







 本文详细介绍了如何使用coco-annotator进行关键点标注,从创建类别、关键点到导出数据集。接着,补充了缺失的info和licenses字段,并分割数据集为训练集和测试集。最后,计算了数据集的mean和std值,完成了数据集的准备工作。附带了相关代码文件链接。
本文详细介绍了如何使用coco-annotator进行关键点标注,从创建类别、关键点到导出数据集。接着,补充了缺失的info和licenses字段,并分割数据集为训练集和测试集。最后,计算了数据集的mean和std值,完成了数据集的准备工作。附带了相关代码文件链接。
COCO KeyPoints关键点数据集准备
概述
网上搜了一圈,coco关键点数据集准备的内容比较少,这里写一篇完成的标注流程到数据集准备的文章,以备后忘
标注工具
coco官方标注工具: coco–annotator
https://github.com/jsbroks/coco-annotator
标注过程

这里注意category_id 最好为1 ,否则会有不必要的麻烦 “category_id”: 1
标注流程
1、创建类别
2、 创建关键点名称
3、创建关键点之间连线关系
4、选择一张图片
5、标注待识别目标识别矩形框
6、在框内标注关键点keyPoints
7、标注下一张图片
标注完成之后, 导出数据集
导出结果在 coco–annotator/datasets/数据集名字/. exports/ 文件夹里


ps: 数据集也可以直接在web页面上点击下载
数据集准备
完善数据集
coco数据集标准字段
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation],
}
导出的数据集默认是没有 info字段和licenses 字段的,所以我们在数据集的json文件(coco-1613789462.5181398.json)自己加上这两个字段, 如下:
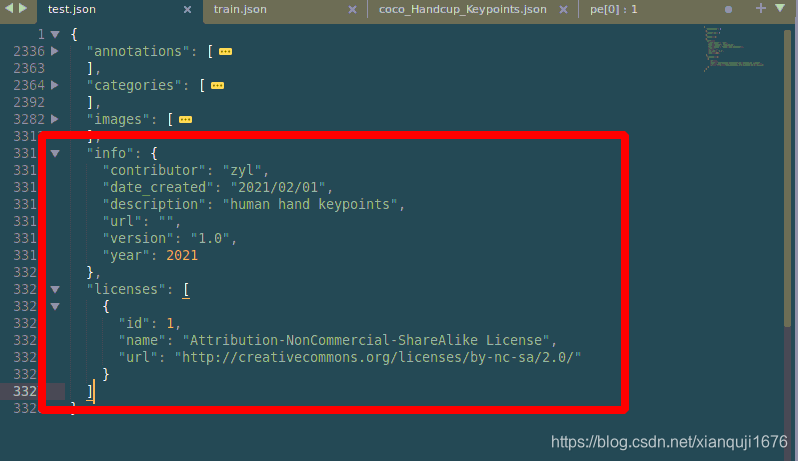
字段如下:
"info": {
"contributor": "zyl",
"date_created": "2021/02/01",
"description": "human hand keypoints",
"url": "",
"version": "1.0",
"year": 2021
},
"licenses": [
{
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License",
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/"
}
]
分割数据集为训练集和测试集
如下,三个文件放同一个目录

修改splitCoco.sh 文件中的文件名为自己的json标注文件路径,运行
./splitCoco.sh
执行 得到训练集文件和测试集文件
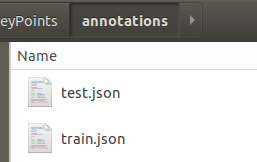
test.json
train.json
图片文件训练集和验证集区分
我们标注的图像是放在一个文件夹里的,这里需要区分成两个文件夹 test2017/ 和 train2017/
ps:当然这里最简单的方法是把所有的图像分别拷贝到这两个目录, 即 test2017/ 和 train2017/ 里面都放所有的标注图像
分类可以通过pickUsedImg.py这个脚本进行分类,自己改改,这个代码看不懂这个文章也就不用往下看了。
最终得到的数据集
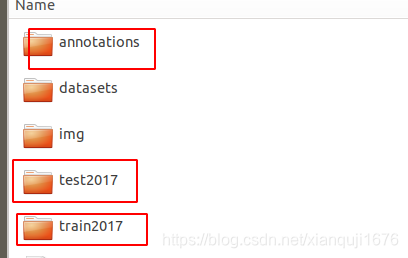
三个文件夹 annotations/ 、 test2017/ 、 train2017/
test2017 和train2017 分别是测试集和训练集图片
其中 annotations/文件夹如下:
计算数据集的mean 和std 值
参照dataset_mean_std.py 文件 路径修改为自己的数据集图片全集的目录
计算出的值如下:

到此,数据集准备完毕
数据集处理所需代码文件
链接: https://pan.baidu.com/s/1CmnnkthOXIjY4ndSRiqQ0g 提取码: cai9 复制这段内容后打开百度网盘手机App,操作更方便哦
–来自百度网盘超级会员v1的分享


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









