




 本文详细介绍了如何使用Pandas读取文本数据,包括读取CSV和自定义分隔符的数据,指定列名和索引,处理缺失值,以及逐块读取文件。此外,还涉及到数据写入文本格式、JSON数据处理、HTML和API数据的读取,以及Pandas库中的数据取样方法。
本文详细介绍了如何使用Pandas读取文本数据,包括读取CSV和自定义分隔符的数据,指定列名和索引,处理缺失值,以及逐块读取文件。此外,还涉及到数据写入文本格式、JSON数据处理、HTML和API数据的读取,以及Pandas库中的数据取样方法。
Pandas 读取文本数据
标签(空格分隔): python pandas
Pandas 读取文本数据
pandas解析函数

如果原始数据是有标题的

read_csv调用

read_table
这里可以指定seq=’\s+'等正则表达式来当分割符
如果列名比数据行数量少1,read_table会推断第一列是DataFrame的索引

指定列名
如果没有标题,那么可以自定义列名(names=[])或者分配默认列名(header=None)
pd.read_csv(path, header=Node)
pd.read_table(path, names=['a','b'])
指定索引
如果想要将指定列设置为DataFrame索引可以明确指定message该列放到索引位置或者通过index_col来指定"message",想要指定多列依次传入由列编号或者列名组成的列表
pd.read_csv(path, names=[], index_col=['key1', 'key2'])
跳过指定行
使用skiprows参数
pd.read_csv(path, skip_rows=[0, 2, 3])
缺失值处理
默认情况下Pandas会用一组经常出现标记值进行识别,如NA -1.#IND 以及NULL等,也就说把数据中出现这些数据的当初NaN缺失
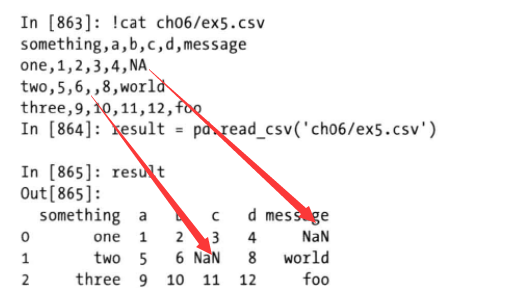
也可以使用na_values指定的表示缺失值的字符串
pd.read_csv(path, na_values=['NULL'])
还可以使用一个字典sentinels为不同列指定不同的表示缺失值的字符串

read_csv/read_table 参数解释



逐块读取文件
只想读取几行,使用nrows进行指定
pd.read_table(path, nrows=5)
要逐块读取文件,需要设置chunksize(行数).
read_csv返回TextParser对象让你可以根据chunksize对文件逐块迭代
如下图所示,可能这样能够提高效率?

将数据写到文本格式
如下图所示

- 用seq指定分隔符eg, seq=’|’
- 缺失值在输出会为空字符串,用na_seq='NULL’指定特定字符串
- path参数使用sys.stdout表示只输出
- 默认会输出行列标签,可以用index=False,header=False禁用
- 只输出部分列以及指定顺序,可以用cols=[‘a’, ‘b’]
手工处理分隔符格式
一个简单的处理例子如下

定义一个新读取写格式

JSON数据
可以通过json.loads即可将JSON字符串Python形式,json.dump将Python转为JSON格式
import json
result = jsons.loads(obj)
boj2 = jsons.dump(result)
XML和HTML:WEB收集信息
一个简单的读取HTML demo

links是上面获取的结果,这里links存的是对象的集合,要想获取URL等信息需要使用对象的的get方法
lnk = links[28]
lnk.get('herf')
lnk.text_content()
具体关于XML的后面自己看书吧
读取Execl
ExeclFile需要用到xlrd和openpyxl两个包,所以需要先安装,以下是创建一个ExeclFile实例以及使用parse读取到DataFrame
xls_file = pd.ExeclFile(path)
table = xls_file.parse('Sheet1')
使用HTML和API
许多网站可以通过JSON或其他格式提供公共的API,可以通过python访问这些api,其中比较简单的是request
比如在Twitter搜索"pyhton panda",可以发送一个gets请求
import requests
url = '...'
resp = requests.get(url)
# response对象text属性含有GET请求
# 许多返回的都是JSON字符串,我们需要加载到 pyhton 对象
import json
data = json.loads(resp.txt)
从数据中取样
利用Pandas库中的sample。
DataFrame.sample(n=None, frac=None, replace=False,weights=None, random_state=None, axis=None)
n是要抽取的行数。(例如n=20000时,抽取其中的2W行)
frac是抽取的比列。(有一些时候,我们并对具体抽取的行数不关系,我们想抽取其中的百分比,这个时候就可以选择使用frac,例如frac=0.8,就是抽取其中80%)
replace抽样后的数据是否代替原DataFrame()
weights这个是每个样本的权重,具体可以看官方文档说明。
random_state这个在之前的文章已经介绍过了。
axis是选择抽取数据的行还是列。axis=0的时是抽取行,axis=1时是抽取列(也就是说axis=1时,在列中随机抽取n列,在axis=0时,在行中随机抽取n行)

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









