




 本文详细介绍了哈希表的基本概念,包括其数组本质和链地址存储方式。通过一个具体的例子展示了如何插入和删除元素,并给出了哈希函数的几种常见方法。此外,还提供了哈希表的初始化、销毁、查找、插入、删除和遍历等操作的C语言实现。最后,文章探讨了将哈希表替换为B树的可能性。
本文详细介绍了哈希表的基本概念,包括其数组本质和链地址存储方式。通过一个具体的例子展示了如何插入和删除元素,并给出了哈希函数的几种常见方法。此外,还提供了哈希表的初始化、销毁、查找、插入、删除和遍历等操作的C语言实现。最后,文章探讨了将哈希表替换为B树的可能性。
各位小伙伴,新年快乐。
哈希表,本质上是数组,而链地址就是存放了链表的数组。
借用哈希函数对某个数进行适当运算求得该数的哈希值,在根据这个哈希值对哈希表进行查找插入删除操作。
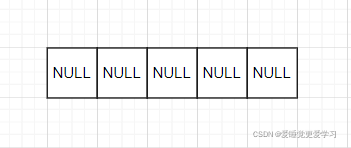
假设这是一个哈希表H,容量为5,长度为0;五个指针全部为NULL;
首先我们有一个数:3;假设其求得的哈希值为2,如图所示:
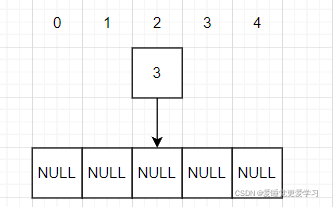
然后再令3成为这个存放这五个链表的数组中,第三个链表的,第一个结点。
如图所示:
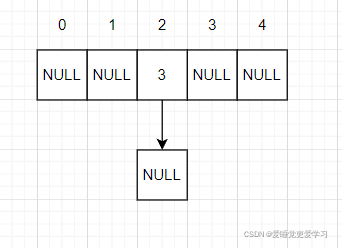
这就是插入,删除也可借鉴单链表的操作。
下面来看怎么实现的
目录
预先要引用的头文件以及宏定义
#include<stdio.h>
#include<iostream>
//
//using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define UNSUCCESS 0
#define SUCCESS 1
typedef int ElemType;
typedef int Status;
typedef int KeyType;所使用哈希表的结构
//(链地址)
typedef struct {
KeyType Key;
//这里可以存放其他数据
}RecordType, RcdType;
typedef struct Node { //其实这个指针就是链表
RcdType r;
struct Node* next;
}Node;
typedef struct {
Node** rcd; //(指向指针的指针)存放指针的数组
int size; //哈希表的容量
int count; //当前表中含有的记录个数
int(*hash)(KeyType key, int hashSize); //函数指针变量,选取哈希函数
}HashTable;所使用的哈希函数
int hash(int key, int hashSize)
{//哈希函数,hashSize为地址空间长度(哈希表的容量)
return (3 * key) % hashSize;
}哈希函数可以有很多种
1,直接定址法,你这个数是98,那里就到H.rcd[98]里面去,直接。hash = 98
2,除留余数法,hash = 关键字%(某个你中意的数(一般是哈希表的容量))也是我选择的。
3,数字分析法,
4,折叠法,
5,平方取中法,
等。3,4,5大家有兴趣就搜一下,我不会讲。
其基本操作接口
Status InitHash(HashTable& H, int size, int(*hash)(KeyType, int)); //初始化哈希表
Status DestroyHash(HashTable& H); //销毁哈希表
Node* SearchHash(HashTable H, KeyType key); //查找
Status InsertHash(HashTable& H, RcdType e); //插入
Status DeleteHash(HashTable& H, KeyType key, RcdType& e); //删除
void HashTraverse(HashTable H); //遍历初始化哈希表
Status InitHash(HashTable& H, int size, int(*hash)(KeyType, int))
{
H.rcd = (Node**)malloc(size*sizeof(Node*));
if (H.rcd != NULL)
{
for (int i = 0; i < size; i++)
{
H.rcd[i] = NULL;
}
H.size = size;
H.hash = hash;
H.count = 0;
return OK;
}
else
{
return OVERFLOW;
}
}销毁哈希表
Status DestroyHash(HashTable& H)
{
if (H.rcd != NULL)
{
Node* np, * nt;
for (int i = 0; i < H.size; i++)
{
np = H.rcd[i];
while (np != NULL)
{
nt = np;
np = np->next;
free(nt);
}
}
H.size = 0;
H.count = 0;
H.hash = NULL;
return OK;
}
else
{
return OVERFLOW;
}
}查找
Node* SearchHash(HashTable H, KeyType key)
{
int p = H.hash(key, H.size);
Node* np;
for (np = H.rcd[p]; np != NULL; np = np->next)
{
if (np->r.Key == key)return np;
}
return NULL;
}插入
Status InsertHash(HashTable& H, RcdType e)
{
int p;
Node* np;
np = SearchHash(H, e.Key);
if (np == NULL)
{
p = H.hash(e.Key, H.size);
np = (Node*)malloc(sizeof(Node));
if (np != NULL)
{
np->r = e;
np->next = H.rcd[p];
H.rcd[p] = np;
H.count++;
return OK;
}
else
{
return OVERFLOW;
}
}
else
{
return ERROR;
}
}删除
Status DeleteHash(HashTable& H, KeyType key, RcdType& e)
{
Node* n;
n = SearchHash(H, key);
if (n != NULL)
{
int p = H.hash(key, H.size);
Node* np, * nq;
np = H.rcd[p];
nq = NULL;
while (np != NULL)
{
if (np->r.Key != key)
{
nq = np;
np = np->next;
}
else
{
e = np->r;
if (nq == NULL)//表头
{
H.rcd[p] = np->next;
}
else//不是表头
{
nq->next = np->next;
}
break;
}
}
H.count--;
free(np);
return OK;
}
else
{
return ERROR;
}
}遍历
void HashTraverse(HashTable H)
{
if (H.rcd != NULL)
{
Node* np, * nq;
for (int i = 0; i < H.size; i++)
{
np = H.rcd[i];
if (np == NULL)
{
printf(" #");
}
else
{
while (np)
{
printf("%3d", np->r.Key);
np = np->next;
}
}
printf("\n");
}
}
}一些接口的测试
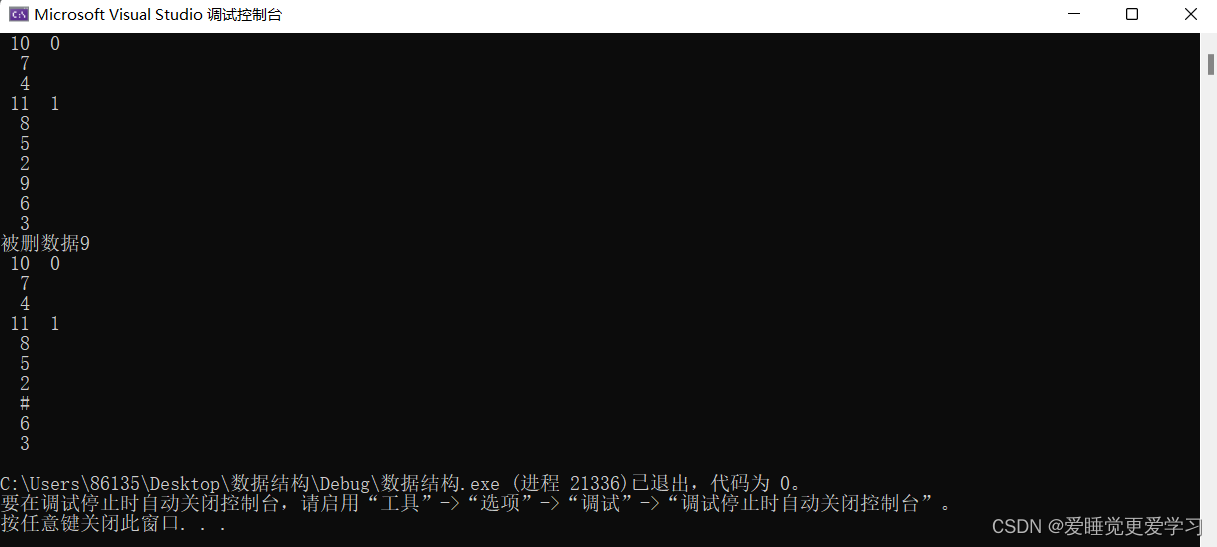
int main()
{
HashTable H;
InitHash(H, 10, hash);
for (int i = 0; i < 12; i++)
{
RcdType e;
e.Key = i;
InsertHash(H, e);
}
HashTraverse(H);
RcdType e1;
DeleteHash(H, 9, e1);
printf("被删数据%d\n", e1.Key);
HashTraverse(H);
DestroyHash(H);
}
其实想想看,如果他不是链表,是棵B树呢!!!,存放B树的数组,哈哈哈哈哈哈。


















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











