







Hadoop生态介绍
一、Hadoop生态图解
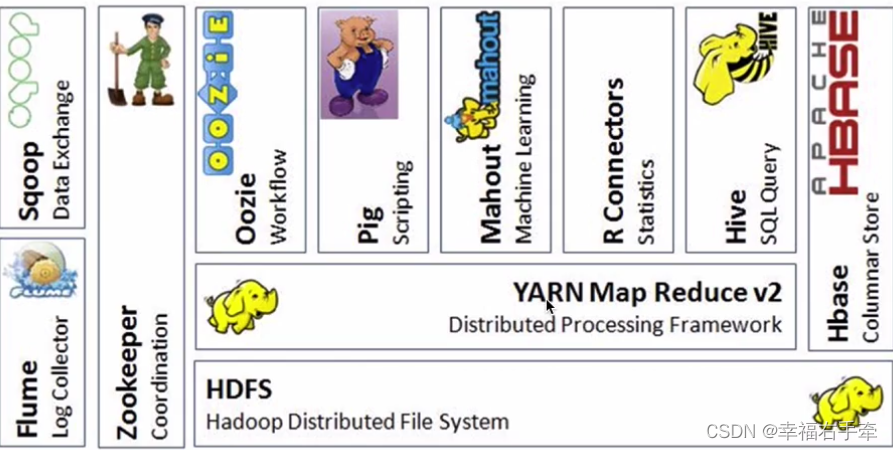
二、Hadoop各个组件介绍
(一)各个组件
1、hadoop是hive和hbase的基础,hive依赖hadoop,而hbase仅依赖hadoop的hdfs模块。
2、Hive:数据仓库。底层基于MapReduce,用于离线计算。
3、R:数据分析。
4、Mahoot:机器学习库,基本不用了。
5、Pig:脚本语言,类似于Hive。
6、Oozle:工作流引擎,管理作业执行顺序。
7、ZooKeeper:可以无感知的切换主节点。
8、Flume:日志收集框架。
9、Sqoop:数据交换框架。在关系型数据库(MySQL、oracle)和HDFS之间进行数据交换。
10、Hbase:分布式数据库,海量数据的查询,使用列式存储。MySQL使用行式存储。有happybase。用于实时计算。
11、Spark:基于内存的分布式计算框架。有pyspark。
(1)Spark core:对应于MapReduce。
(2)Spark sql:对应Hive。
(3)Spark streaming:准实时的流式计算,对应storm和flink。
(4)Spark ML:机器学习库。
12、Kafka:消息队列。
13、Storm:分布式的流式计算框架,不适合python操作。
14、Flink:分布式的流式计算框架。
(二)特点
2、特点:开源,社区活跃,涵盖大数据的方方面面,成熟。
3、版本选择:从Apache下载社区版,或者下载CDH版本。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









