



网站扫描工具AWVS下载与安装
通过网盘分享的文件:linux awvs.zip
链接: https://pan.baidu.com/s/1jnpjq0BSUWXmiaSdhKB4Uw?pwd=8888 提取码: 8888
将文件放到Linux目录下,添加对应权限,运行acunetix_trial.sh文件
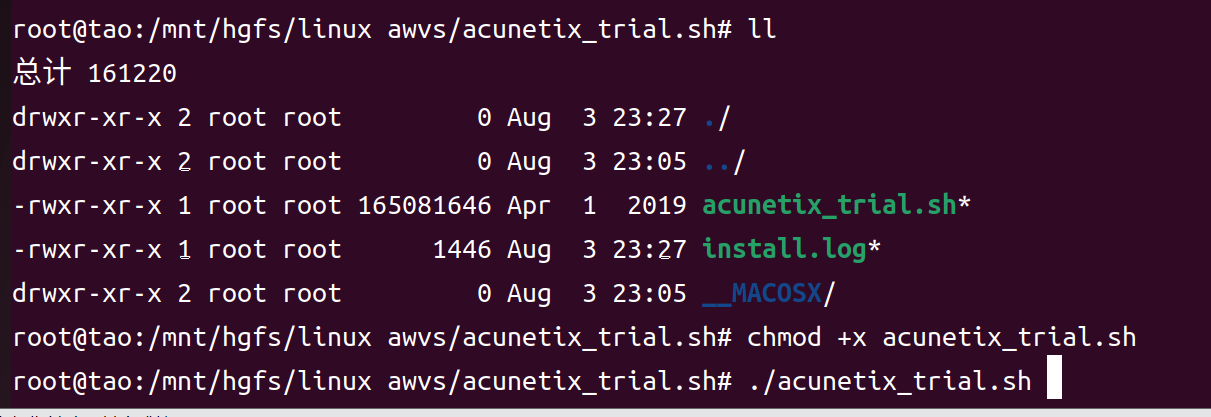
添加用户名:tao,用户邮箱:tao@qq.com,密码:14398@qtrA
开启服务:service acunetix_trial start
查看服务状态:service acunetix_trial status
状态为active表示开启
进行破解,把文件patch_awvs复制到/home/acunetix/.acunetix_trial/v_190325161/scanner/下
命令:mv patch_awvs /home/acunetix/.acunetix_trial/v_190325161/scanner/
在复制后的路径下执行该文件

在Windows的浏览器里输入https://Linux的IP地址:13443/进行访问
脚本源码
#!/bin/bash
# 日志文件路径
logfile=/var/log/nginx
last_minutes=5
# 定义request文件路径
request_file="$logfile/request"
# 开始时间(5分钟前)
start_time=$(date -d"$last_minutes minutes ago" +"%d/%m/%Y:%H:%M:%S")
echo "============================================="
echo "脚本开始执行..."
echo "监控时间范围:$start_time 至 当前时间"
echo "============================================="
# 结束时间(现在)
stop_time=$(date +"%d/%m/%Y:%H:%M:%S")
echo "当前时间:$stop_time"
echo "日志文件路径:$logfile/access.log"
echo "访问记录文件:$request_file"
echo "---------------------------------------------"
# 1. 提取所有访问过的IP(含重复)并生成request文件
echo "正在记录所有访问过的IP(含重复访问)..."
# 筛选时间范围内的IP,不去重,按日志顺序记录
tac $logfile/access.log | awk -v st="$start_time" -v et="$stop_time" '{
t=substr($4,2);
if(t>=st && t<=et){print $1}
}' > $request_file
# 检查是否有IP访问
ip_count=$(wc -l < $request_file)
if [ $ip_count -eq 0 ]; then
echo "无IP访问" > $request_file # 无访问时写入提示
echo "❌ 未发现任何IP访问记录"
else
echo "✅ 成功记录访问IP,共 $ip_count 条记录(含重复)"
fi
echo "---------------------------------------------"
# 2. 筛选指定时间范围内的访问记录并统计IP(去重计数)
echo "正在统计各IP的访问次数..."
tac $logfile/access.log | awk -v st="$start_time" -v et="$stop_time" '{
t=substr($4,2);
if(t>=st && t<=et){print $1}
}' | sort | uniq -c | sort -nr > $logfile/log_ip_top10
# 检查统计结果文件是否生成
if [ -f "$logfile/log_ip_top10" ]; then
echo "访问次数统计完成,生成文件:$logfile/log_ip_top10"
echo "---------------------------------------------"
echo "统计结果(IP访问次数从高到低):"
cat $logfile/log_ip_top10 # 显示统计结果
echo "---------------------------------------------"
else
echo "错误:未生成统计文件,请检查日志路径是否正确!"
exit 1
fi
# 3. 筛选超过阈值的IP(超过100次)
threshold=100
echo "正在筛选访问次数超过 $threshold 次的IP..."
ip_list=$(cat $logfile/log_ip_top10 | awk -v th="$threshold" '{if($1 > th)print "IP:" $2 ", 访问次数:" $1}')
ip_count=$(echo "$ip_list" | wc -l)
if [ $ip_count -gt 0 ]; then
echo "发现 $ip_count 个异常IP:"
echo "$ip_list"
echo "---------------------------------------------"
echo "开始封禁这些IP..."
# 执行封禁并记录
while read -r line; do
count=$(echo $line | awk '{print $1}')
ip=$(echo $line | awk '{print $2}')
echo "封禁 IP: $ip(访问次数:$count)"
echo $ip >> $logfile/getip.txt
iptables -I INPUT -p tcp -m multiport --dport 80,443 -s $ip -j DROP
if [ $? -eq 0 ]; then
echo "✅ 封禁成功"
else
echo "❌ 封禁失败"
fi
done < <(cat $logfile/log_ip_top10 | awk -v th="$threshold" '{if($1 > th)print $0}')
else
echo "未发现超过 $threshold 次访问的IP,无需封禁"
fi
echo "============================================="
echo "脚本执行完毕!"
echo "访问记录文件(含重复IP):$request_file"
echo "统计文件:$logfile/log_ip_top10"
echo "封禁记录:$logfile/getip.txt(若有封禁)"
echo "============================================="
查看nginx日志目录
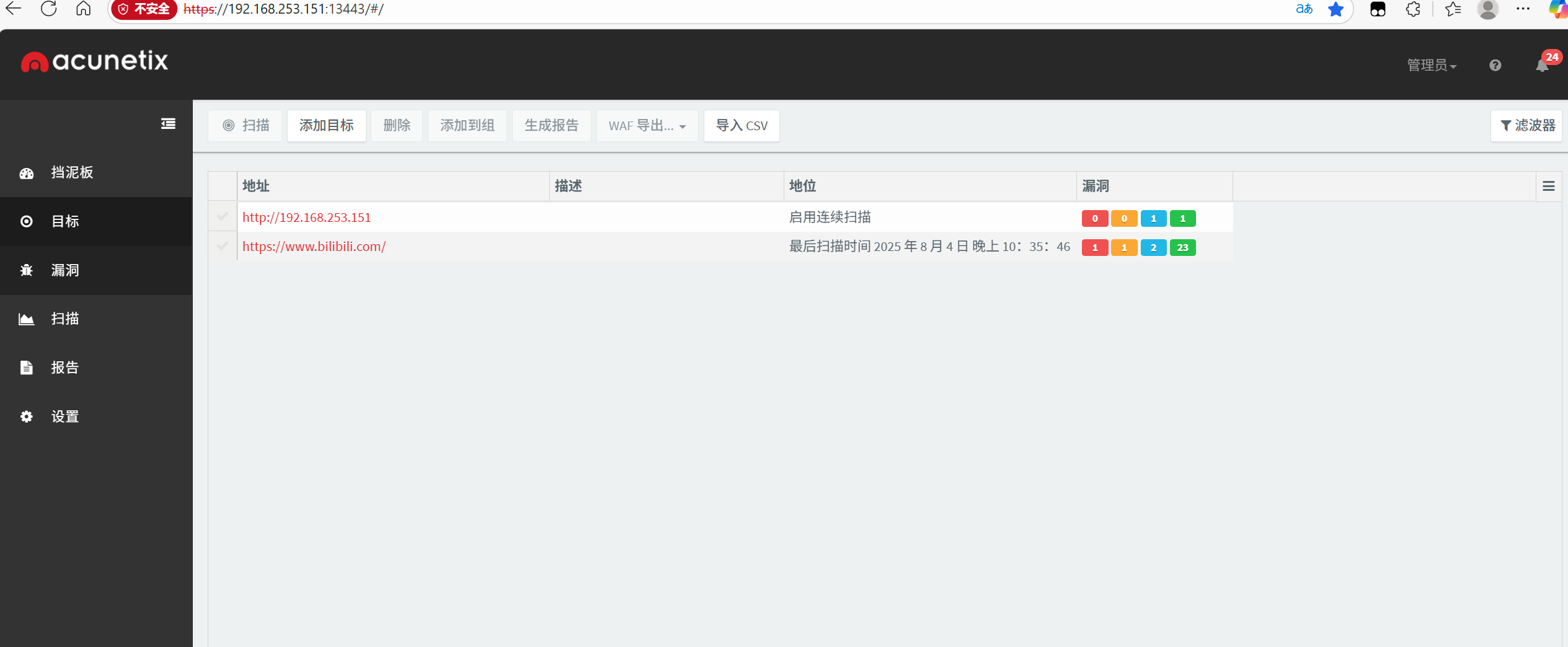
使用AWVS进行扫描
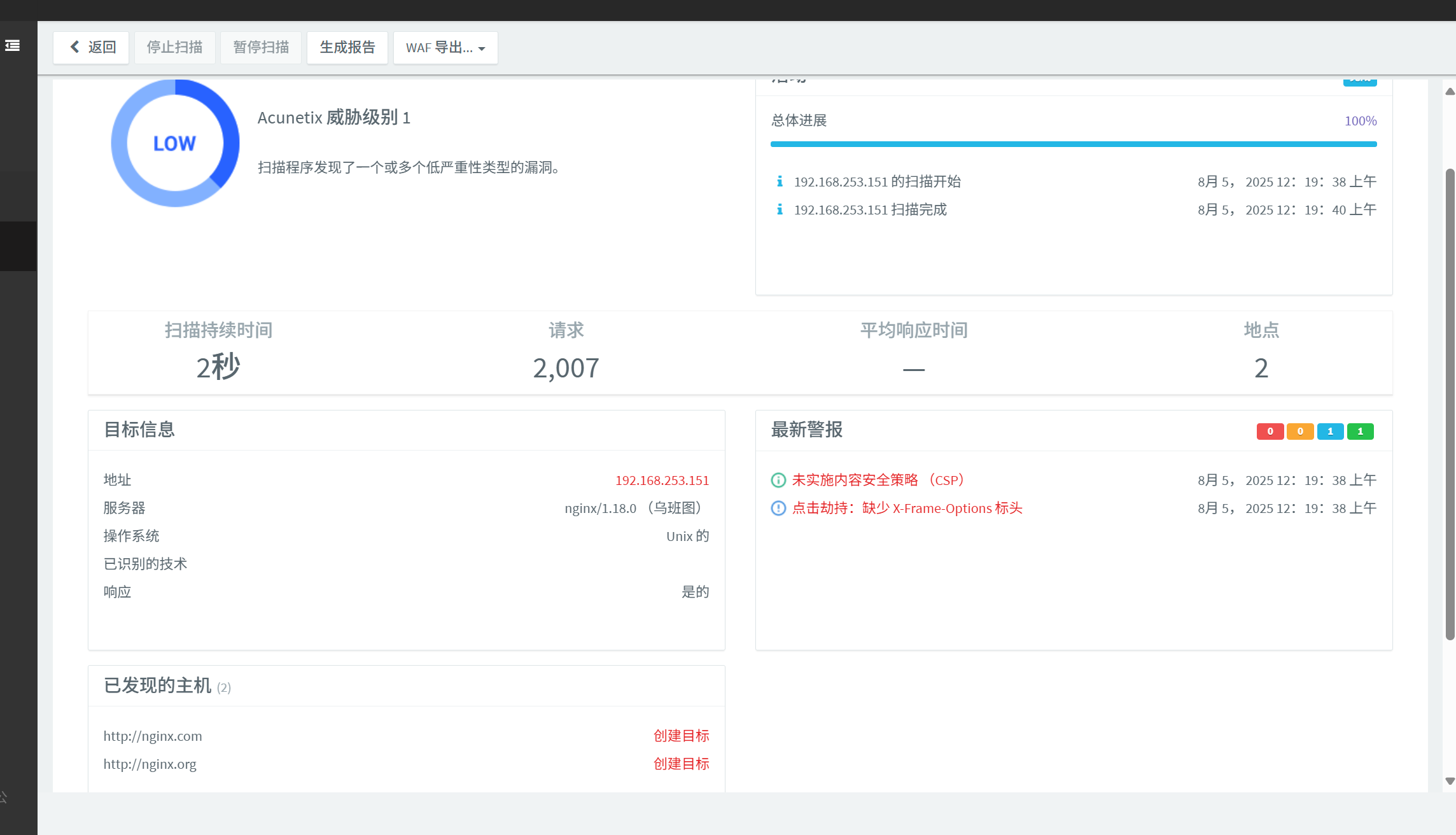
运行脚本,生成访问IP文件request,访问次数超100次名单log_ip_10,黑名单getip.txt
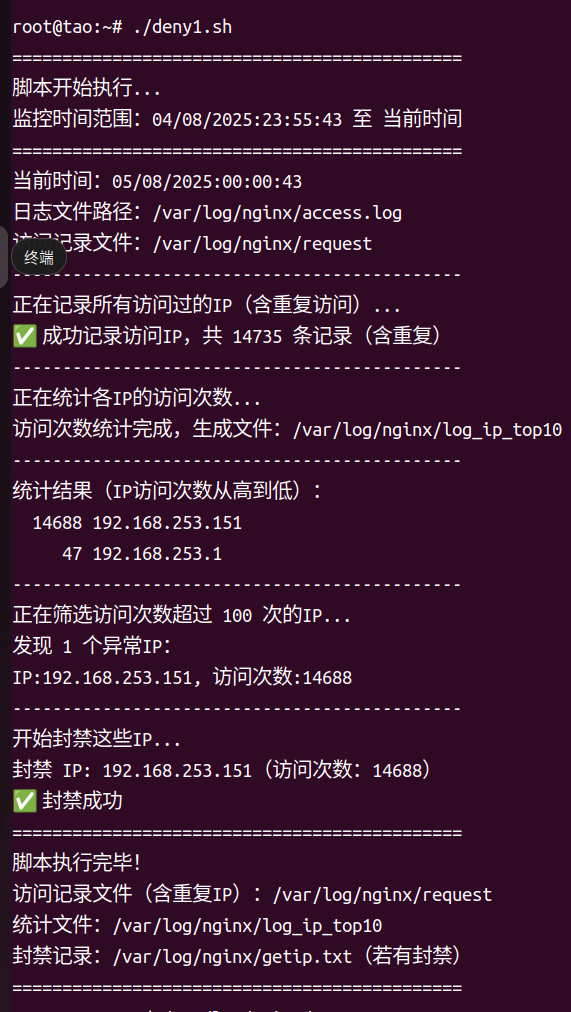
脚本运行成功
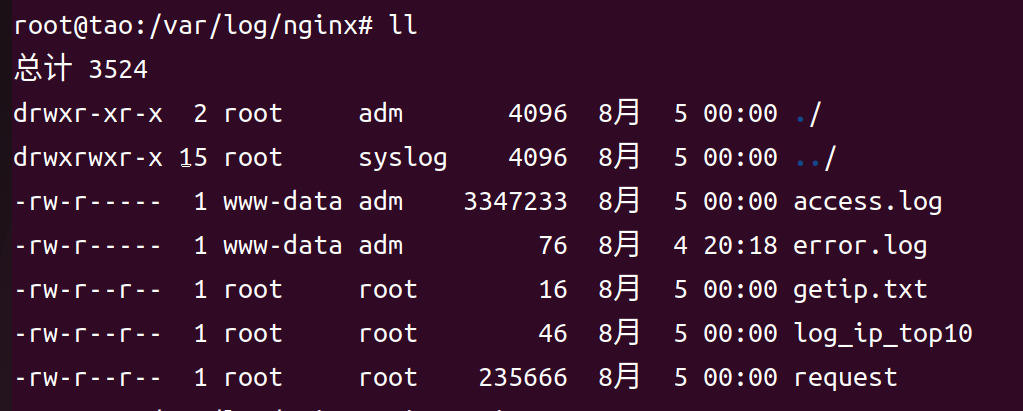
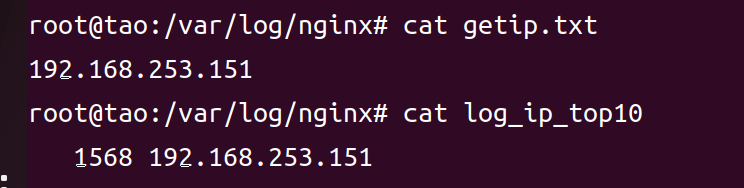
IP被成功封禁,无法扫描
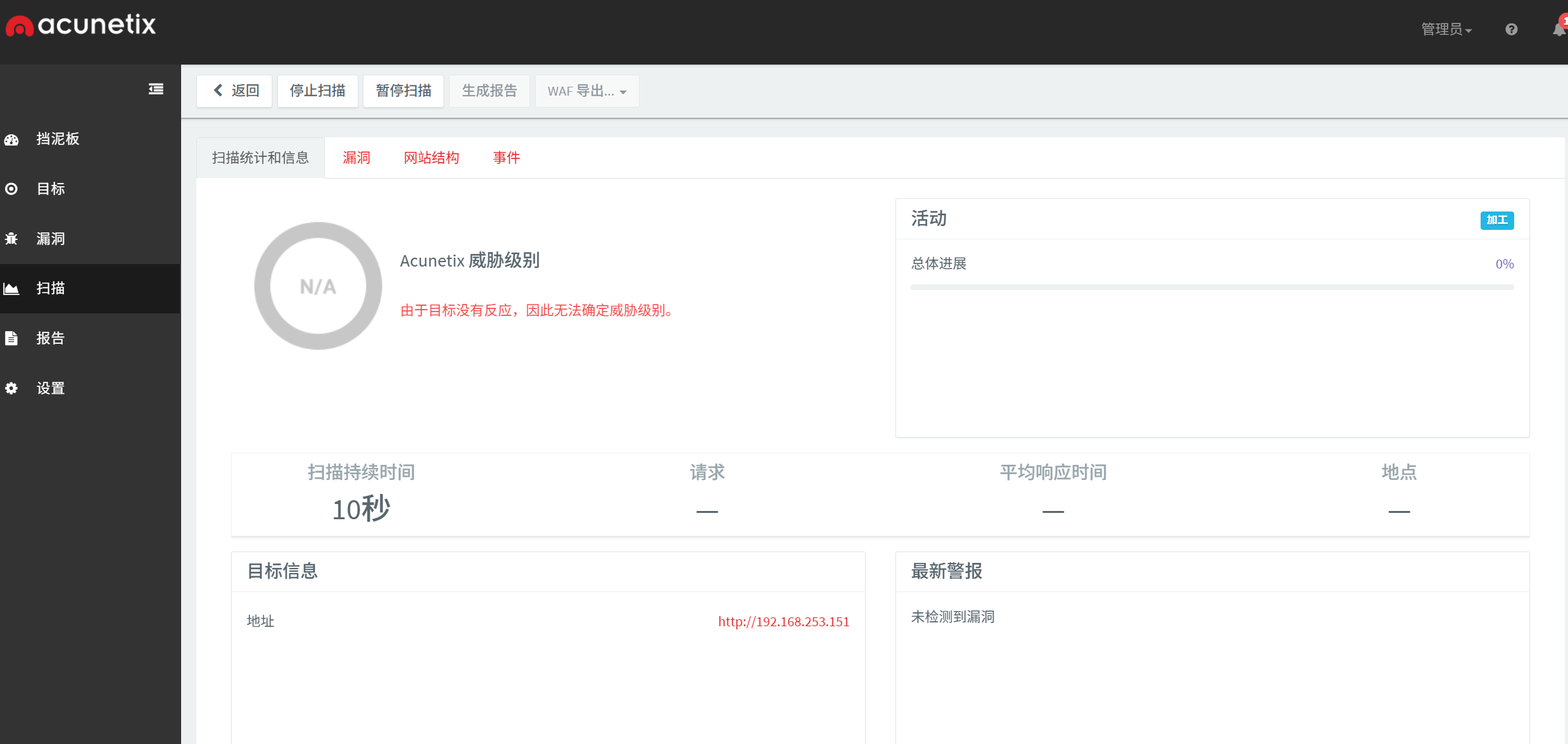
解除封禁的IP



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









