




一、定义
Spark Streaming 是 Spark 的流式数据处理模块。Spark Streaming 支持的数据输入源有很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等。
二、DStream 和 Structured Streaming
Spark Streaming 使用离散化流(DStream)作为基本抽象。DStream 是一系列连续的 RDD,每个 RDD 代表一段时间内收集的数据。在 Spark Streaming 中,数据流被分成一系列批次,每个批次处理一段时间内的数据。
除了 DStream,Spark Streaming 还支持结构化流(Structured Streaming),这是从 Spark 2.0 开始引入的更高层次的 API。结构化流使用 DataFrame 和 Dataset API,并提供了更简单的编程模型和更好的性能。
2.1 离散化流(DStream)
2.1.1 核心概念
-
本质:一个 DStream 本质上是一系列连续的 RDD。每个 RDD 包含一个特定时间间隔内到达的数据。
-
时间片:Spark Streaming 将实时数据流按时间切分成小的批次(例如 1 秒或 2 秒)。每个批次的数据对应一个 RDD。
-
不可变性:和 RDD 一样,DStream 也是不可变的。任何转换操作都会生成一个新的
-
操作类型:DStream 提供了许多与 RDD 相似的操作,如 map、reduce、join 等,同时还提供了与时间相关的操作,如滑动窗口操作。
2.1.2 创建方式
// 方式1:通过 SparkConf 创建
val conf = new SparkConf().setAppName("StreamingApp").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5)) // 5秒批处理间隔
// 方式2:通过已有的 SparkContext 创建
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
2.1.3 特点
-
优点:
-
基于成熟的 RDD 模型,与 Spark Core 紧密结合。
-
提供细粒度的控制,特别是通过
foreachRDD。
-
-
缺点:
-
处理延迟较高:因为是微批次处理,延迟通常在秒级。
-
API 级别较低:开发者需要自己处理与时间相关的逻辑(如事件时间、延迟数据)。
-
不感知执行计划:无法像 DataFrame 一样进行 Catalyst 优化。
-
2.2 结构化流(Structured Streaming)
2.2.1 核心概念
-
结构化流是构建在 Spark SQL 引擎上的流处理引擎,使用 Dataset/DataFrame API。
-
它将实时数据流视为一张无界表,新的数据不断追加到这张表中。
-
支持基于事件时间的处理、水位线(watermark)处理延迟数据、以及容错状态管理。
-
输出模式包括追加模式、更新模式和完整模式。
2.2.2 创建方式
// 使用 SparkSession(与 Spark SQL 相同)
val spark = SparkSession.builder()
.appName("StructuredStreamingApp")
.master("local[2]")
.config("spark.sql.streaming.schemaInference", "true")
.config("spark.sql.streaming.checkpointLocation", "/checkpoint/path")
.getOrCreate()
2.2.3 关键特性
-
事件时间与水位线
-
事件时间:数据本身产生的时间戳,而不是到达系统的时间。这对于处理乱序和延迟的数据至关重要。
-
水位线:一个机制,用于告诉 Spark 可以“等待”延迟数据多久。当处理基于事件时间的窗口时,水位线让引擎可以跟踪当前处理的事件时间,并自动清理旧的状态。
-
-
输出模式
-
Append 模式:只将窗口中最终的结果输出一次。这是默认模式。
-
Update 模式:以增量方式输出,每当一条记录被更新就输出一次。
-
Complete 模式:每次触发后,输出完整的计算结果(适用于有状态操作,如聚合)。
-
-
端到端 exactly-once 语义
Structured Streaming 通过与源端和输出端的集成,可以保证在发生故障时,每条记录被精确处理一次,不丢不重。
2.3 总结对比
| 特性 | DStream (微批次) | Structured Streaming |
|---|---|---|
| 编程模型 | 基于 RDD 的低级 API | 基于 DataFrame/Dataset 的高级声明式 API |
| API 级别 | 较低级,需手动处理状态、窗口 | 较高级,内置对事件时间、窗口、水位线的支持 |
| 性能优化 | 无自动优化 | 利用 Spark SQL 的 Catalyst 优化器和 Tungsten 执行引擎 |
| 延迟 | 秒级(微批次) | 可达毫秒级(微批次),还有更低延迟的连续处理模式 |
| 语义保证 | At-least-once 或 exactly-once(需精心设计) | 端到端的 Exactly-once 语义 |
| 学习曲线 | 需要理解 RDD 和流处理概念 | 对于熟悉 Spark SQL 的开发者更简单 |
| 推荐程度 | 遗留系统,需要极细粒度控制时使用 | 新项目的首选,功能更强大,开发更简单 |
三、Spark Streaming 架构
3.1 架构图
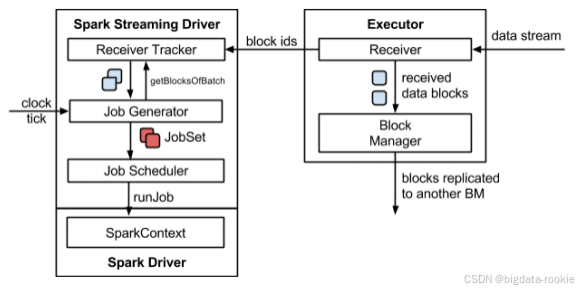
3.2 背压机制
在 Spark 1.5 之后,引入了背压机制。系统能够自动根据当前的处理能力动态调整接收数据的速率,防止在流量高峰时内存被撑爆。根据 Job Scheduler 反馈作业的执行信息来动态调整 Receiver 数据接收速率。
通过属性“spark.streaming.backpressure.enabled”来控制是否启用 backpressure 机制,默认值 false,即不启用。


















 2866
2866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









