




查阅了一些优快云上的博客,发现这些程序不太能满足自己的需求,因此记录一下加载CHB-MIT波士顿儿童医院癫痫EEG脑电数据集的过程,也给大家一些参考。
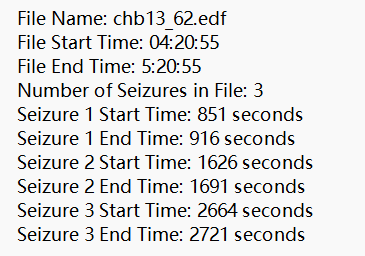
首先讲一下思路:我们需要先加载edf文件,顺便通过一个0.1hz到50hz的滤波,然后从summary.txt文件中的开始和结束时间提取发病期和发病间期,最后将发病期和发病间期分别保存为csv文件。
注意事项:该患者的edf文件和summary.txt文件需要在一个文件夹中。

import mne
import numpy as np
import pandas as pd
import os
import re
def extract_seizure_info(file_path):
"""
从给定的文本文件中提取所有癫痫发作时间不为 0 的文件名和相关时间信息。
:param file_path: 要处理的文本文件路径
:return: 包含文件名、癫痫开始时间和结束时间的字典列表
"""
with open(file_path, 'r') as file:
content = file.read()
# 使用正则表达式提取需要的信息
pattern = r"File Name: (\S+)\s+File Start Time: \S+\s+File End Time: \S+\s+Number of Seizures in File: (\d+)(?:\s+Seizure Start Time: (\d+) seconds\s+Seizure End Time: (\d+) seconds)*"
matches = re.findall(pattern, content)
seizures_info = []
for match in matches:
file_name = match[0]
num_seizures = int(match[1])
if num_seizures > 0:
# 处理多个癫痫发作时间段
for i in range(2, len(match), 2):
if match[i]:
seizure_start_time = int(match[i])
seizure_end_time = int(match[i + 1])
seizures_info.append({
'File Name': file_name,
'Seizure Start Time': seizure_start_time,
'Seizure End Time': seizure_end_time
})
return seizures_info
# 定义数据文件夹路径
data_folder = r"C:\EEG_DATA\chb11"
summary_file_path = os.path.join(data_folder, "chb11-summary.txt")
# 提取癫痫发作信息
seizure_data = extract_seizure_info(summary_file_path)
# 采样率
sampling_rate = 256
# 用于存储癫痫数据和正常数据的列表
seizure_data_list = []
normal_data_list = []
for info in seizure_data:
file_name = info['File Name']
seizure_start_time = info['Seizure Start Time']
seizure_end_time = info['Seizure End Time']
# 加载EDF文件
edf_file_path = os.path.join(data_folder, file_name)
try:
raw = mne.io.read_raw_edf(edf_file_path, preload=True, verbose=False)
except FileNotFoundError:
print(f"Warning: {edf_file_path} not found. Skipping this file.")
continue # 跳过这个文件,继续处理下一个文件
# 检查并处理重复的通道名称
channel_names = raw.ch_names
if len(set(channel_names)) != len(channel_names):
print("发现重复的通道名称,正在处理...")
unique_channel_names = list(set(channel_names))
raw.pick_channels(unique_channel_names)
# 进行滤波操作
raw.filter(0.1, 50., method='iir')
# 获取数据和时间戳
data, times = raw[:, :]
data = data.T * 1000000 # 转换为微伏
# 计算癫痫发作时间段的索引
start_index = int(seizure_start_time * sampling_rate)
end_index = int(seizure_end_time * sampling_rate)
# 提取癫痫发作数据
seizure_data_segment = data[start_index:end_index, :]
seizure_data_list.append(seizure_data_segment)
# 提取正常数据
normal_data_before = data[:start_index, :]
normal_data_after = data[end_index:, :]
if normal_data_before.size > 0:
normal_data_list.append(normal_data_before)
if normal_data_after.size > 0:
normal_data_list.append(normal_data_after)
# 合并癫痫数据和正常数据
Seizure_data = np.vstack(seizure_data_list) if seizure_data_list else np.array([])
normal_data = np.vstack(normal_data_list) if normal_data_list else np.array([])
print(f"Seizure_data shape: {Seizure_data.shape}")
print(f"normal_data shape: {normal_data.shape}")
# 保存 Seizure_data 和 normal_data 为 CSV 文件
# 转换为 DataFrame 后保存为 CSV
seizure_data_df = pd.DataFrame(Seizure_data)
normal_data_df = pd.DataFrame(normal_data)
# 定义文件保存路径
seizure_data_file = os.path.join(data_folder, "Seizure_data.csv")
normal_data_file = os.path.join(data_folder, "normal_data.csv")
# 保存为 CSV
seizure_data_df.to_csv(seizure_data_file, index=False)
normal_data_df.to_csv(normal_data_file, index=False)
print(f"Seizure data saved to: {seizure_data_file}")
print(f"Normal data saved to: {normal_data_file}")
目前存在一个问题,目前识别不了一个文件包含多段发病期的情况。建议删掉其他段落只保留一段。

















 4104
4104




 到【灌水乐园】发言
到【灌水乐园】发言







