




 本文介绍如何在使用Selenium WebDriver进行自动化测试时,通过修改navigator.webdriver属性和使用ChromeDevtools-Protocol来避免被网站识别,实现更隐蔽的爬虫操作。
本文介绍如何在使用Selenium WebDriver进行自动化测试时,通过修改navigator.webdriver属性和使用ChromeDevtools-Protocol来避免被网站识别,实现更隐蔽的爬虫操作。
文章目录
一行js代码识别Selenium+Webdriver
有不少朋友在开发爬虫的过程中喜欢使用Selenium + Chromedriver,以为这样就能做到不被网站的反爬虫机制发现。
先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行Javascript代码,就能轻轻松松识别你是否使用了Selenium + Chromedriver模拟浏览器。
我们来看一个例子,使用下面这一段代码启动Chrome窗口:
from selenium.webdriver import Chrome
driver = Chrome()
现在,在这个窗口中打开开发者工具,并定位到Console选项卡,如下图所示。
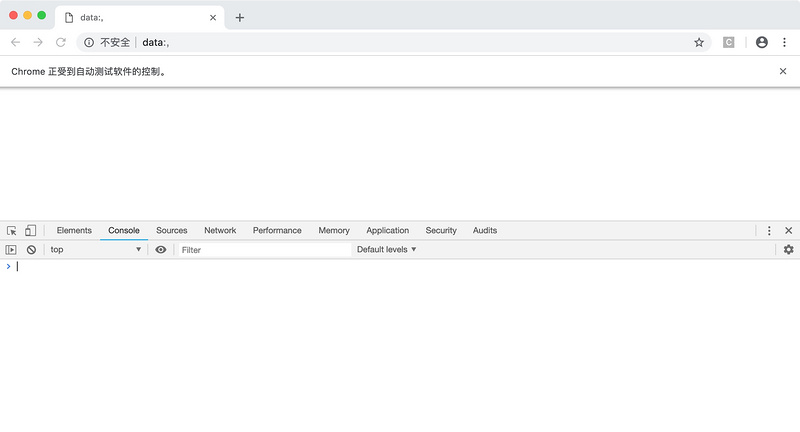
现在,在这个窗口输入如下的js代码并按下回车键:
window.navigator.webdriver
可以看到,开发者工具返回了true。如下图所示。
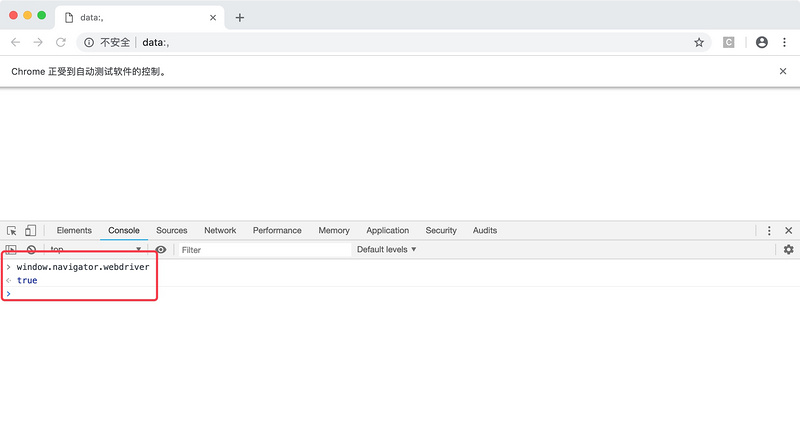
但是,如果你打开一个普通的Chrome窗口,执行相同的命令,可以发现这行代码的返回值为undefined,如下图所示。
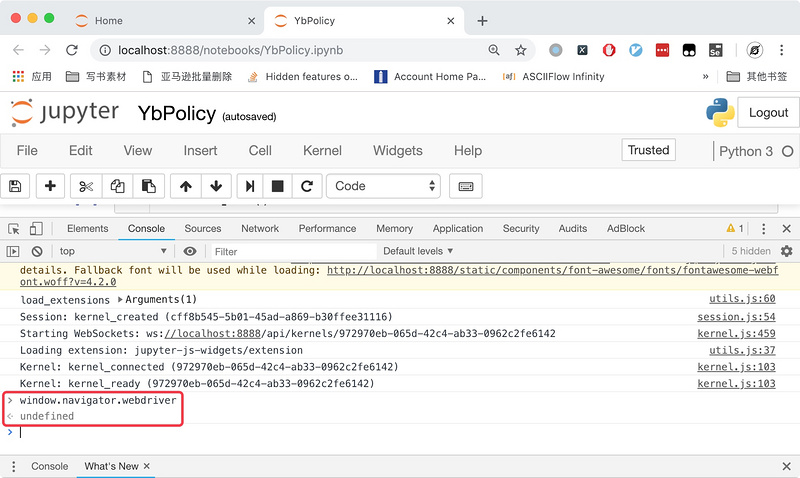
所以,如果网站通过js代码获取这个参数,返回值为undefined说明是正常的浏览器,返回true说明用的是Selenium模拟浏览器。一抓一个准。这里给出一个检测Selenium的js代码例子:
webdriver = window.navigator.webdriver;
if(webdriver){
console.log('你这个傻逼你以为使用Selenium模拟浏览器就可以了?')
} else {
console.log('正常浏览器')
}
网站只要在页面加载的时候运行这个js代码,就可以识别访问者是不是用的Selenium模拟浏览器。如果是,就禁止访问或者触发其他反爬虫的机制。
那么对于这种情况,在爬虫开发的过程中如何防止这个参数告诉网站你在模拟浏览器呢?
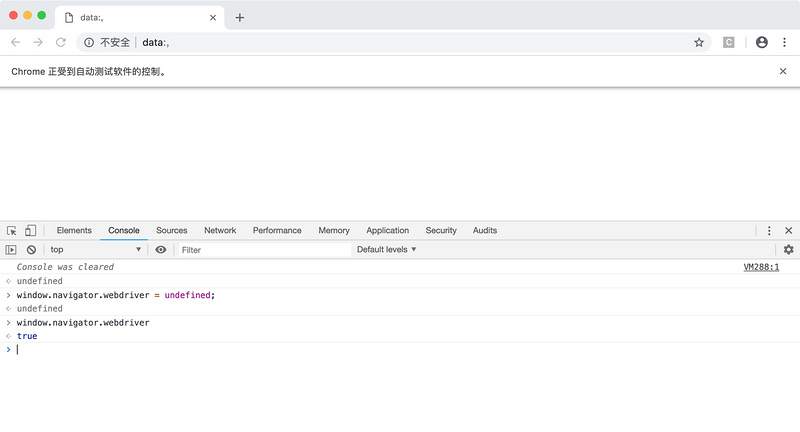
可能有一些会js的朋友觉得可以通过覆盖这个参数从而隐藏自己,但实际上这个值是不能被覆盖的:
对js更精通的朋友,可能会使用下面这一段代码来实现:
Object.defineProperties(navigator, {webdriver:{get:()=>undefined}});
js = r"Object.defineProperty(navigator, 'webdriver', {get: () => undefined,});"
self.driver.execute_script(js)
运行效果如下图所示:
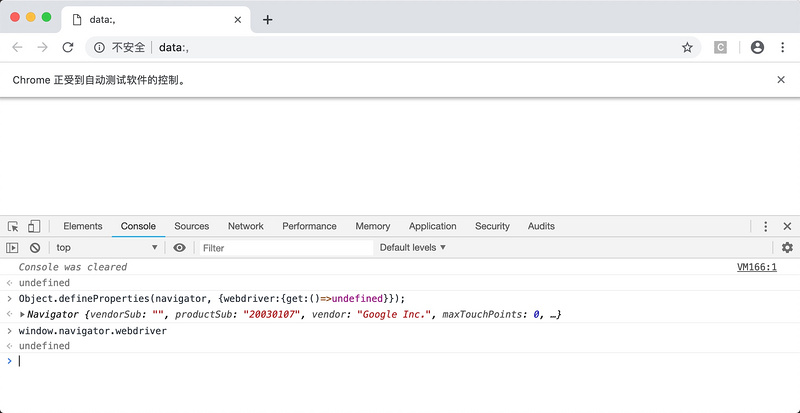
确实修改成功了。这种写法就万无一失了吗?并不是这样的,如果此时你在模拟浏览器中通过点击链接、输入网址进入另一个页面,或者开启新的窗口,你会发现,window.navigator.webdriver又变成了true。如下图所示。
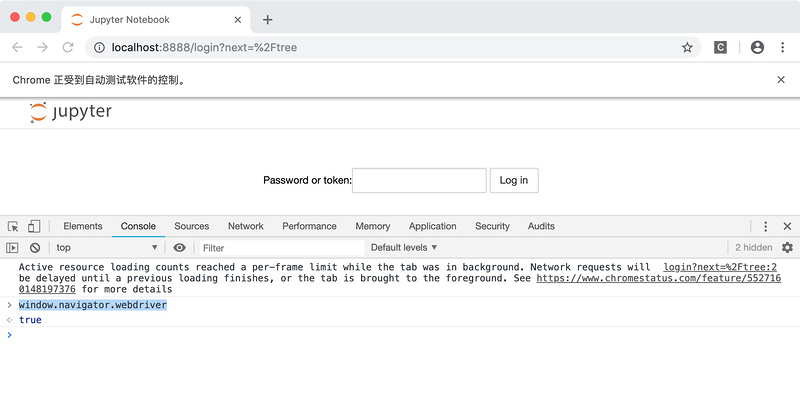
那么是不是可以在每一个页面都打开以后,再次通过webdriver执行上面的js代码,从而实现在每个页面都把window.navigator.webdriver设置为undefined呢?也不行。
因为当你执行:driver.get(网址)的时候,浏览器会打开网站,加载页面并运行网站自带的js代码。所以在你重设window.navigator.webdriver之前,实际上网站早就已经知道你是模拟浏览器了。
接下来,又有朋友提出,可以通过编写Chrome插件来解决这个问题,让插件里面的js代码在网站自带的所有js代码之前执行。
这样做当然可以,不过有更简单的办法,只需要设置Chromedriver的启动参数即可解决问题。
在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为['enable-automation'],完整代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
#开发者模式
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
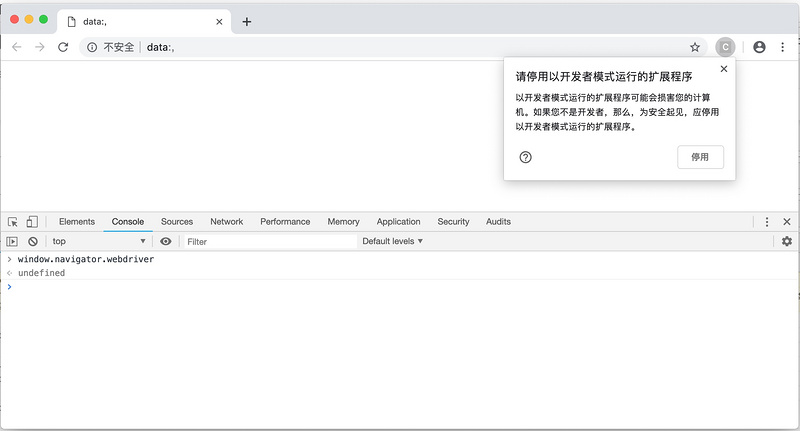
此时启动的Chrome窗口,在右上角会弹出一个提示,不用管它,不要点击停用按钮。
再次在开发者工具的Console选项卡中查询window.navigator.webdriver,可以发现这个值已经自动变成undefined了。并且无论你打开新的网页,开启新的窗口还是点击链接进入其他页面,都不会让它变成true。运行效果如下图所示。
截至2019年02月12日20:46分,本文所讲的方法可以用来登录知乎。如果使用 Selenium 直接登录知乎,会弹出验证码;先使用本文的方法再登录知乎,能够成功伪装成真实的浏览器,不会弹出验证码。
实际上,Selenium + Webdriver能被识别的特征不止这一个。
然而时过境迁,随着 Chrome 版本升级,这一方法也宣告失效。
如何正确移除Selenium中的 window.navigator.webdriver(最新版)
我们今天的方法非常简单。就是使用 Google 的Chrome Devtools-Protocol(Chrome 开发工具协议)简称CDP。
我们打开 CPD 的官方文档[1],可以看到如下的命令:

在每个Frame 刚刚打开,还没有运行 Frame 的脚本前,运行给定的脚本。
通过这个命令,我们可以给定一段 JavaScript 代码,让 Chrome 刚刚打开每一个页面,还没有运行网站自带的 JavaScript 代码时,就先执行我们给定的这段代码。
那么如何在 Selenium 中调用 CDP 的命令呢?实际上非常简单,我们使用driver.execute_cdp_cmd。根据 Selenium 的官方文档[2],传入需要调用的 CDP 命令和参数即可:

于是我们可以写出如下代码:
from selenium.webdriver import Chrome
driver = Chrome('./chromedriver')
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get('http://exercise.kingname.info')
运行效果如下图所示:
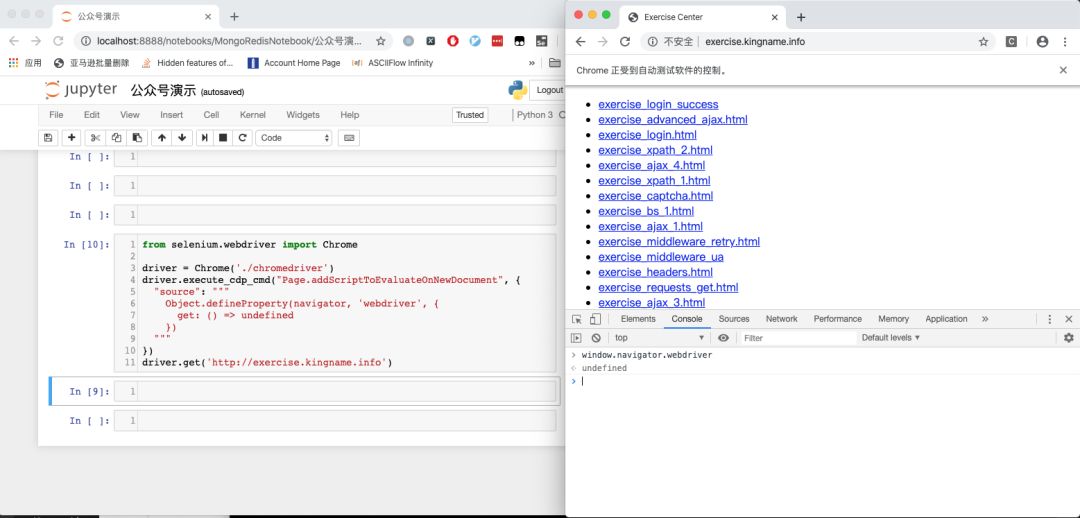
完美隐藏window.navigator.webdriver。并且,关键语句:
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
只需要执行一次,之后只要你不关闭这个driver开启的窗口,无论你打开多少个网址,他都会自动提前在网站自带的所有 js 之前执行这个语句,隐藏window.navigator.webdriver。
如果有人运行上面的代码,出现如下报错:

那么请升级你的 ChromeDriver。老版本的 Chrome + ChromeDriver 只能用以前的方法,不能用今天的方法。新版本的 Chrome + ChromeDriver 可以使用今天的方法,但不能用老方法。正应了那句话:
上帝给你关上一扇门的时候,悄悄为你开了一扇窗。
虽然使用以上代码就可以达到目的了,不过为了实现更好的隐藏效果,大家也可以继续加入两个实验选项:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options, executable_path='./chromedriver')
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get('http://exercise.kingname.info')
附一些网站检测selenium的示例
runBotDetection = function () {
var documentDetectionKeys = [
"__webdriver_evaluate",
"__selenium_evaluate",
"__webdriver_script_function",
"__webdriver_script_func",
"__webdriver_script_fn",
"__fxdriver_evaluate",
"__driver_unwrapped",
"__webdriver_unwrapped",
"__driver_evaluate",
"__selenium_unwrapped",
"__fxdriver_unwrapped",
];
var windowDetectionKeys = [
"_phantom",
"__nightmare",
"_selenium",
"callPhantom",
"callSelenium",
"_Selenium_IDE_Recorder",
];
for (const windowDetectionKey in windowDetectionKeys) {
const windowDetectionKeyValue = windowDetectionKeys[windowDetectionKey];
if (window[windowDetectionKeyValue]) {
return true;
}
};
for (const documentDetectionKey in documentDetectionKeys) {
const documentDetectionKeyValue = documentDetectionKeys[documentDetectionKey];
if (window['document'][documentDetectionKeyValue]) {
return true;
}
};
for (const documentKey in window['document']) {
if (documentKey.match(/\$[a-z]dc_/) && window['document'][documentKey]['cache_']) {
return true;
}
}
if (window['external'] && window['external'].toString() && (window['external'].toString()['indexOf']('Sequentum') != -1)) return true;
if (window['document']['documentElement']['getAttribute']('selenium')) return true;
if (window['document']['documentElement']['getAttribute']('webdriver')) return true;
if (window['document']['documentElement']['getAttribute']('driver')) return true;
return false;
};
try {
if (window.document.documentElement.getAttribute("webdriver")) return !+[]
} catch (IDLMrxxel) {}
try {
if ("_Selenium_IDE_Recorder" in window) return !+""
} catch (KknKsUayS) {}
try {
if ("__webdriver_script_fn" in document) return !+""
改写特征参数的js
// 改写 `languages`
Object.defineProperty(navigator, "languages", {
get: function() {
return ["en", "es"];
}
});
//改写 `plugins`
Object.defineProperty(navigator, "plugins", {
get: () => new Array(Math.floor(Math.random() * 6) + 1),
});
// 改写`webdriver`
Object.defineProperty(navigator, "webdriver", {
get: () => false,
});
driver.execute_script
- 执行单行javascript代码。例:已知‘id’,向表格里注入用户名
driver.execute_script("document.getElementById('id').value='用户名';"
- 执行多行javascript代码。例:用javascript注入js文件
javacriptCode = '''
var scriptElt = document.createElement('script');
scriptElt.type = 'text/javascript';
scriptElt.src = jsFile;
document.getElementsByTagName('head')[0].appendChild(scriptElt);
'''
try
driver.execute_script(javacriptCode)
except:
pass
为什么使用Try / Except 语句?
执行javascript代码时很多情况python会报错,但往往代码却可以被正确的执行。加上Try / Except来保护程序的执行。
- 根据坐标,命令selenium点击特定位置。有的时候很难定位一个位置,我们可以用坐标这样的绝对位置来定位
#例如点击屏幕上 (271,100)这个位置
driver.execute_script("document.elementFromPoint(271, 100).click();")
参考资料
[1]CPD 的官方文档: https://chromedevtools.github.io/devtools-protocol/tot/Page#method-addScriptToEvaluateOnNewDocument
[2]官方文档: https://www.selenium.dev/selenium/docs/api/py/webdriver_chrome/selenium.webdriver.chrome.webdriver.html#selenium.webdriver.chrome.webdriver.WebDriver.execute_cdp_cmd
参考:https://blog.youkuaiyun.com/weixin_33816821/article/details/88590077
https://blog.youkuaiyun.com/jiduochou963/article/details/88200217
https://blog.youkuaiyun.com/sinat_38682860/article/details/86221844
https://mp.weixin.qq.com/s/U2aAC6K6RuQDRqfb8m35_w


















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











