







 本文详细解析了MySQL中orderby引起的`usingfilesort`问题,介绍了information_schema的作用,包括optimizer_trace表,以及排序模式如rowid、全字段和优先队列排序。讲解了sort_buffer_size和max_length_for_sort_data的影响,并通过示例演示了如何通过trace追踪优化SQL执行。
本文详细解析了MySQL中orderby引起的`usingfilesort`问题,介绍了information_schema的作用,包括optimizer_trace表,以及排序模式如rowid、全字段和优先队列排序。讲解了sort_buffer_size和max_length_for_sort_data的影响,并通过示例演示了如何通过trace追踪优化SQL执行。
前言
关于mysql的排序,我们将从order by 关键字,产生的“using filesort”问题为锚点,为了可以更好的描述某些语句,我们需要先了解以下内容
information_schema
把 information_schema 看作是一个数据库,准确的说是信息数据库。他维护着MySQL服务器所有数据库的信息,例如数据库名,数据库的表,表栏的数据类型与访问权 限等。他实际上是视图,而不是基本表,所以我们看不到任何数据文件。
information_schema中的optimizer_trace表是MySQL 5.6引入的一项跟踪功能,它可以跟踪优化器做出的各种决策,我们可以看到更加详情的sql语句执行情况
order by 排序
- 按照某个字段排序,时间转换时间戳大小比较,字符(取首个字符比较)按照ascall字母表编排顺序比较,数字类型按照数字大小比较,多列按照第一列相等,则比较第二列的顺序比较,升序asc,降序desc
示例:
SELECT * FROM tableName ORDER BY field1 desc; – 单列,降序
SELECT * FROM tableName ORDER BY field1,field2 asc; – 多列,升序
- 使用函数field(field,str1,str2,str3)
示例:表xxx有字段id,name
数据:
1 | abc
2 | ba
3 | c
select * from xxx order by FIELD(name,“c”,“ba”); – name与“c”比,相同,不同默认返回至最前面
结果:
1 | abc
3 | c
2 | ba
using filesort
一般我们做sql优化时,explain执行计划字段extra会出现using filesort。filesort不代表就是文件(磁盘)排序,其实也有可能是内存排序,这个要由sort_buffer_size参数大小决定。MySQL内部实现排序主要有3种方式,rowid排序,全字段排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。
示例:
假设,建表:CREATE TABLE A(id int, name varchar(64), age int(10), sex varchar(64), PRIMARY KEY(id),key(name,age));
SELECT name,age,sex FROM A WHERE age>10 ORDER BY name;
rowid排序
把(rowid,name)取出(rowid是数据库中唯一标识一条记录的行号),加载到sort_buffer中(快速排序),若数据大,使用临时文件(归并排序)。排好序,再根据主键id回表查找name,age,sex数据,返回所有排序数据。
总结:两次io取数据;第二次io根据id取数据是随机io不是顺序io
全字段排序
把(name,age,sex)取出,直接加载到sort_buffer中(快速排序),若数据大,使用临时文件(归并排序)。排好序,直接返回所有排序数据。这样做,存放的(col1,col2,col3)数目要小于(id,col2),很容易导致sort buffer不够大,因此加入max_length_for_sort_data控制,大于该参数的排序单元,都走磁盘
总结:一次io;sort buffer压力增大,通过max_length_for_sort_data限制排序单元大小
优先队列排序
针对Order by limit offset,length语句采用优先队列排序,虽然仍然需要所有元素参与排序,但是只需要length个元组的sort buffer空间即可,对于length很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的length个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素
总结:针对Order by limit offset,length语句优化,只需要length个元组的sort buffer空间就能排序,避免走磁盘排序
trace追踪
trace追踪步骤
在TRACE的JSON中有三个步骤构成: join_preparation(准备阶段)、join_optimization(优化阶段)、join_execution(执行阶段),本文只以优化filesort为目的,关于JSON中各个字段更详细的介绍可查看文尾的参考文章
1.开启优化追踪
SET OPTIMIZER_TRACE="enabled=on",END_MARKERS_IN_JSON=off; -- set session 会话设置,END_MARKERS_IN_JSON关闭trace中注释
SET optimizer_trace_offset=-30, optimizer_trace_limit=30; -- 当offset大于0时,则会显示最早时间的从offset开始的limit个trace。
当offset小于0时,则会显示最晚的-offset开始的limit个trace,也就是说,只显示新的trace
2.执行sql
SELECT t.* FROM dc_recordseller t ORDER by create_time limit 10
3.查看优化追踪
select * from information_schema.optimizer_trace limit 30
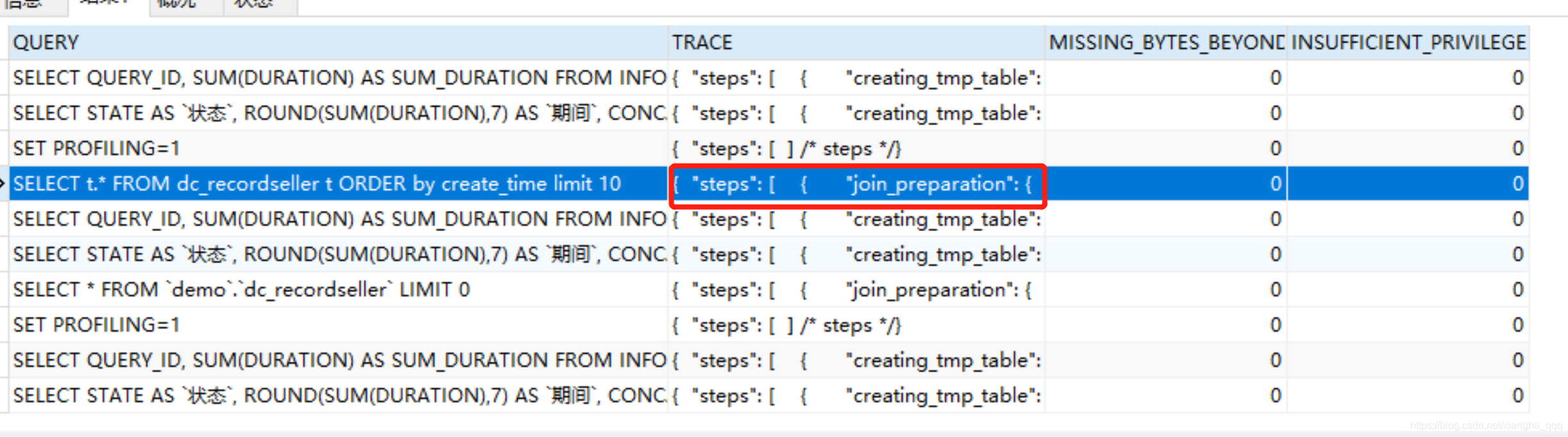
根据自己的sql语句查询到对应的追踪json

排序模式sort_mode
rowid 对应的是上文的rowid排序
additional_fields 对应的是全字段排序
packed_additional_fields 是"打包数据排序模式”,此排序模式改进仅仅在于将char和varchar字段存到sort buffer中,该模式下用户定义的varchar(255)会根据实际字符类型来sort_buffer中排序,例如dzx三个字符,只需要三个字符存储空间,相比原先的255个字符空间,可以压缩空间,使的sort_buffer可以排序更多的字段
三种排序模式无好坏之分,优化器会根据最少的耗时选出最适合的排序模式,例如:优化器发现使用第二种排序模式的sort_buffer空间小,只能用磁盘排序,耗时比第一种rowId排序还要慢,就会优先选择rowid排序。
sql优化实战
排序模式sort_mode
结论
1)MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序(内存)、归并排序(磁盘)和堆排序。
1)sort_buffer_size 决定内排,外排,内排就是走内存,外排就是采用归并排序走磁盘。
2)max_length_for_sort_data 决定 全字段排序(单路排序)还是,rowid排序(双路排序)。
参考
- http://blog.itpub.net/28218939/viewspace-2658978/
- 高性能MySQL_第3版(中文)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









