




为什么
随着业务的发展,关系型数据库 MySQL、Oracle数据库里的单表数据量越来越大,我们发现查询、修改、更新、修改表的DDL执行、修改列类型、添加字段、修改索引、的速度越来越慢。MySQL上千万、Oracle几千万的时候问题开始明显突出。如果你的表比较复杂,或者执行的查询比较复杂,到不了这个数量级就会突出。
我们开始通过各种方式解决这个问题。
应用层业务拆分
-
历史表
按时间拆分历史表出去,降低数据量,这个以前比较常见。其实也是一种特殊的水平拆分,对业务有侵入性 -
其他拆分方法结合自身业务操作
应用层数据库拆表
-
垂直拆分
按列拆分,将列比较多的宽表 拆分成多个~列少的表(也就是每条记录数据量小),这种方法不能降低单表记录数,但是降低了每个子表的数据量和索引量大小,达到提速目的
-
水平拆分
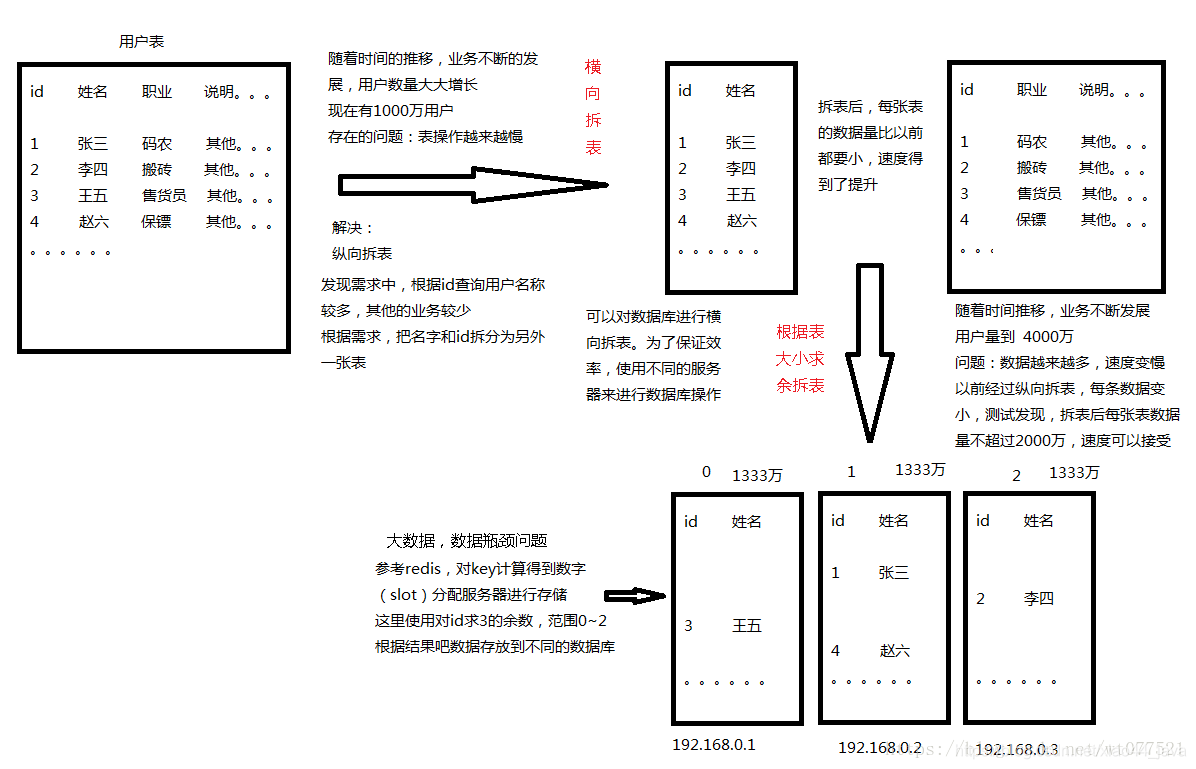
按某个或某些列(如数字型id)的值哈希后,均匀的将数据拆分到多个同样表里(这些表可以分摊到不同的库中,这些库可以分配到不同的物理机或者虚拟机上),这样就直接降低了单库单表的数据量。比如原来有1333w的表说拆分成3个子表,就可以将单表的数据量降低为原表的1/3,单表只有不到445w。如果拆分成更多的表,单表操作压力就更小了。
缺点就是,原来只需要操作一个表,现在操作之前需要先知道要操作那张表,比如一个用户表users,按uid分表为3个表(users_0,users_1,users_2):原来的
--SQL1: select * from users where uid=4现在得先知道uid是4,然后id对表数量取膜,4%3==1 知道表名users_1,SQL就变成了
-- SQL2: select * from users_1 where uid=4
看起来也是属于业务侵入型的。不过我们可以把这个过程封装一下,提供一个组件,不需要每个程序员都参与其中的处理…
下图列出了数据库拆分流程
数据库读写分离
读多写少的情况下 ,分配几个只读库,把读的压力分分配给只读库,就可以降低主库的读压力,让主库关注于写。这时候也需要一个中间件来把数据请求路由到不同的库上。阿里云的RDS数据库就是支持这种方式。
数据库中间件
上面提到的水平拆分的时候,如果有中间件可以帮我们自动的把SQL1变成SQL2,从而使得我们开发的时候不用思考 分不分库、分不分表,分多少个,不用太多修改。岂不是很完美。这就是数据库中间件。
- 其实很多大公司都有自己的数据库中间件,下面列出了一些开源的:
- Cobar:阿里巴巴B2B开发的关系型分布式系统,管理将近3000个MySQL实例。 在阿里经受住了考验,后面由于作者的走开的原因cobar没有人维护 了,阿里也开发了tddl替代cobar。
- MyCAT:社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,目前已经有一些公司在使用MyCAT。总体来说支持度比 较高,也会一直维护下去,
- OneProxy:数据库界大牛,前支付宝数据库团队领导楼总开发,基于mysql官方 的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件, 楼总舍去了一些功能点,专注在性能和稳定性上。有朋友测试过说在 高并发下很稳定。
- Vitess:这个中间件是Youtube生产在使用的,但是架构很复杂。 与以往中间件不同,使用Vitess应用改动比较大要 使用他提供语言的API接口,我们可以借鉴他其中的一些设计思想。
- Kingshard:Kingshard是前360Atlas中间件开发团队的陈菲利用业务时间 用go语言开发的,目前参与开发的人员有3个左右, 目前来看还不是成熟可以使用的产品,需要在不断完善。
- Atlas:360团队基于mysql proxy 把lua用C改写。原有版本是支持分表, 目前已经放出了分库分表版本。在网上看到一些朋友经常说在高并 发下会经常挂掉,如果大家要使用需要提前做好测试。
- MaxScale与MySQL Route:这两个中间件都算是官方的吧,MaxScale是mariadb (MySQL原作者维护的一个版本)研发的,目前版本不支持分库分表。MySQL Route是现在MySQL 官方Oracle公司发布出来的一个中间件。
- ShardingSphere,后起之秀,源于当当网架构部的ShardingJDBC框架。
如果我们的业务发展到了需要降低单库单表的压力的地步,又不想花精力进行研发,引入数据库中间件是比较好的方式。使用免费的开源数据库中间件,真是又省钱又省时间。
云数据库
数据库中间件是很好的方案,如果数据库本来就支持岂不是更好, 对于用户来讲配置数据库中间件的工作都省了。这样云数据库出现了。
数据库中间件研发是需要费用和时间的,开源之后也不能和用户收费。。。如果把这项技术融入到云服务体系中。封装成云数据库,买机器送服务,可以对用户收费。是个好的选择。
对于企业来讲,虽然使用云数据库费用比数据库中间件高一点,不过省去了研发成本, 运维成本。在当今这个机器比人便宜的社会。无疑是个更好的选择。
知乎上的问题
知乎上有人问了一个好问题:
为什么几乎所有的开源数据库中间件都是国内公司开源的?并且几乎都停止了更新?
回帖中有人有问了几个问题
什么时候需要数据中间件,中间件能干什么
数据中间件的实现原理,有哪些开源数据中间件
为什么都是国内开源的,并且大都停止了更新
推荐使用什么数据中间件,有什么优势
我们来捋一下进化流程:
-
应用层分库分表
开始时间不详,可以说有狗那年就有这个方案
现在的java项目中使用spring多数据源的方式,可以实现动态数据源让代码解决这个问题。
层级关系是这样的:
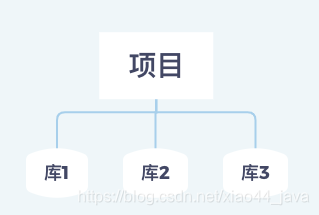
这样做的优点:- 数据库操作由开发人员完成,对使用那种数据库没有关系
- 没有中间层,效率高,更容易对业务针对性优化。
缺点:
3. 需要开发人员边写代码完成数据库操作, 数据库节点变多,或者发生变化的时候,对整个业务产生影响。 -
mycat
社区爱好者在阿里cobar基础上进行二次开发的, github上提交的第一个release版本1.3-alpha是在2014年12月
mycat曾经一度成为很流行的方案。它创建了中间层,有效的降低了对业务的侵入,减少开发人员工作量,增加了数据库节点变化的兼容,对数据无关性更友好,他的层级关系是这样的:
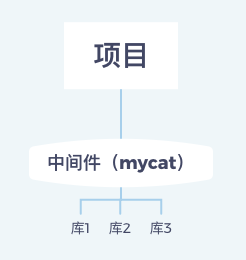
mycat 会先拦截用户发送的sql,然后对sql进行分析(分片分析,路由分析,读写分离分析,缓存分析等)然后将sql发送到数据库执行, 然后将各个数据库返回的数据进行汇总处理, 把结果返回给用户
mycat 的实现方案有些缺陷,或者说可以提升的地方。主要体现在:-
非分片字段查询时会到所有节点上执行,节点多时消耗Mycat和MySQL数据库资源
-
分页排序效率低下,不指定排序字段随机返回,指定排序字段后mycat会改写sql,limit m,n 改为limit 0,m+n 到每个分库查询,然后按照最小堆排序取结果,当偏移量大时效率几十倍的下降
-
任意表join,要确保两个表的关联字段具有相同的数据分布,否则查不到数据
-
Mycat并没有根据二阶段提交协议实现 XA事务,而是只保证 prepare 阶段数据一致性的 弱XA事务
下面这篇文章总结的很好,介绍了详细过程大家可以看看 -
-
ShardingSphere
开始时间2016左右,github 上提交的第一个release版本1.0.0 是在2016年2月
这也是一款数据库中间件,相比与mycat更灵活,支持XA强一致事务和柔性事务,mycat上存在的问题,它也存在一些,由无中心轻量化可集成到项目中的Sharding-JDBC(仅Java)、独立部署中心化的Sharding-Proxy(任意语言)和Sharding-Sidecar(计划中)这3款产品组成。现在由Apache孵化,目前有人维护 -
kingshard
github 上提交的第一个release版本1.0.0 是在2015年7月
由Go开发高性能MySQL Proxy项目,满足基本的读写分离的功能。
git地址:https://gitee.com/flikecn/kingshard -
POLARDB
阿里云的关系型云数据库2018年3月商用上线
现在大量的企业在用阿里云的产品, 阿里云的RDS关系型数据库使用者也特别多。 从RDS升级到POLARDB非常顺畅,省去了数据库中间件,分库分表,读写分离这些事情都能在控制台操作,由阿里云进行运维,更省心。显然比招聘更厉害的程序员更实惠。 从商业的角度来讲更合适。 -
后续
Apache ShardingSphere负责人张亮在知乎中回帖表示:ShardingSphere会继续维护升级,关系型数据库有存在的意义,数据库中间件并不是个伪需求。
当然结合业务做还是很重要的,没有最好的方式只有最适合的方式。架构师在技术通达的同时结合业务能写出更优的方案。比如一个订单表,订单号和时间戳有关系(比如雪花算法)按照订单创建时间来分表,可以分月表或日表,这样通过订单号能快速算出落在哪个表,在按时间查询或统计的时候能快速计算到相关的表中查询。
参考文章
https://www.zhihu.com/question/352256403/answer/878523206
https://blog.youkuaiyun.com/wt077521/article/details/80469015

















 4103
4103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









