




2025年国庆首日上午9点,某国民级短视频平台同时在线用户突破12亿,每秒新上传视频18万条——如果只靠一台服务器处理这些数据,它会像被塞进100个汉堡的胃袋,当场“罢工”。但现实是,你刷视频时几乎感受不到卡顿。这背后,藏着一个让程序员又爱又恨的技术:分布式系统(Distributed Systems)。
从“魔法盒子”到“组队搬砖”:我们为什么需要分布式系统?
其实,人类骨子里讨厌复杂。如果有钱有技术,谁不想造个“魔法盒子”?——一台算力无限、永不死机的超级电脑,所有数据和计算都往里扔,简单直接。但现实是,“魔法盒子”只存在于科幻片里:
- 钱不够:顶级服务器单价动辄千万,性能提升10倍可能要多花100倍的钱(经济学上的“边际成本递增”);
- 物理极限:单个CPU的运算速度受限于光速和量子隧穿效应,内存再大也装不下全球用户的聊天记录。
于是,工程师们想出了“组队搬砖”的笨办法:让多台普通电脑(专业术语叫“节点”)联手干活,这就是分布式系统。就像盖大楼不会只请一个超级工人,而是一群普通工人分工协作——Barroso等学者在《The Datacenter as a Computer》中证明:当节点数超过100时,一堆中端服务器( commodity hardware)的性价比能反超顶级服务器,因为“沟通成本”比“单机性能”更重要。
但“组队”不简单。100台电脑协作,比100个人搬砖复杂100倍:数据要复制到不同节点,任务要分配给谁,某个节点“摸鱼”了怎么办?这就是分布式系统的核心挑战——用不完美的零件,拼出可靠的系统。
可扩展性(Scalability):从“小作坊”到“跨国公司”的进化
“系统撑不住了!”——这是程序员最怕听到的话。而分布式系统的终极目标,就是解决“长大”的烦恼:可扩展性,即系统“长大后,日子不会越来越差”的能力。
想象一家包子铺的扩张:
- 小作坊阶段(单机):1个师傅、1口锅,每天做100个包子,轻松愉快;
- 连锁店阶段(分布式):10家分店、100个师傅,每天做1万个包子,还得保证每家店的包子味道一样(数据一致性),某个店停电了其他店能顶上(可用性)。
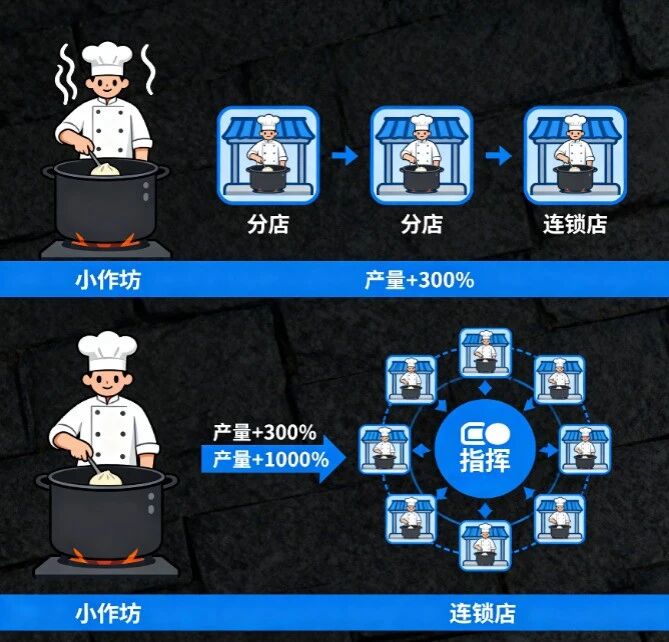
可扩展性具体看三个维度:
规模可扩展性:加人就该加效率
理想状态是“加1台服务器,性能提升1倍”(线性扩展)。就像外卖平台多1个配送站,理论上能多接1倍订单。但现实中,10个配送站的效率永远达不到1个站的10倍——因为站长要协调路线(节点通信),订单可能重复分配(数据冲突),这些“内耗”就是分布式系统的“扩展 overhead”。
地理可扩展性:让北京用户别等广州的服务器
如果你在哈尔滨刷朋友圈,数据却存在三亚的服务器,光信号传输就要0.03秒(光速约30万公里/秒),加上处理时间,延迟能让你以为手机卡了。分布式系统通过“多数据中心”解决这个问题:把数据存在离用户最近的节点,就像连锁餐厅在每个城市设仓库,不用从总部调货。
管理可扩展性:别让1个管理员管1000台服务器
小公司1个IT管理员管10台电脑很轻松,管1000台就会崩溃。好的分布式系统能“自治”:自动检测故障、分配资源,就像智能家居系统,不用你手动开关每盏灯。
性能与延迟:为什么刷短视频总在“转圈圈”?
“性能”是用户对系统的第一感受,而延迟(Latency) 是最磨人的那个指标。
latency的拉丁词源是“latens”(隐藏),指“事情发生到产生影响的隐藏时间”。就像你感染了“外卖病毒”,下单到收到餐的时间就是延迟——对分布式系统来说,就是“数据写入后,多久能被所有人看到”。
延迟从哪来?物理定律是最大Boss
- 光速限制:北京到上海的光纤传输至少需要8毫秒(约0.008秒),这是物理定律,花钱也解决不了;
- 硬件瓶颈:硬盘读写需要毫秒级时间,内存快100倍,但再快也快不过电信号在芯片里的奔跑速度。
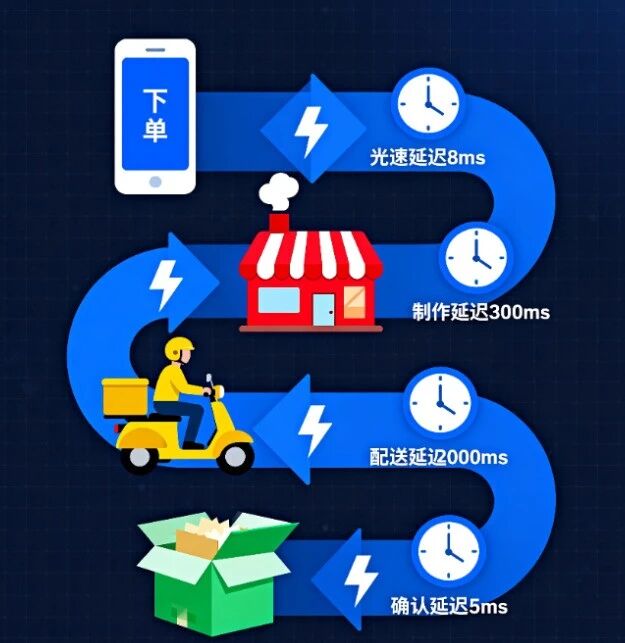
网友吐槽“刷短视频加载转圈圈”,往往就是延迟在作祟:你的手机在等千里之外的服务器把数据传过来。而分布式系统对抗延迟的终极武器,就是把数据“搬到”用户身边——比如你刷到的视频,很可能存在你城市的本地缓存节点。
可用性(Availability):系统“不罢工”的秘密
2024年双11零点,某平台因服务器故障瘫痪10分钟,直接损失超2亿——这就是可用性(系统正常运行的时间占比)的重要性。公式很简单:
可用性 = 正常运行时间 / (正常运行时间 + 故障时间)
但现实很残酷:节点越多,出故障的概率越高(100台服务器同时坏1台的概率,比1台服务器坏的概率高100倍)。怎么办?冗余——给系统“备备胎”。
“几个九”的含金量:从“一个月死机”到“31秒故障”
行业里用“几个九”衡量可用性:
- 90%(一个九):每年允许 downtime 超过1个月(别想在互联网行业混了);
- 99.999%(五个九):每年 downtime 约5分钟,相当于你手机一年死机不到一首歌的时间;
- 99.9999%(六个九):每年 downtime 31秒,这是金融核心系统的标配。
分布式系统的魔法在于:用一堆“不靠谱”的节点,拼出“超级靠谱”的服务。就像飞机有4个引擎,坏1个照样飞;数据存3个节点,坏2个还有备份。
两大法宝:分区(Partitioning)与复制(Replication)
如果把分布式系统比作“数据帝国”,那分区和复制就是治理这个帝国的两大国策。
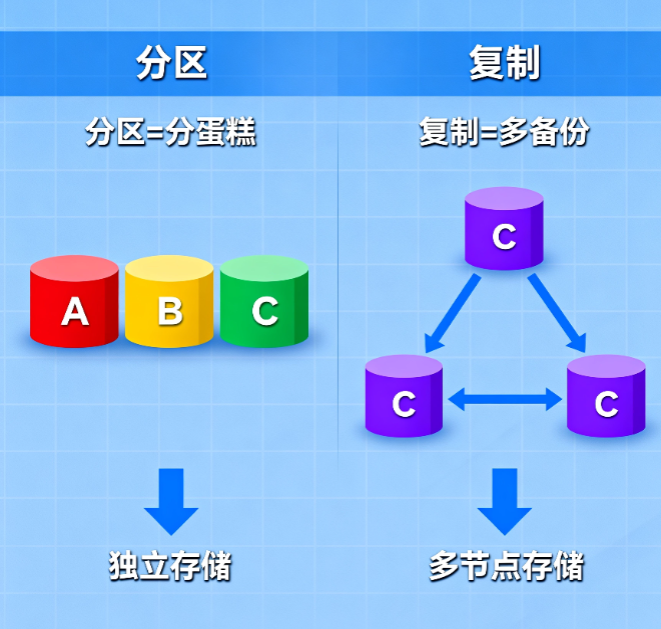
分区:把“大蛋糕”切成小块
数据量太大怎么办?切!分区(Partitioning) 就是把数据集拆成独立小块,每个节点负责一块。就像图书馆按学科分区,你找《分布式系统》不用翻遍整个图书馆。
好处很明显:
- 性能提升:每个节点只处理部分数据,查询速度更快;
- 故障隔离:A分区崩了,B分区照样服务(就像奶茶店某款饮料卖完了,其他款还能点)。
但分区是门手艺活:如果按“用户ID首字母”分区,可能A开头用户特别多,导致某个节点过载(“数据倾斜”),就像食堂某个窗口排队特别长。
复制:给“重要文件”多复印几份
复制(Replication) 就是把同一份数据存到多个节点,堪称分布式系统的“万金油”—— Homer Simpson 曾调侃:“复制是所有问题的根源,也是所有问题的解药。”
为啥需要复制?
- 对抗延迟:北京用户查数据,直接读北京节点的副本,不用等广州节点;
- 提升可用性:3个副本坏2个,还有1个能用(就像重要合同复印3份,丢1份不怕);
- 分担压力:10个节点同时提供读服务,吞吐量提升10倍。
但复制的“坑”也最多:3个副本如何保持一致?(比如你改了微信签名,手机、平板、电脑要同时显示最新的)这就是一致性模型(Consistency Model)要解决的问题——强一致性(所有副本立刻同步)像实时共享文档,延迟高但靠谱;最终一致性(副本慢慢同步)像微信群消息,偶尔不同步但响应快。
结语:分布式系统的“成人世界法则”
从单机到分布式,本质是一场“向现实妥协”的进化:我们放弃了“魔法盒子”的幻想,接受不完美的节点,用复杂的协作换来了“无限扩展”的可能。
就像2025年国庆你轻松刷着阅兵直播、抢购限量商品时,背后是成百上千台服务器在“分工搬砖”:有的存数据,有的算推荐,有的当备胎——它们未必是最强大的个体,却通过精妙的协作,撑起了这个数据爆炸的时代。
分布式系统教会我们:世界上没有完美的解决方案,只有适合当下的权衡。而理解这种权衡,或许就是技术人最核心的能力。
(参考资料:Barroso & Hölzle《The Datacenter as a Computer》、Hodges《Notes on Distributed Systems for Young Bloods》)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









