







如何使用 PEFT库 中 LoRA?
一、前言
本文章主要介绍使用 LoRA 对大模型进行高效参数微调,涉及内容:
- PEFT库 中 LoRA 模块使用;
- PEFT库 中 LoRA 模块 代码介绍;
- 在推理时如何先进行weight的合并在加载模型进行推理;涉及框架
# 以下配置可能会随时间变化,出了问题就去issue里面刨吧# 要相信你不是唯一一个大冤种!
accelerate
appdirs
loralib
bitsandbytes
black
black[jupyter]
datasets
fire
transformers>=4.28.0
git+https://github.com/huggingface/peft.git sentencepiece
gradio wandb
cpm-kernel
二、如何 配置 LoraConfig?
# 设置超参数及配置
LORA_R = 8
LORA_ALPHA = 16
LORA_DROPOUT = 0.05
TARGET_MODULES = [
"q_proj",
"v_proj",
]
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=TARGET_MODULES,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
- 参数介绍:
- r:lora的秩,矩阵A和矩阵B相连接的宽度,r<<d;
- lora_alpha:归一化超参数,lora参数 ΔWx 被以 α/r 归一化,以便减少改变r时需要重新训练的计算量;
- target_modules:lora的目标位置;
- merge_weights:eval模式中,是否将lora矩阵的值加到原有 W0 的值上;
- lora_dropout:lora层的dropout比率;
- fan_in_fan_out:只有应用在Conv1D层时置为True,其他情况False;
- bias: 是否可训练bias,none:均不可;all:均可;lora_only:只有lora部分的bias可训练;
- task_type:这是LoraConfig的父类PeftConfig中的参数,设定任务的类型;
- modules_to_save:除了lora部分之外,还有哪些层可以被训练,并且需要保存;
注意:target_modules中的作用目标名在不同模型中的名字是不一样的。query_key_value是在ChatGLM中的名字
三、模型 加入PEFT策略
模型加载 策略有哪些?
模型加载虽然很简单,这里涉及到2个时间换空间的大模型显存压缩技巧,主要说下load_in_8bit和prepare_model_for_int8_training。
from peft import get_peft_model, LoraConfig, prepare_model_for_int8_training, set_peft_model_state_dict
from transformers import AutoTokenizer, AutoModel
model = AutoModel.from_pretrained(
"THUDM/chatglm3-6b", load_in_8bit=True, torch_dtype=torch.float16, trust_remote_code=True, device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(
"THUDM/chatglm3-6b", trust_remote_code=True
)
model = prepare_model_for_int8_training(model)
模型显存占用的部分有哪些?
这里需要介绍一下两个模型显存占用的部分:
- 静态显存基本由模型参数量级决定;
- 动态显存在向前传播的过程中每个样本的每个神经元都会计算激活值并存储,用于向后传播时的梯度计算,这部分和batchsize以及参数量级相关;
模型显存占用 优化策略?
模型显存占用有以下两种方式:
- 8bit量化优化。该方式只要用于优化静态显存;
- 梯度检查优化。该方式只要用于优化动态显存;
8bit量化 优化策略?
参考:https://huggingface.co/blog/hf-bitsandbytes-integration
from_pretrained中的load_in_8bit参数是bitsandbytes库赋予的能力,会把加载模型转化成混合8bit的量化模型,注意这里的8bit模型量化只用于模型推理,通过量化optimizer state降低训练时显存的时8bit优化器是另一个功能不要搞混哟~
模型量化本质是对浮点参数进行压缩的同时,降低压缩带来的误差。 8-bit quantization是把原始FP32(4字节)压缩到Int8(1字节)也就是1/4的显存占用。如上加载后会发现除lora层外的多数层被转化成int类型如下:
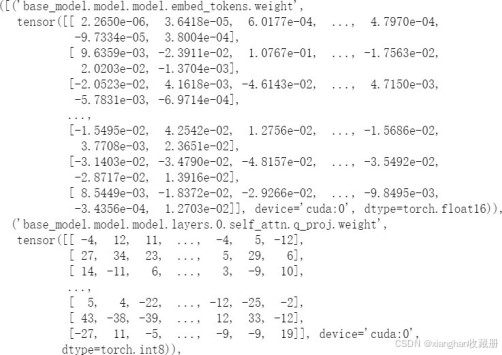
当然压缩方式肯定不是直接四舍五入,那样会带来巨大的精度压缩损失。常见的量化方案有absolute-maximum和zero-point,它们的差异只是rescale的方式不同,这里简单说下absmax,如下:

先寻找tensor矩阵的绝对值的最大值,并计算最大值到127的缩放因子,然后使用该缩放因子对整个tensor进行缩放后,再round到整数。这样就把浮点数映射到了INT8,逆向回到float的原理相同。
当然以上的缩放方案依旧存在精度损失,以及当矩阵中存在outlier时,这个精度损失会被放大,例如当tensor中绝大部分取值在1以下,有几个值在100+,则缩放后,所有1以下的tensor信息都会被round抹去。因此LLM.int8()的实现对outlier做了进一步的优化,把outlier和非outlier的矩阵分开计算,再把结果进行合并来降低outlier对精度的影响:
prepare_model_for_int8_training是对在Lora微调中使用LLM.int8()进行了适配用来提高训练的稳定性,主要包括:
- layer norm层保留FP32精度
- 输出层保留FP32精度保证解码时随机sample的差异性
梯度检查 优化策略?
参考:https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9
prepare_model_for_int8_training函数还做了一件事就是设置gradient_checkpointing=True,这是另一个时间换空间的技巧。
gradient checkpoint的实现是在向前传播的过程中使用torch.no_grad()不去存储中间激活值,降低动态显存的占用。而只是保存输入和激活函数,当进行反向传播的时候,会重新获取输入和激活函数计算激活值用于梯度计算。因此向前传播会计算两遍,所以需要更多的训练时间。
如何 向 模型 加入PEFT策略?
其实lora微调的代码本身并不复杂,相反是如何加速大模型训练,降低显存占用的一些技巧大家可能不太熟悉。模型初始化代码如下,get_peft_model会初始化PeftModel把原模型作为base模型,并在各个self-attention层加入lora层,同时改写模型forward的计算方式。
# 加入PEFT策略
model = get_peft_model(model, config)
model = model.to(device)
model.config.use_cache = False
注:use_cache设置为False,是因为和gradient checkpoint存在冲突。因为use_cache是对解码速度的优化,在解码器解码时,存储每一步输出的hidden-state用于下一步的输入,而因为开启了gradient checkpoint,中间激活值不会存储,因此use_cahe=False。其实#21737已经加入了参数检查,这里设置只是为了不输出warning。
四、PEFT库 中 LoRA 模块 代码介绍
PEFT库 中 LoRA 模块 整体实现思路
具体 PEFT 包装 包装,结合PEFT模块的源码,来看一下LORA是如何实现的。
在PEFT模块中,[peft_model.py]{.underline}中的PeftModel类是一个总控类,用于模型的读取保存等功能,继承了transformers中的Mixin类,我们主要来看LORA的实现:
代码位置:https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora.py
class LoraModel(torch.nn.Module):
def init (self, config, model):
super(). init ()
self.peft_config = config
self.model = model
self._find_and_replace()
mark_only_lora_as_trainable(self.model, self.peft_config.bias)
self.forward = self.model.forward
从构造方法可以看出,这个类在创建的时候主要做了两步:
- 第一步:self._find_and_replace()。找到所有需要加入lora策略的层,例如q_proj,把它们替换成lora模式;
- 第二步:mark_only_lora_as_trainable([self.mode]{.underline}l, [self.peft_config.bias]{.underline})。保留lora部分的参数可训练,其余参数全都固定下来不动;
PEFT库 中 LoRA 模块 _find_and_replace() 实现思路
_find_and_replace() 实现思路:
- 找到需要的做lora的层:
# 其中的target_modules在上面的例子中就是"q_proj","v_proj"
# 这一步就是找到模型的各个组件中,名字里带"q_proj","v_proj"的
target_module_found = re.fullmatch(self.peft_config.target_modules, key)
- 对于每一个找到的目标层,创建一个新的lora层:
# 注意这里的Linear是在该py中新建的类,不是torch的Linear
new_module = Linear(target.in_features, target.out_features, bias=bias, **kwargs)
- 调用_replace_module方法替换掉原来的linear:
self._replace_module(parent, target_name, new_module, target)
注:其中这个replace的方法并不复杂,就是把原来的weight和bias赋给新创建的module,然后再分配到指定的设备上:
def _replace_module(self, parent_module, child_name, new_module, old_module):
setattr(parent_module, child_name, new_module)
new_module.weight = old_module.weight
if old_module.bias is not None:
new_module.bias = old_module.bias
if getattr(old_module, "state", None) is not None:
new_module.state = old_module.state
new_module.to(old_module.weight.device)
# dispatch to correct device
for name, module in new_module.named_modules():
if "lora_" in name:
module.to(old_module.weight.device)
PEFT库 中 Lora层的 实现思路
基类 LoraLayer 实现
Lora的基类,可以看出这个类就是用来构造Lora的各种超参数用:
class LoraLayer:
def init (
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.0:
self.lora_dropout = nn.Dropout(p& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











