




 本文深入探讨HashMap的内部机制,包括为何长度为2的幂次方、多线程下的死循环问题、底层实现细节及扩容机制。从JDK1.7到1.8的变化,解析红黑树引入的原因及扩容策略。
本文深入探讨HashMap的内部机制,包括为何长度为2的幂次方、多线程下的死循环问题、底层实现细节及扩容机制。从JDK1.7到1.8的变化,解析红黑树引入的原因及扩容策略。
本文着重介绍关于Hashmap的常见面试题,读者需对HashMap有基本的了解
1.HashMap长度为什么是2的幂次方
我们利用HashMap的hash对数组长度进行取模运算得到数组下标再存放到对应下标的数组中。1.7以前是直接进行%取模,在1.8优化成了位运算,**取模(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(即hash%length==hash&(length-1)前提是 length 是2的 n 次方)**并且采用二进制位操作&,相对于%能够提高运算效率;另一方面,如果length是奇数,如15即1111那么减一之后再和hashcode与运算最后一位就是0,这样下标为奇数的位置就不能存放元素,极大的浪费了空间;这就解释了 HashMap 的长度为什么是2的幂次方。
2.HashMap多线程操作导致死循环问题
HashMap在并发的情况下Rehash会造成元素之间形成循环链表,这时调用get方法就会死循环。因为1.7resize是采用的头插法,在扩容时对同一下标的链表元素会进行倒置于是在并发时造成死循环;而在1.8后采用的是尾插法,链表不会反转而是按照原来的顺序,解决了死循环问题;但在并发的情况下还是不建议使用HashMap,可以用ConcurrentHashMap代替。
3.HashMap的底层实现
HashMap底层结构在jdk1.7和1.8有较大的改变
1.7:数组+链表
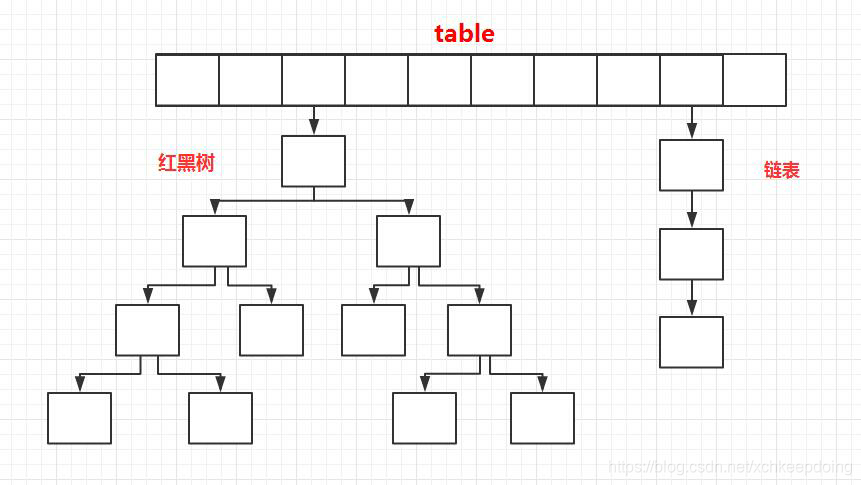
1.8:数组+链表+红黑树(关于红黑树可以戳这里 看完必懂红黑树
JDK1.8 之前 HashMap 底层是数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数(就是hash函数,将key的hashcode通过无符号右移然后按位异或;这么做是防止hashcode方法实现的较差,两个对象会出现相同的hashcode产生hash冲突)处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。哈希冲突严重时,某一下标链表过长,则查询效率降低;于是在1.8引入了红黑树来优化查询,将查询效率从O(n)提升到了O(logn)。
解决hash冲突一般有开放地址法、链地址法(俗称拉链法)、再哈希法、建立公共溢出区
下面是拉链法的图示:
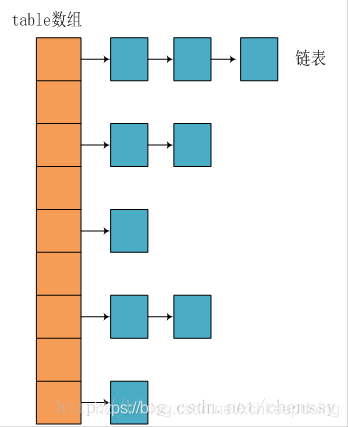
相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
4.扩容机制
我们先看1.7的源码
1 void resize(int newCapacity) { //传入新的容量
2 Entry[] oldTable = table; //引用扩容前的Entry数组
3 int oldCapacity = oldTable.length;
4 if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
5 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
6 return;
7 }
8
9 Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
10 transfer(newTable); //!!将数据转移到新的Entry数组里
11 table = newTable; //HashMap的table属性引用新的Entry数组
12 threshold = (int)(newCapacity * loadFactor);//修改阈值
13 }
1 void transfer(Entry[] newTable) {
2 Entry[] src = table; //src引用了旧的Entry数组
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
5 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
6 if (e != null) {
7 src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
8 do {
9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
11 e.next = newTable[i]; //标记[1]
12 newTable[i] = e; //将元素放在数组上
13 e = next; //访问下一个Entry链上的元素
14 } while (e != null);
15 }
16 }
17 }
先说几个参数的含义,capacity是数组的容量默认为16;loadFactor是负载因子默认为0.75f,代表元素占数组的多少,默认为0.75也就是3/4;threshold=capacity*loadFactor;threshold是一个阈值,一旦数组中元素若是超过它,将会进行扩容。
扩容就是建立一个新的数组newTab,它的长度是oldTab的两倍,然后把oldTab中的元素rehash再放到newTab中。1.7之前要将原来的元素全部rehash,1.8我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。具体可以看Java8之重新认识HashMap
本文参考引用了下列文章
Java8之重新认识HashMap
HashMap底层实现
欢迎关注我的公众号预备码农


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









