)
for _, tree := range engine.trees {
if tree.method == httpMethod {
continue
}
if value := tree.root.getValue(rPath, nil, c.skippedNodes, unescape); value.handlers != nil {
allowed = append(allowed, tree.method)
}
}
if len(allowed) > 0 {
c.handlers = engine.allNoMethod
c.writermem.Header().Set("Allow", strings.Join(allowed, ", "))
serveError(c, http.StatusMethodNotAllowed, default405Body)
return
}
}
// 处理未找到路由的情况
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}
总结
对gin的解析暂时告一段落,也算比较全面了吧,从建立一个demo要用到的部分,到一些常用的功能,对请求的处理。另外可能没有提到的有对模板的渲染,这点考虑到以后大都是前后端分离的架构,用到的少,便不做过多研究了,另外像日志的管理也没展开也是因为以后像将日志管理功能单独抽出来用别的组件。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









