




Sequential Decision Making
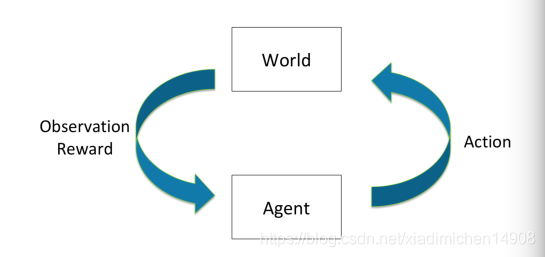
类似一个反馈系统
Agent 是执行机构如机器人
observation是agent的观察
Action 是Agent能够采取的动作反应
Reward是环境给出的反馈
Markov Assumption
State
S
t
S_t
St is Markov if and only if :
p
(
s
t
+
1
∣
s
t
,
a
t
)
=
p
(
s
t
+
1
∣
h
t
,
a
t
)
p(s_{t+1}|s_t,a_t) = p(s_{t+1}|h_t,a_t)
p(st+1∣st,at)=p(st+1∣ht,at)
未来的状态只与当前时刻的状态
S
t
S_t
St 有关, 而与过去的状态
{
S
1
,
.
.
.
,
S
t
−
1
}
\{S1, ... , S_{t-1}\}
{S1,...,St−1} 无关
- Full Observability : Markov Decision Process(MDP)
- Partial Observability: Partially Observable Markov Decision Process(POMDP)
Sequential Decision Process
- Deterministic(决定性)
- Stochastic(概率性)

强化学习算法通常有: - Model:表示环境对agent的action如何反应
- Policy: 将agent的状态映射到action的函数
- Value function: 在某个确定的policy下,在当前state和action下未来的收益
model
transition / dynamic model预测agent下一个状态
p
(
s
t
+
1
=
s
′
∣
s
t
=
s
,
a
t
=
a
)
p(s_{t+1}=s^{'}|s_t=s,a_t=a)
p(st+1=s′∣st=s,at=a)
reward model预测immediate reward
r
(
s
t
=
s
,
a
t
=
a
)
=
E
[
r
t
∣
s
t
=
s
,
a
t
=
a
]
r(s_t=s,a_t=a) = E[r_t|s_t=s,a_t=a]
r(st=s,at=a)=E[rt∣st=s,at=a]
policy
Policy π \pi π 决定了agent遵循何种规则,选择action
- Deterministic policy(确定性的)
π ( s ) = a \pi(s) = a π(s)=a - stochastic policy(概率性)
π ( a ∣ s ) = P r ( a t = a ∣ s t = s ) \pi(a|s) = Pr(a_t=a|s_t=s) π(a∣s)=Pr(at=a∣st=s)
value
- value function
V
π
V^{\pi}
Vπ
在某个具体的policy π \pi π下,未来reward的期望
V π ( s t = s ) = E π [ r t + γ r t + 1 + γ 2 r t + 2 + γ 3 r t + 3 + . . . ∣ s t ] V^{\pi}(s_t = s) = E_{\pi}[r_t+\gamma r_{t+1}+\gamma^2r_{t+2}+\gamma^3r_{t+3}+...|s_t] Vπ(st=s)=Eπ[rt+γrt+1+γ2rt+2+γ3rt+3+...∣st] - γ \gamma γ衡量即刻的reward和未来的reward
- 能够评价state和action的好坏
- 通过比较不同的policy来决定如何act


















 3942
3942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









