



 本文档介绍了在redhat6.5环境下,如何配置Hadoop-2.7.3集群,包括主节点和子节点的设置。内容涵盖集群部署、文件同步、节点的在线添加和删除。通过操作,成功实现了数据在不同节点间的同步,并展示了节点添加和删除后的状态变化。
本文档介绍了在redhat6.5环境下,如何配置Hadoop-2.7.3集群,包括主节点和子节点的设置。内容涵盖集群部署、文件同步、节点的在线添加和删除。通过操作,成功实现了数据在不同节点间的同步,并展示了节点添加和删除后的状态变化。
环境配置:
操作系统:redhat6.5 iptables selinux off
Server1为主节点
Server2和server3为子节点
hadoop-2.7.3版本
hadoop的安装和单节点配置参照hadoop的安装及单节点配置
Hadoop集群:
[root@server1 ~]# rpm -qa nfs-utils
nfs-utils-1.2.3-39.el6.x86_64
###查看是否安装此包,如果没有直接yum安装
[root@server1 ~]# rpm -qa rpcbind
rpcbind-0.2.0-11.el6.x86_64
[root@server1 ~]#/etc/init.d/rpcbind start
###一定要保证rpcbind开启写远程同步文件
[root@server1 ~]# vim /etc/exports
文件内容如下,做远程同步
[root@server1 ~]# /etc/init.d/nfs start
[root@server1 ~]# showmount -e ##发现同步设置
Export list for server1:
/home/hadoop *建立hadoop用户,登入
[root@server1 ~]#useradd -u 800 hadoop ##建立hadoop用户
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ cd hadoop
###就是之前解压hadoop包后的目录,为了方便做了个软连接
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ cd etc/
[hadoop@server1 etc]$ ls
hadoop
[hadoop@server1 etc]$ cd hadoop/[hadoop@server1 hadoop]$ vim hdfs-site.xml内容如下:

做解析
[hadoop@server1 hadoop]$ vim slaves
[hadoop@server1 hadoop]$ cd /tmp/
[hadoop@server1 tmp]$ ls ##最好删除里面的文件
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
###格式化
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
###利用脚本启动hadoop进程
[hadoop@server1 hadoop]$ jps ###查看java进程
测试:
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user
##建立目录
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -put /user/hadoop
###上传
^C[hadoop@server1 hadoop]$ bin/hdfs dfs -put input/
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output
###调用jar包,实现文件计数功能
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls output/ ##查看输出
另一种查看方式:

在server2中:
[root@server2 ~]# yum install -y nfs-utils
###安装nfs
[root@server2 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server2 ~]# /etc/init.d/rpcbind status
rpcbind (pid 1699) is running...
###启动服务
[root@server2 ~]# useradd -u 800 hadoop ##建立用户
[root@server2 ~]# id hadoop
uid=800(hadoop) gid=800(hadoop) groups=800(hadoop)
[root@server2 ~]# mount 172.25.3.1:/home/hadoop/ /home/hadoop/
###挂载目录,进行同步
[root@server2 ~]# ll -d /home/hadoop/
drwx------ 6 hadoop hadoop 4096 Aug 26 15:41 /home/hadoop/
登入hadoop用户,发现server1的数据已同步过来

查看java进程,发现为数据节点

在server3:
[root@server3 ~]# yum install nfs-utils -y
[root@server3 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server3 ~]# useradd -u 800 hadoop
[root@server3 ~]# id hadoop
uid=800(hadoop) gid=800(hadoop) groups=800(hadoop)
[root@server3 ~]# mount 172.25.3.1:/home/hadoop/ /home/hadoop/登入hadoop用户,发现server1的数据已同步过来

查看java进程,发现为数据节点

集群节点的在线添加和删除:
1.添加:
在server4上:
[root@server4 ~]# yum install -y nfs-utils
[root@server4 ~]# useradd -u 800 hadoop
###建立用户
[root@server4 ~]# mount 172.25.3.1:/home/hadoop/ /home/hadoop/
挂载目录,同步数据
[hadoop@server4 ~]$ cd hadoop
[hadoop@server4 hadoop]$ cd etc/hadoop/
[hadoop@server4 hadoop]$ vim slaves
写入server4主机的解析
[hadoop@server4 hadoop]$ cd ..
[hadoop@server4 etc]$ ls
hadoop
[hadoop@server4 etc]$ cd ..
[hadoop@server4 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server4 hadoop]$ sbin/hadoop-daemon.sh start datanode
###启动数据节点
starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server4.out
在浏览器查看,数据节点添加成功

2.删除
在server1中:
hadoop@server1 hadoop]$ dd if=/dev/zero of=bigfile bs=1M count=300
###截取一个300M的文件
300+0 records in
300+0 records out
314572800 bytes (315 MB) copied, 2.24179 s, 140 MB/s
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
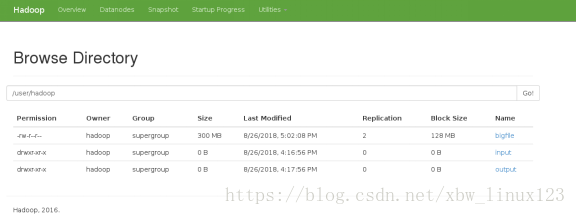
[hadoop@server1 hadoop]$ bin/hdfs dfs -put bigfile
###将文件上传在浏览器查看,bigfile已添加
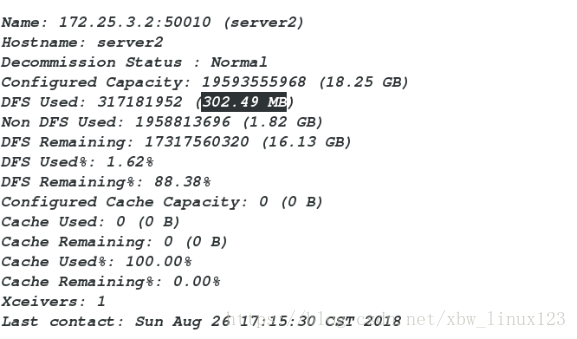
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report
###查看各个节点信息,内存使用基本分配均匀
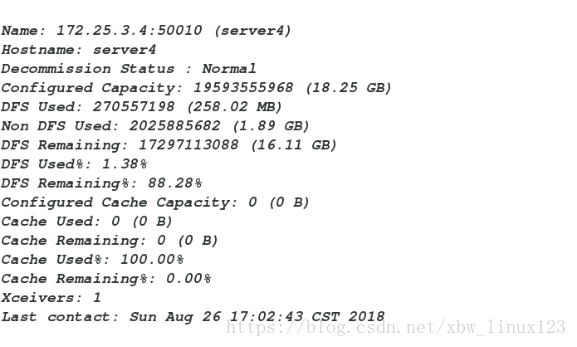
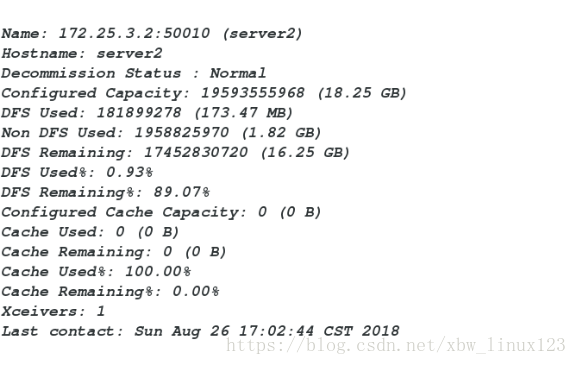
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim slaves
###将server3的ip去除
[hadoop@server1 hadoop]$ vim hosts-exclude
###将server3的ip写入
[hadoop@server1 hadoop]$ cat hosts-exclude
172.25.3.3[hadoop@server1 hadoop]$ vim hdfs-site.xm
###修改此文件,内容如下
[hadoop@server1 hadoop]$ cd ..
[hadoop@server1 etc]$ cd ..
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -refreshNodes 刷新一下
Refresh nodes successful
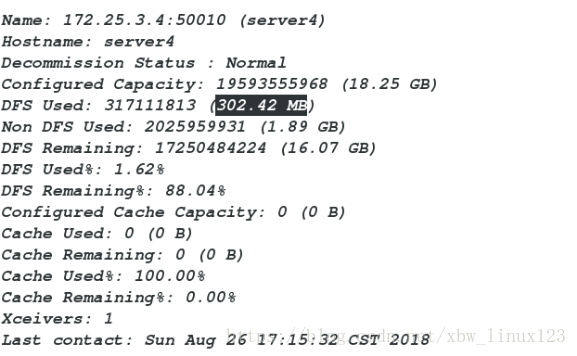
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report
##移除server3后在查看
###会发现之前截取的300M,在server2和4上平均分配server3回到了之前的内存使用量
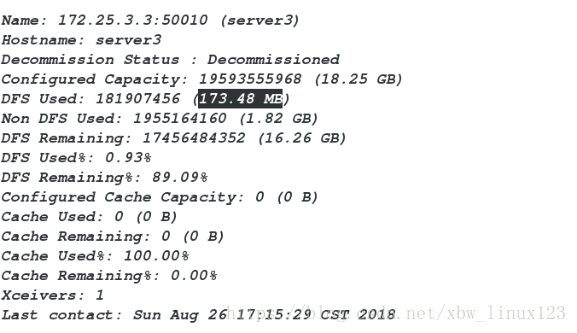
server2和server4两个平均分摊之前截取的300M

















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









