






看B站视频机器学习入门过程中对感觉重要的点进行记录。
线性回归问题 采用梯度下降方法 原理
似然函数
 公式(1)中角标i代码第几个样本,θ表示我们我们要求解的权重 。
公式(1)中角标i代码第几个样本,θ表示我们我们要求解的权重 。
公式(2)表示误差项ε(的概率)遵循高斯分布(标准正态分布)。
带入后,成了一个关于θ的函数,纵坐标还是误差项ε的概率,θ成了自变量,其他都可知,y是样本标签,x是样本特征值。

将所有样本带入并累乘得到似然函数,经过对数化简。

我们的目的是想让误差项ε越小越好,这样得到的线性模型预测就越准确;经过化简和转化又因为之前转化,得到初步的损失/目标/似然函数J(θ),并让其越大越好,这样ε才能越来越小,所以现在的目的转化为求J(θ)的极值点。

接着化简,这就是高数求极值点的方法了,求偏导等于0,但由于数据量太大,以矩阵的形式表示,我们在现实中不可能求得出解,所以接下来就有了我们的优化算法梯度下降,一步一步去接近正确的解。
梯度下降



现状目的又回到了怎么才能让目标函数**J(θ)**取到最大值上了。
已知条件:
- 一个已知的关于θ的函数
- 目的是求极值点,但是不能直接解
- 函数里的θ是一个一维矩阵,即每类特征值都对应着一个小θ,即权重;展开后形如第二个图。
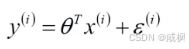
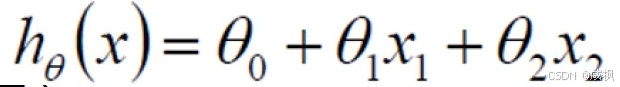
方法
初始时所有小θ给一个初始值,然后对每个小θ求偏导求得梯度(函数变化最快的方向),沿着梯度的反方向走一小步(离极值点处更接近一点),表现方式就是下图这个公式。
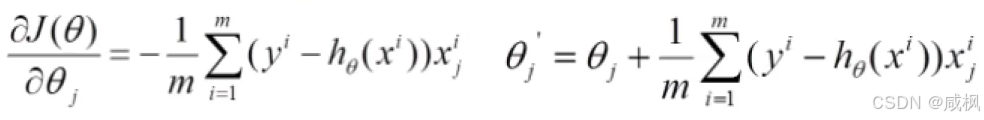
然后循环迭代多次,最终到达极值点处;关于怎么判断是否到达极值点?下面是我查询到的一些方法:
- 预设迭代次数:
最简单的方法是事先设定一个固定的迭代次数。这种方法简单,但不总是有效,因为它不依赖于函数的实际行为。 - 容忍度(Tolerance):
设置一个容忍度阈值,当梯度的模长(即梯度向量的范数)小于这个阈值时,可以认为已经接近极值点。这种方法依赖于梯度的大小,而不是迭代次数。 - 学习率衰减(Learning Rate Decay):
随着迭代的进行,逐渐减小学习率。当学习率减小到一定程度时,权重更新的幅度会非常小,此时可以认为已经接近极值点。 - 梯度范数:
监控梯度向量的范数。如果梯度范数非常小,接近于零,那么可以认为已经找到了极值点。 - 目标函数值的变化:
监控目标函数值的变化。如果连续几次迭代中目标函数值的变化非常小,可以认为已经接近极值点。 - 早停法(Early Stopping):
在训练过程中使用一个验证集来评估模型的性能。如果验证集上的性能在连续几次迭代中没有显著提升,那么可以停止迭代。 - 使用更复杂的优化算法:
有些优化算法(如Adam、RMSprop等)自带调整学习率的机制,可以在训练过程中自动调整学习率,从而更有效地逼近极值点。 - 曲线拟合:
记录每次迭代的目标函数值,并尝试拟合这些点以预测函数值的下降趋势。如果预测显示函数值不再显著下降,可以停止迭代。 - 时间限制:
设置一个时间限制,当训练时间超过这个限制时,停止迭代。
在实际应用中,通常会结合多种策略来确定何时停止迭代。例如,可以同时设置容忍度阈值和预设迭代次数,当任一条件满足时停止迭代。这样可以在保证找到极值点的同时,避免无休止的迭代。

















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









