









论文:Densely Connected Convolutional Networks
论文链接:https://arxiv.org/pdf/1608.06993.pdf
代码的github链接:https://github.com/liuzhuang13/DenseNet
文章是CVPR2017的oral。
目录
2.1 ResNet的残差结构(ResBlock)示意图 + 公式
1. 模型综述
1.1 核心理解
文章提出了一种密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入,该结构主要还是和 ResNet 以及 Inception 网络的结构做对比。
我们知道从2015年开始,卷积神经神经网络性能提升的两个主要方向是 (1)加深网络深度(网络退化问题,因ResNet的残差结构的出现得以缓解,不能说解决)(2)加宽宽度(GoogleNet的Inception结构)。
但从另一个角度出发,对于图像 or 视觉任务,如果能够(3)挖掘到更丰富的语义特征(4)减少卷积or池化造成特征信息丢失(5)减少在网络前向传播、反向传播时候以及梯度传递过程中的梯度损失,自然而然就能够提升某个网络模型的性能。
我认为DenseNet主要就是从上面(4)和(5)入手,作者通过对feature的极致利用使模型有了更好的性能,相对的,充分利用feature不免会引入过多的参数(密集连接,特征使用concat的拼接方式,使得下一层的输入特征通道非常大),因此作者同样使用1*1卷积这样的trick解决了参数过多的问题,最终结果就是更少的参数更高的性能(这个最终结果反映了本文这种结构的优越性)。
1.2 主要优点
总结下DenseNet的几个核心优点:
1、减轻了梯度消失 vanishing-gradient,对应上文(5)的观点。
2、加强了feature的传递,主要对应上文(4)中的观点。
3、通过更密集的特征链接,更有效地利用了 feature(直接传递了input和梯度)(更密集也是相对于ResNet的残差结构而言)。
4、基于1 * 1卷积的trick,构造了 DenseBlock 和 transition layer ,该结构较少了参数数量(1 * 1卷积在不改变feature map尺寸的前提下减少通道数目)。
2. DenseNet
在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显,当前有很多论文都针对这个问题提出了解决方案,比如ResNet,Highway Networks,Stochastic depth,FractalNets等,尽管这些算法的网络结构有差别,但是核心都在于:create short paths from early layers to later layers,也就是使用短链接将浅层特征直接连接/传递到深层中并与之结合。延续这个思路,DenseNet为了保证神经网络中层与层之间最大程度的信息传递,在一定范围内(对应下文DenseBlock)将当前层 前面所有层的输出Concat后作为当前层的输入。
不过在这里我们先介绍一下ResBlock,毕竟原文中的DenseBlock的密集连接方式是相对于ResBlock而言的。
2.1 ResNet的残差结构(ResBlock)示意图 + 公式
在这里为了对应原文,假定神经网络第 l 层的输入,第 l 层的输出
,第 l 层中连续 weight layer(conv layer)的操作统一成函数
,其中 + 号位置表示对应元素求和。
!注意:部分,对应 ResNet18、ResNet34 的Res Block,该Block由两层 3*3 conv 构成;ResNet50,ResNet101,ResNet152的Res Block由 1*1 conv,3*3 conv,1*1 conv构成。这部分的结构因需求而变,不是固定的。
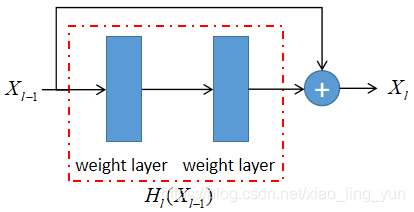
上述过程正好对应ResNet原文中的公式 :
2.2 DenseBlock 结构示意图 + 公式
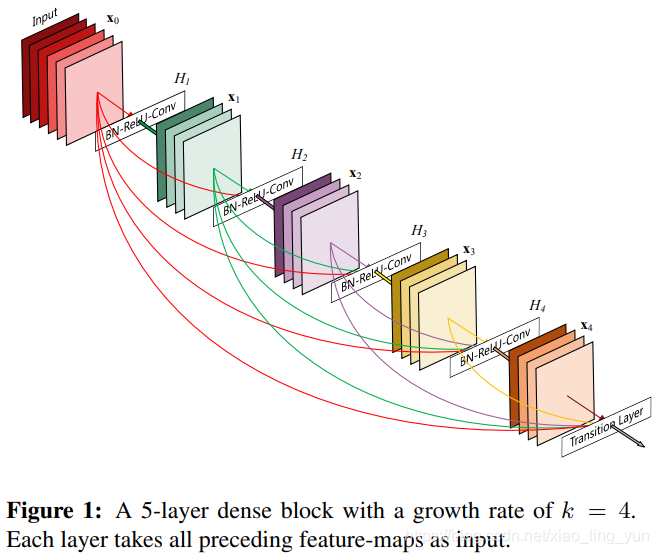
上图 Figure 1 是原文中的示例,一个 5 层Dense Block结构,DenseNet的主体是由数个这类Block构成。图中x0,x1。。。。x4表示的是特征图 ,也就是feature map。
与 Figure 1 对应的,我们可以得到DenseNet中每一个Block的特征计算公式,假定神经网络第 l 层的输入,第 l 层的输出
,第 l 层中连续 weight layer(conv layer)的操作统一成函数
,即
由该Block中,在第 l 层之前所有的特征结果计算而来。下面有例子:
看上图,以x2为例,该特征由x0,x1在concat(通道方向)拼接后经过 卷积模块H2 得到x2,在代码中该卷积模块由 BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv 组成,详见下:
注意:
(1)1 * 1不改变特征尺寸;3 * 3卷积中,卷积核kernal = 3,padding = 1,stride = 1 ,这样计算出来的输出特征尺寸 = 输入的特征尺寸!!!总的来说,在一个卷积模块乃至整个Dense Block中,特征尺寸不变!!!这也是为了方便特征concat拼接。
(2)一个拥有L层(层指的是卷积模块)的Dense Block ,共有个连接。
class _DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
# 还是以x2为例,输入的x = concat(x0,x1),该模块得到的new_features的结果就是x2
# 那么我们将x和x2进行concat得到的结果就是x0,x1,x2 concat后得到的特征,该特征经过下一个卷积模块H3 得到x3。
# 现在仔细想一想在这个DenseBlock内,特征图x1由x0计算而来,特征图x2由x0和x1计算而来,特征图x3由x0,x1,x2计算而来,刚好实现了论文的核心思想。有了卷积模块,多个卷积模块就构成了一个DenseBlock:
由上文红字可知,在一个Block中的feature map的尺寸是不会变化的,那么在前向计算的过程中,伴随着feature map的concat拼接,特征的通道数目呈线性增长,对于这个问题,作者使用1 * 1卷积解决,我们第三节细讲。
class _DenseBlock(nn.Sequential):
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)2.2 DenseNet示例
看完 2.1 我们已经知道了DenseNet的最核心的组件DenseBlock,那我们现在就看看原论文中 Figure 2 表示的一个包含3个Block的Net示例:
当然作者将DenseNet分成多个dense block,原因是希望各个Dense Block内的 feature map 的size统一,这样在做concatenation就不会有size的问题。注:每一个Dense Block中的feature map 尺寸一样。

2.3 DenseNet具体网络结构
看完了概念图,我们从原文里面来分析下细节,先看一个表格 Table 1:
先讲一下表中的一些参数含义:
(1)k 表示的是growth rate ,其实就是每个Dense Block中每层输出的feature map的通道数目,k = 32,k = 48; 12 24 64 64= 6 +36 + 128
(2)× 6 或者 × 12意味着该Block由6个或者12个卷积模块链接构成(举个简单的例子嘛:DenseNet-121,意味着这个版本的模型有121个卷积层(包含最开始的7 * 7conv 、 Block 和 Transition 部分的卷积 和 全连接层)。
从头开始计算 1 + 2 * 6(Block 1) + 1(Transition 1 conv) + 2 * 12 + 1 + 2 * 24 + 1 + 2 *16 + 1 = 121

3. 模型实现过程中的具体细节
看图和看表其实你看不到作者的用意以及模型的具体实现的,所以重点放在这一块,我们一个个来讲。
(1)在每一个Block中是存在大量的密集连接的(feature map的concat操作),以DenseNet-121中的Block 3举例,Block3包含了24个卷积模块(每个卷积模块由1个 1 * 1 conv 以及 1个 3 * 3 conv构成,共计24个1 * 1 conv 和24个3 * 3 conv ) ,k = 32表示每一个卷积模块输出的feature map都是32 通道的。
那么来看第24个卷积模块,如果没有 1 * 1 conv减少通道数目,模块中3 * 3 conv的输入就是32 * 23 + 上一个DenseBlock的最终输出的特征维度,大概有700~800的样子,这个尺寸就很大了。因此作者引入了bottleneck layer,就是在每一个DenseBlock的卷积模块中的3 * 3 conv都加入了1 * 1 conv用来减少通道数目(看上面那个图。。很清晰),最终达到的效果就是既融合了各个通道特征,又降维减少了计算量。
(2)同样的问题,作者为了进一步减少特征通道数目,在两个DenseBlock之间加入了 Transition Layer,该层的1 * 1卷积默认将输入的 feature map 的通道数目减半(该Layer存在一个参数 reduction,0~1之间的一个值,是用来控制将输入feature map通道数目缩小多少倍)。而在原论文的模型尝试中,DenseNet-BC这个网络,表示既有 bottleneck layer,又有Translation layer。
(3)可以看到即使如此,模型特征间的连接还是比较多的,模型结构比较负责,理论上过于复杂的模型结构,如果没有足够的数据支持是非常容易过拟合的,为了解决这个隐患,作者在实现网络的时候也使用了 drop out 机制。
4. 实验结论
我们就看几个重要的实验结果图。
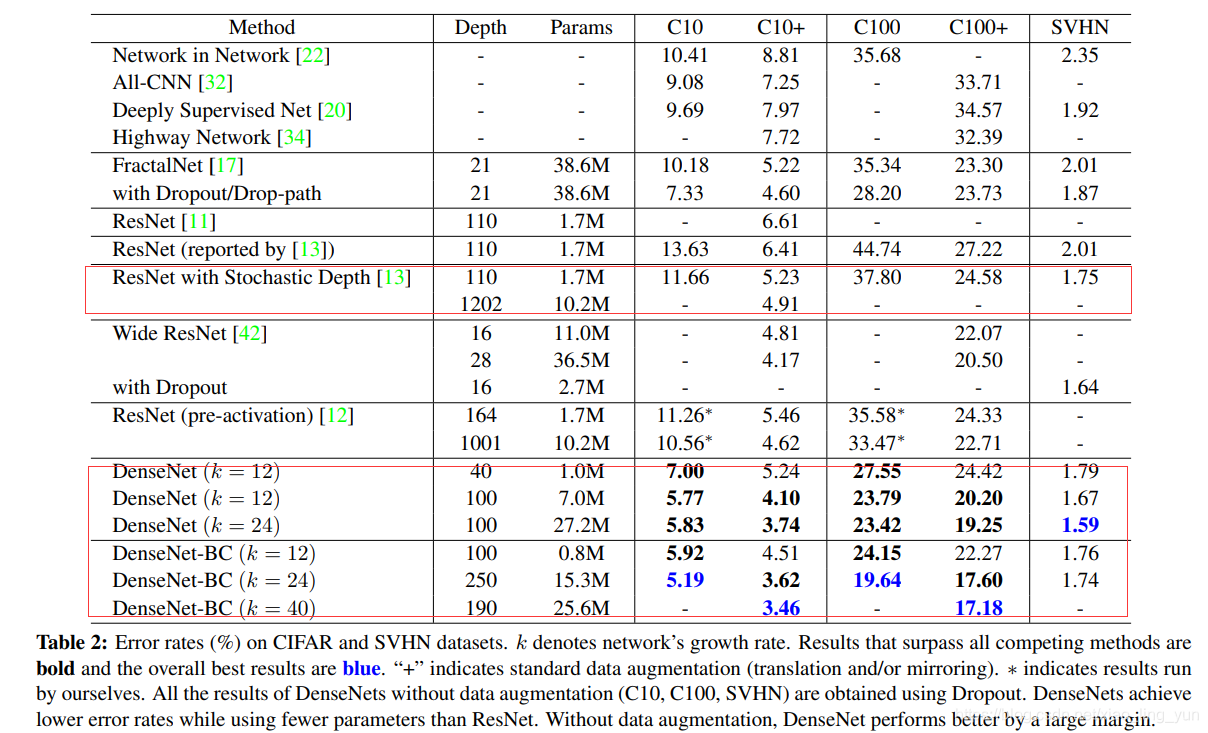
作者在C10、C100、SVHN 3个数据集上进行了对比实验,我们主要观察红色框区域,与ResNet101以及ResNet1202 比较DenseNet无论从参数量还是精度上都非常优秀。尤其是参数量这一块!
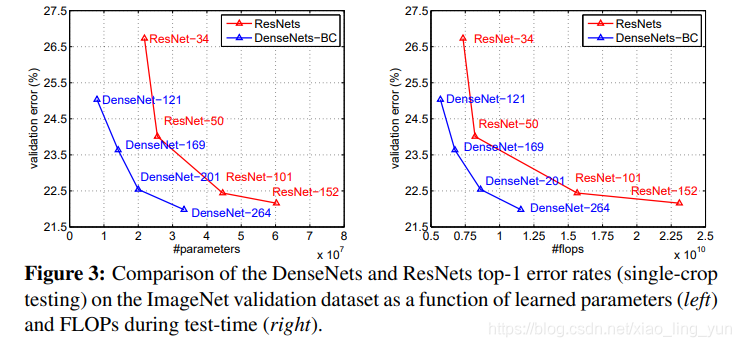
再看一看 参数量与验证集误差,计算复杂度(flops)与验证集误差之间的关系。
左图:在同等参数量的情况下,DenseNet 对比 ResNet 能够获得更好的性能,也就是更低的验证集误差;
右图:在同等flops的情况下,DenseNet 同样优于 ResNet 。
从这两方面对比,展示出的结果确实是 DenseNet 的结构优于 ResNet。
5. 个人理解
确实看实验,DenseNet的结果优于ResNet,但是这个模型到现在为止确实不是很流行。我们知道想要提升图像任务的性能,一大关注点就是充分利用抽取到的特征并且在卷积过程中减少信息的丢失,DenseNet总体就是从这个方向出发,它确实也做到了极致,但是按照我的理解来看这种过于复杂的连接方式并不是最优解,尽管它充分利用了特征,但是如果网络再复杂一些那?如果换做是目标检测任务,我们可能还需要结合不同层级的信息(例如FPN,至今FPN已经成为了Backbone的核心trick),我们的开销可能又会大一些,再者说在每一个Block之间和Block开始使用1 × 1卷积减少通道数目,虽然结果上看是好的,但是不免也损失了很大一部分的特征,这一块就很玄学了。

















 102
102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









