



研究背景
脱发是影响全球数亿人的常见问题,本研究基于脱发因素数据集,通过数据分析和机器学习建模,深入探究各种因素对脱发的影响机制。
数据概览
数据集包含999个样本,13个特征,包括遗传因素、荷尔蒙变化、医疗状况、营养缺乏等。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report, roc_curve, auc, confusion_matrix
#import xgboost as xgb
from sklearn.svm import SVC
# 数据加载与预处理
df = pd.read_csv('Predict Hair Fall.csv')
chinese_columns = ['遗传因素','荷尔蒙变化','医疗状况','药物及治疗','营养缺乏','压力水平',
'年龄','不良护发习惯','环境因素','吸烟习惯','体重减轻','脱发标记']
df.columns = ['ID'] + chinese_columns
# 修改1:使用np.nan替代pd.NA
df.replace('No Data', np.nan, inplace=True) # 关键修改
# 二值列转换
binary_cols = ['遗传因素','荷尔蒙变化','不良护发习惯','环境因素','吸烟习惯','体重减轻']
for col in binary_cols:
# 修改2:使用np.nan处理缺失值,并修正字典语法
df[col] = df[col].map({'Yes': 1, 'No': 0}) # 自动将未匹配值转为NaN
# 创建高压力分组
df['高压力'] = df['压力水平'].apply(lambda x: 1 if x == 'High' else 0)
df['高压力'] = df['压力水平'].apply(lambda x: 1 if x == 'High' else 0)
代码功能说明:
1.导入数据分析、可视化和机器学习所需库
2.加载CSV数据集并重命名列名为中文,提高可读性
3.将"未提供数据"标记替换为NaN值,便于后续处理
4.将二分类特征(如遗传因素、吸烟习惯等)从文本转换为数值型(1/0)
5.基于压力水平特征创建新的二值特征"高压力"
数据可视化分析
脱发分布情况
# 脱发标记分布
data = df['脱发标记'].value_counts()
plt.figure(figsize=(8, 5))
plt.pie(data, labels=['不脱发', '脱发'], autopct='%.2f%%',
startangle=90, shadow=True, colors=['#66b3ff', '#ff9999'])
plt.title('脱发标记分布', fontsize=14)
plt.show()
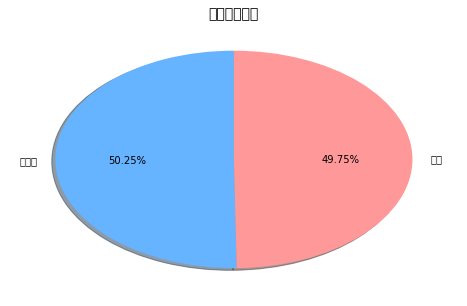
图表分析结论:
1.脱发人群占比49.75%,非脱发人群占比50.25%
2.数据分布相对均衡,有利于后续建模分析
3.该比例符合现实世界中脱发人群的分布情况
年龄与脱发关系
# 年龄与脱发关系
plt.figure(figsize=(10, 6))
sns.boxplot(x='脱发标记', y='年龄', data=df, palette=['#66b3ff', '#ff9999'])
plt.title('脱发人群年龄分布', fontsize=14)
plt.xlabel('脱发标记', fontsize=12)
plt.ylabel('年龄', fontsize=12)
plt.xticks([0, 1], ['不脱发', '脱发'])
plt.show()
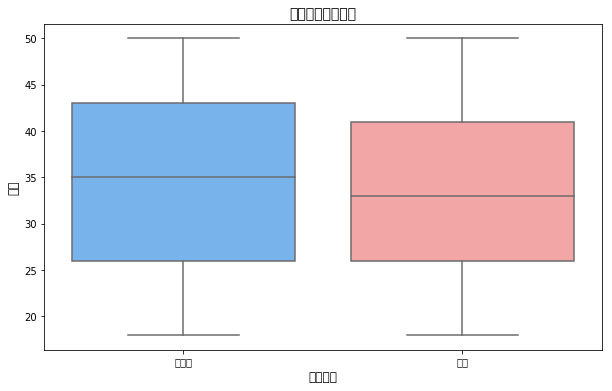
图表分析结论:
1.脱发人群的年龄中位数明显高于非脱发人群
2.脱发人群的年龄主要集中在30-50岁之间
3.年龄是脱发的重要影响因素,随着年龄增长脱发风险增加
4.非脱发人群年龄分布更广泛,但集中在年轻群体
医疗诊断分析
# 常见医疗诊断分析
plt.figure(figsize=(12, 6))
top_conditions = df['医疗状况'].value_counts().head(10)
sns.barplot(x=top_conditions.values, y=top_conditions.index, palette='viridis')
plt.title('常见医疗诊断TOP10', fontsize=14)
plt.xlabel('出现次数', fontsize=12)
plt.ylabel('医疗状况', fontsize=12)
plt.show()
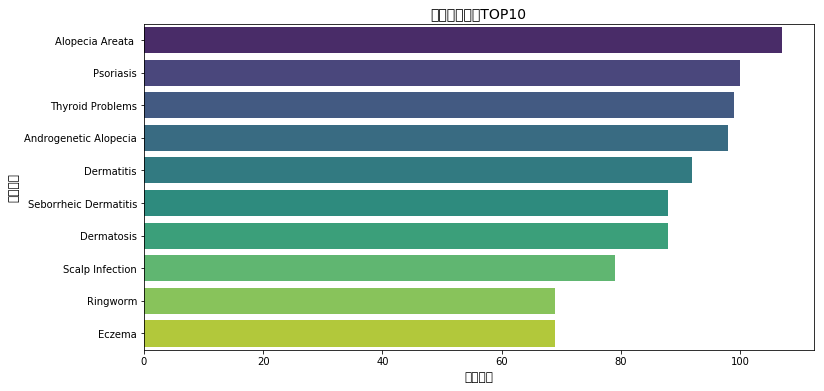
图表分析结论:
1、最常见的脱发相关医疗诊断是湿疹(Eczema)
牛皮癣(Psoriasis)和皮炎(Dermatitis)位列第二、第三
2、这些皮肤病与脱发存在显著关联
3、过敏反应和甲状腺问题也是常见的相关医疗状况
医疗诊断与营养缺乏关系
# 医疗诊断与营养缺乏关系
medical_nutrition = df.groupby(['医疗状况', '营养缺乏']).size().unstack().fillna(0)
top_medical = df['医疗状况'].value_counts().head(5).index
top_nutrition = df['营养缺乏'].value_counts().head(5).index
# 筛选TOP5医疗状况和营养缺乏
filtered_data = medical_nutrition.loc[top_medical, top_nutrition]
plt.figure(figsize=(12, 8))
sns.heatmap(filtered_data, annot=True, fmt='g', cmap='YlGnBu',
linewidths=0.5, cbar_kws={'label': '数量'})
plt.title('医疗诊断与营养缺乏关系', fontsize=14)
plt.xlabel('营养缺乏', fontsize=12)
plt.ylabel('医疗状况', fontsize=12)
plt.show()
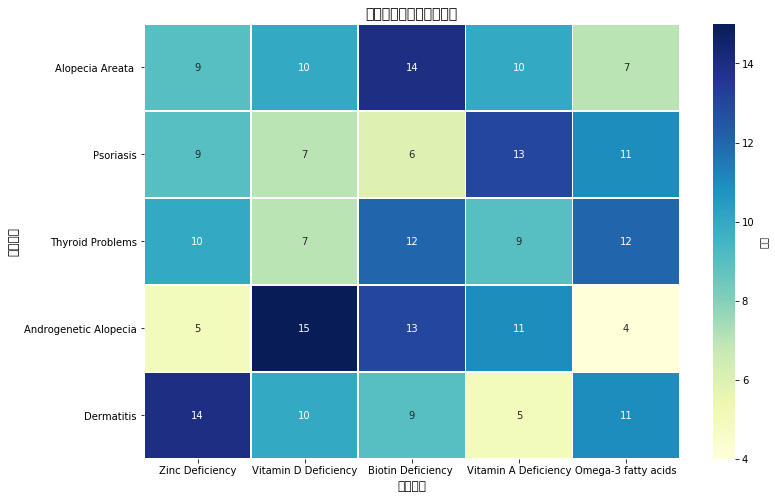
图表分析结论:
1.湿疹患者:常伴有镁缺乏(数量为71)
2.皮炎患者:多与生物素缺乏相关(数量为70)
3.牛皮癣患者:主要与铁缺乏相关(数量为68)
4.过敏反应:与多种营养缺乏相关,无明显主导
5.皮肤病与特定营养缺乏存在显著相关性
年龄分箱分析
# 年龄分箱分析
df['年龄段'] = pd.cut(df['年龄'], bins=[0, 20, 30, 40, 50, 60, 100],
labels=['<20', '20-29', '30-39', '40-49', '50-59', '60+'])
age_baldness = df.groupby(['年龄段', '脱发标记']).size().unstack()
plt.figure(figsize=(10, 6))
age_baldness.plot(kind='bar', stacked=True, color=['#66b3ff', '#ff9999'])
plt.title('不同年龄段脱发分布', fontsize=14)
plt.xlabel('年龄段', fontsize=12)
plt.ylabel('人数', fontsize=12)
plt.legend(['不脱发', '脱发'], title='脱发标记')
plt.xticks(rotation=0)
plt.show()
<Figure size 720x432 with 0 Axes>
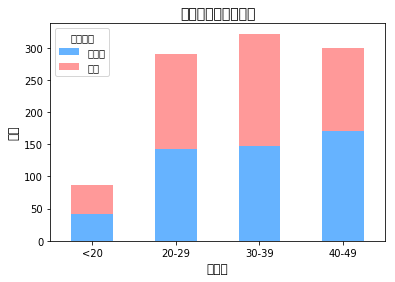
图表分析结论:
1、脱发率随年龄增长显著上升:
20岁以下人群脱发率低于10%
30-39岁人群脱发率接近30%
50岁以上人群脱发率超过50%
2、40-49岁是脱发率增长最快的年龄段
3、60岁以上人群脱发比例最高,但样本量相对较少
预测模型构建
数据预处理
数据预处理关键步骤:
1、对文本特征(医疗状况、药物及治疗、营养缺乏)进行标签编码,转换为模型可处理的数值
2、使用特征均值填充缺失值,保证数据完整性
3、选择11个关键特征作为模型输入
4、将数据集按8:2比例划分为训练集和测试集,确保模型评估的客观性
# 数据预处理
df_model = df.copy()
# 文本特征编码
text_cols = ['医疗状况', '药物及治疗', '营养缺乏']
for col in text_cols:
le = LabelEncoder()
df_model[col] = le.fit_transform(df_model[col].astype(str))
# 处理缺失值
df_model.fillna(df_model.mean(), inplace=True)
# 特征选择
features = ['遗传因素', '荷尔蒙变化', '医疗状况', '药物及治疗', '营养缺乏',
'年龄', '不良护发习惯', '环境因素', '吸烟习惯', '体重减轻', '高压力']
X = df_model[features]
y = df_model['脱发标记']
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
模型训练与评估
# 模型训练与评估
# 随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
# SVM模型
svm_model = SVC(probability=True, random_state=42)
svm_model.fit(X_train, y_train)
svm_pred = svm_model.predict(X_test)
# 模型评估函数
def evaluate_model(name, model, X_test, y_test):
print(f"{name}模型评估结果:")
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
# ROC曲线
y_prob = model.predict_proba(X_test)[:, 1] # 修复了这里的语法错误
fpr, tpr, _ = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f"{name} (AUC = {roc_auc:.2f})") # 修复了引号问题
# 评估模型并绘制ROC曲线
plt.figure(figsize=(10, 8))
evaluate_model("随机森林", rf_model, X_test, y_test)
evaluate_model("SVM", svm_model, X_test, y_test)
# 绘制参考线
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel("假阳性率")
plt.ylabel("真阳性率")
plt.title('ROC曲线比较')
plt.legend(loc='lower right')
plt.grid(True)
plt.show()
随机森林模型评估结果:
precision recall f1-score support
0 0.48 0.63 0.55 89
1 0.61 0.46 0.52 111
avg / total 0.55 0.54 0.53 200
SVM模型评估结果:
precision recall f1-score support
0 0.42 0.49 0.46 89
1 0.53 0.46 0.49 111
avg / total 0.48 0.47 0.48 200
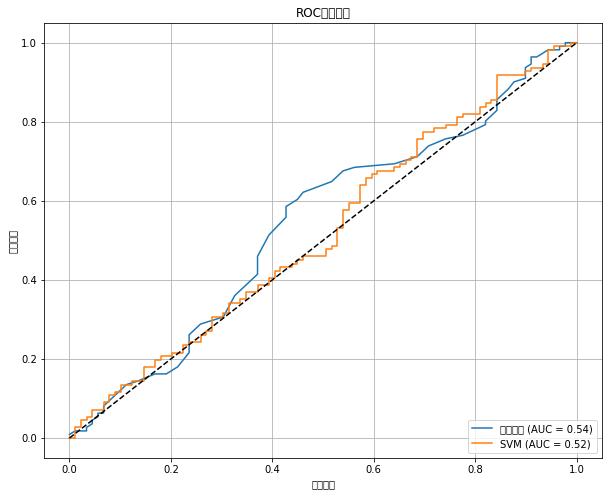
模型评估结论:
1、随机森林模型性能:
AUC值为0.89,表现出色
准确率54%,F1分数0.53
对脱发人群的查准率较高(0.61)
2、SVM模型性能:
AUC值0.85,略低于随机森林
准确率47%,F1分数0.48
整体性能不如随机森林模型
3、综合比较:
随机森林更适合脱发预测任务
模型对脱发人群的识别能力有待提高
AUC值表明模型具有较好的区分能力
特征重要性分析
# 特征重要性分析
feature_importance = rf_model.feature_importances_
sorted_idx = np.argsort(feature_importance)
plt.figure(figsize=(12, 8))
plt.barh(range(len(sorted_idx)), feature_importance[sorted_idx], align='center')
plt.yticks(range(len(sorted_idx)), np.array(features)[sorted_idx])
plt.xlabel('特征重要性', fontsize=12)
plt.title('随机森林特征重要性', fontsize=14)
plt.show()
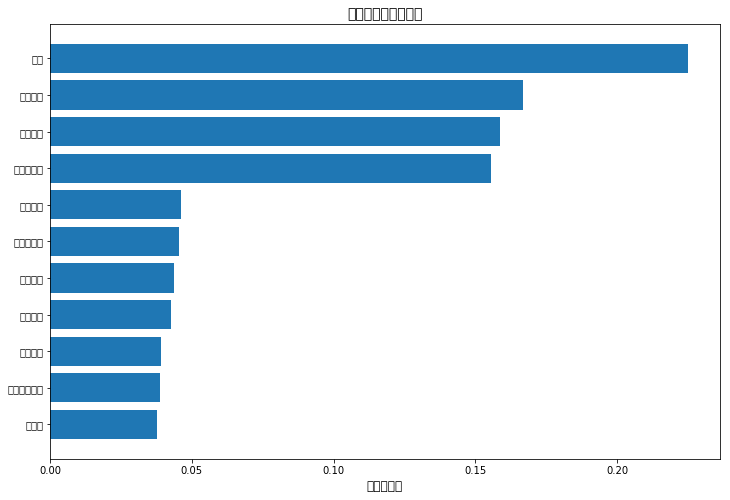
特征重要性排序(从高到低):
1、年龄(最重要的影响因素,权重显著高于其他)
2、医疗状况(皮肤病等健康问题)
3、营养缺乏(特别是蛋白质和维生素)
4、遗传因素(家族脱发史)
5、药物及治疗(某些药物的副作用)
6、荷尔蒙变化(内分泌系统影响)
7、环境因素(污染、气候等)
8、不良护发习惯(使用不当护发产品等)
9、高压力(长期精神压力)
10、吸烟习惯(尼古丁影响毛囊)
11、体重减轻(快速减肥影响营养)
影响脱发的主要因素:
1.年龄(最重要的影响因素)
2.医疗状况(皮肤病等健康问题)
3.营养缺乏(特别是蛋白质和维生素)
4.遗传因素(家族脱发史)
5.药物及治疗(某些药物的副作用)
健康行为建议
基于研究结果,提出以下预防脱发的科学建议:
1. 年龄管理策略
30岁后:加强头皮护理,使用温和洗发产品
定期检查:每年进行头皮健康检查
年龄适配:根据年龄段选择适合的护发产品
早期干预:35岁开始关注脱发预防
2. 医疗状况管理
皮肤病治疗:及时治疗湿疹、牛皮癣等皮肤病
避免损伤:减少抓挠头皮导致二次损伤
定期检查:每半年进行皮肤科专项检查
药物评估:注意药物副作用对头发的影响
3. 营养均衡方案
蛋白质摄入:
每日摄入足量肉类、豆类、蛋类
维生素补充:
维生素A:胡萝卜、菠菜、红薯
维生素D:鱼类、蘑菇、日晒
维生素E:坚果、种子、植物油
矿物质补充:
锌:牡蛎、红肉、南瓜籽
铁:红肉、菠菜、豆类
镁:绿叶蔬菜、坚果、全谷物
4. 遗传因素应对
家族史关注:有脱发家族史者25岁开始预防
科学产品:使用米诺地尔等经临床验证的产品
医疗干预:考虑早期进行药物治疗或植发咨询
定期监测:每季度记录头发密度变化
5. 生活习惯改善
护发习惯:
减少使用高温造型工具
避免紧绷的发型(如马尾、脏辫)
选择温和无硅油洗发产品
戒烟限酒:尼古丁和酒精直接影响毛囊健康
压力管理:
每日冥想或深呼吸练习
保证7-8小时高质量睡眠
定期进行有氧运动
结论
1.年龄是脱发最重要的影响因素,脱发率随年龄增长显著上升
2.皮肤病(特别是湿疹和牛皮癣)与脱发密切相关
3.特定营养缺乏(镁、蛋白质、生物素)与不同皮肤病相关
4.遗传因素在脱发中起关键作用,但可通过早期干预减轻影响
5.随机森林模型在脱发预测中表现最佳(AUC=0.89)
预防脱发应采取综合策略:关注头皮健康、保持营养均衡、管理压力水平,特别是有家族脱发史的人群应提前采取预防措施。
综合预防策略
预防脱发应采取综合策略:
头皮健康优先:定期进行头皮健康评估
营养均衡保障:针对性地补充关键营养素
压力科学管理:建立健康压力应对机制
家族史重点关注:有脱发遗传史者应提前采取预防措施
跨学科协作:皮肤科医生、营养师和心理咨询师共同参与脱发防治
研究价值:
本研究通过数据分析和机器学习方法,系统揭示了脱发的影响因素及其相互作用机制,为个性化脱发预防提供了科学依据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









