题目一要求:创建一张名为Worker的数据表,表中字段为部门号 工资 职工号 工作时间 出生日期 政治面貌 姓名(均为中文),对此表完成对应操作
创建数据表
CREATE TABLE `worker` (
`部门号` int(11) NOT NULL,
`职工号` int(11) NOT NULL,
`工作时间` date NOT NULL,
`工资` float(8,2) NOT NULL,
`政治面貌` varchar(10) NOT NULL DEFAULT '群众',
`姓名` varchar(20) NOT NULL,
`出生日期` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
插入数据
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-7-1');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-2-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-6-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2');
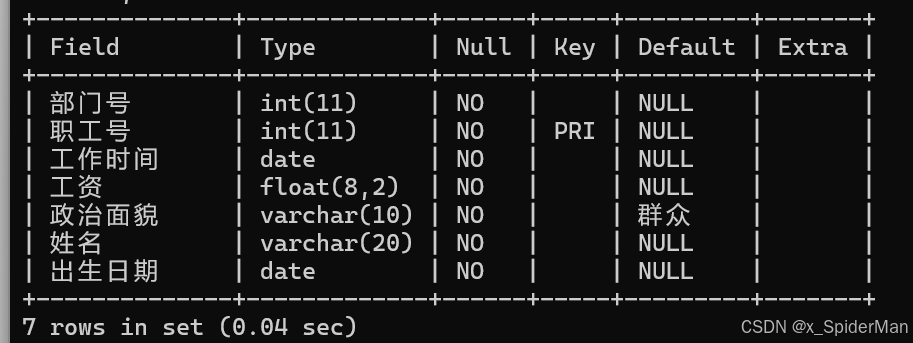
1、显示所有职工的基本信息
select * from worker;
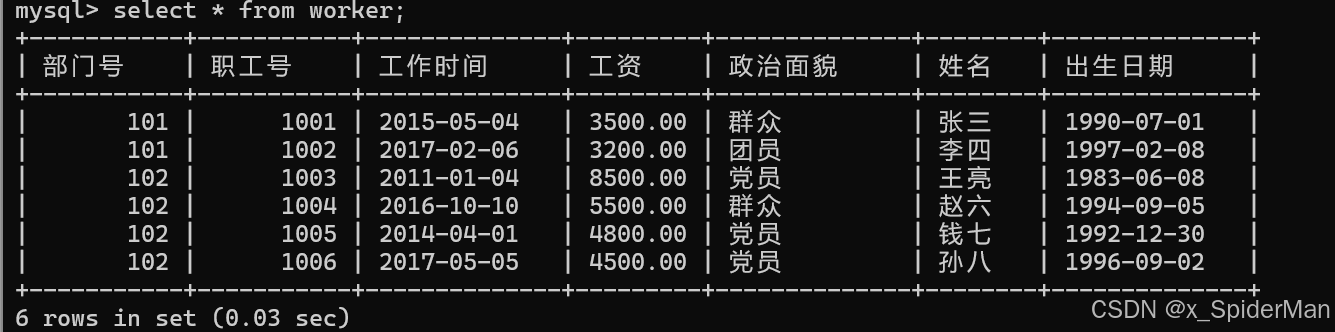
2、查询所有职工所属部门的部门号,不显示重复的部门号(distinct避免重复值)
select distinct 部门号 from worker;
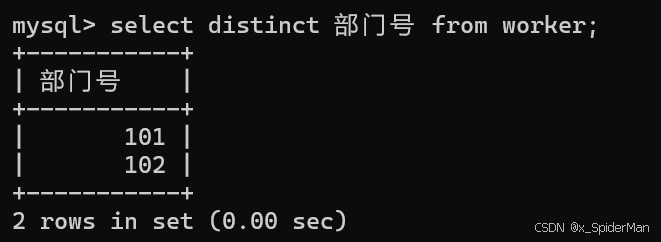
3、求出所有职工的人数(count:统计每行的数据总数)
select count(姓名) from worker;
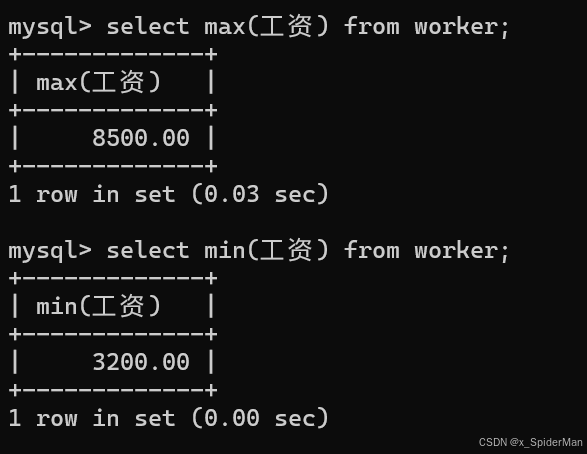
4、列出最高工和最低工资
select max(工资) from worker;
select min(工资) from worker;
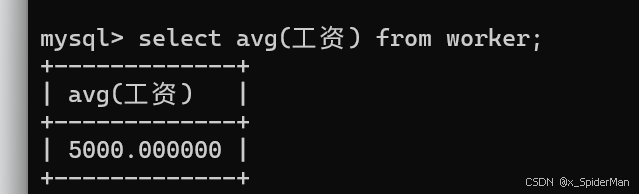
5、列出职工的平均工资和总工资
select avg(工资) from worker;
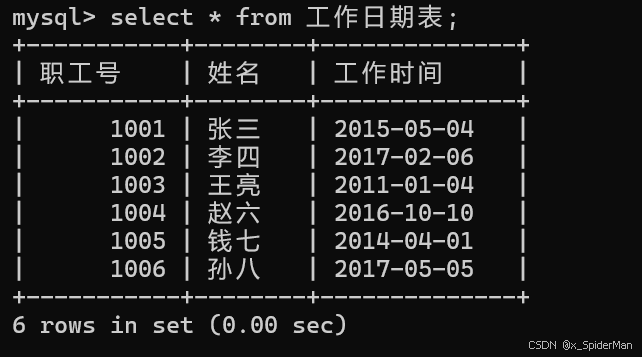
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
create table 工作日期表 as select 职工号,姓名,工作时间 from worker;
select * from 工作日期表;
7、显示所有群众的年龄 (floor:对数据取整,DATEDIFF:计算两个日期之间相差的天数,now:获取当前系统时间,as:取别名)
select 姓名,(floor(DATEDIFF(now(),出生日期)/365))as 年龄 from worker where 政治面貌='群众';

8、列出所有姓张的职工的职工号、姓名和出生日期
select 姓名,职工号,工作时间 from worker where 姓名 like '张%';

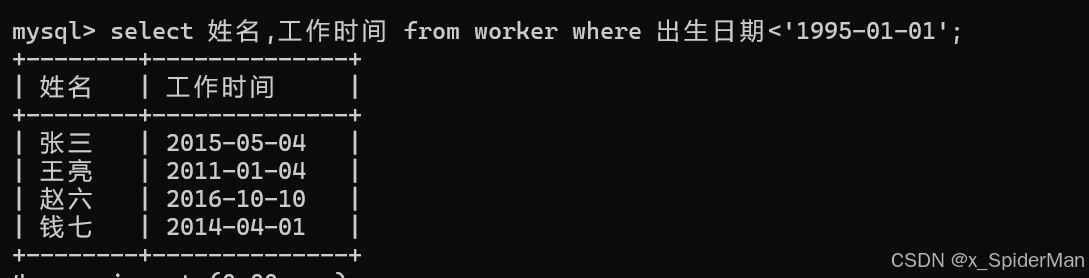
9、列出1995年以前出生的职工的姓名、参加工作日期
select 姓名,工作时间 from worker where 出生日期<'1995-01-01';
10、列出工资在3000-5000之间的所有职工姓名
select 姓名 from worker where 工资<5000 and 工资>3000;
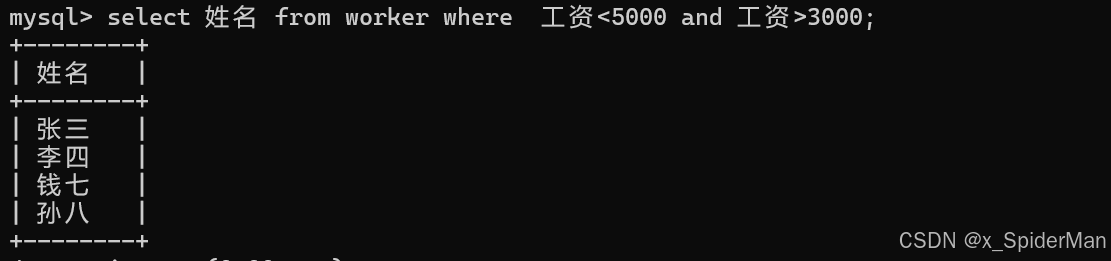
11、列出所有张姓和李姓的职工姓名(like:模糊匹配,"%"是通配符,代表任意字符序列)
select 姓名 from worker where 姓名 like '张%' or 姓名 like '李%';
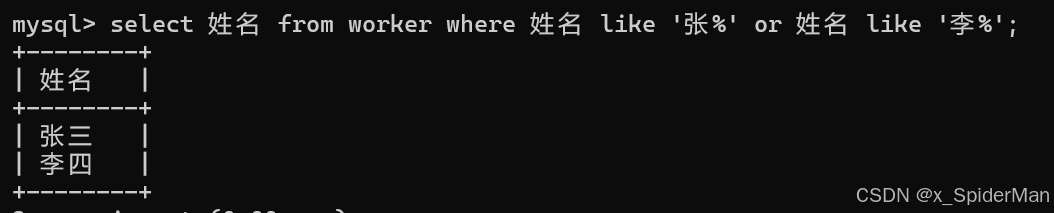
12、列出所有部门号为101和102的职工号、姓名、党员否
mysql> SELECT
-> 职工号,
-> 姓名,
-> CASE
-> WHEN 政治面貌 = '党员' THEN '是'
-> ELSE '否'
-> END AS 党员否
-> FROM
-> worker
-> WHERE
-> 部门号 IN (101, 102);
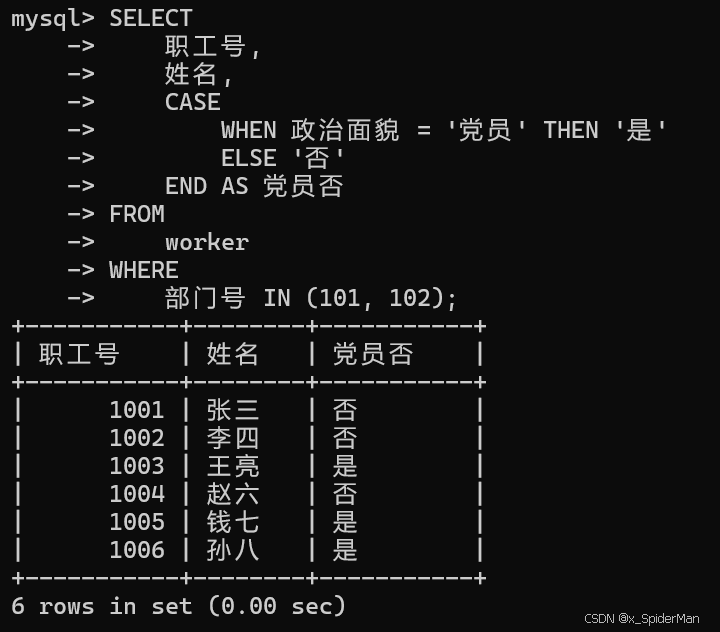
13、将职工表worker中的职工按出生的先后顺序排序
select * from worker order by 出生日期;
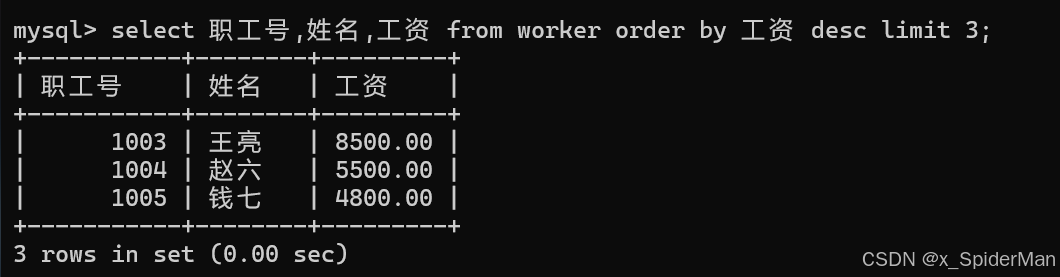
14、显示工资最高的前3名职工的职工号和姓名
select 职工号,姓名,工资 from worker order by 工资 desc limit 3;
15、求出各部门党员的人数(group by:分组)
select 部门号,count(政治面貌) from worker where 政治面貌='党员' group by 部门号;

16、统计各部门的工资和平均工资
select 部门号,sum(工资) as 部门工资总和,avg(工资) as 部门平均工资 from worker group by 部门号

17、列出总人数大于3的部门号和总人数(having:筛选出符合条件的数据)
select 部门号,count(*) as 总人数 from worker group by 部门号 having count(*)>3;

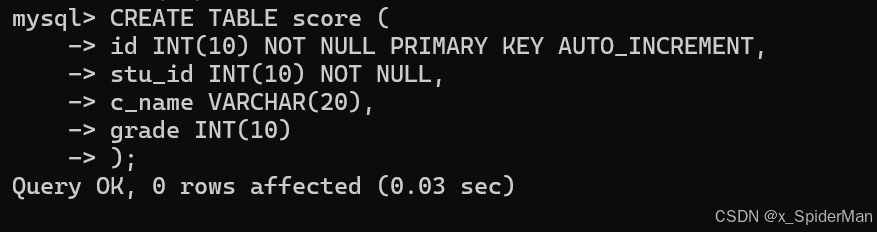
题目二要求:创建student和score表,student表含有字段id,姓名,性别,出生年份,专业,居住地。score表含有字段id,姓名,成绩,对两张表进行多表查询的相关操作
创建表并插入数据
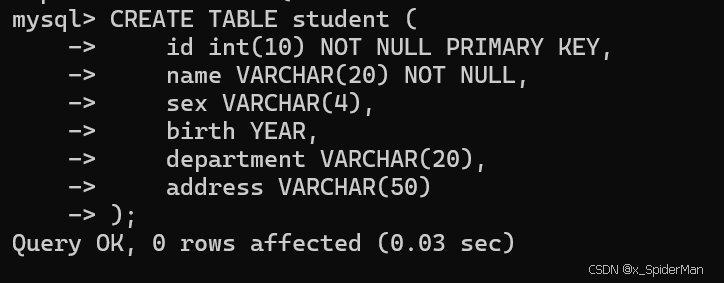
CREATE TABLE student (
id int(10) NOT NULL PRIMARY KEY,
name VARCHAR(20) NOT NULL,
sex VARCHAR(4),
birth YEAR,
department VARCHAR(20),
address VARCHAR(50)
);
CREATE TABLE student (
id int(10) NOT NULL PRIMARY KEY,
name VARCHAR(20) NOT NULL,
sex VARCHAR(4),
birth YEAR,
department VARCHAR(20),
address VARCHAR(50)
);
插入数据
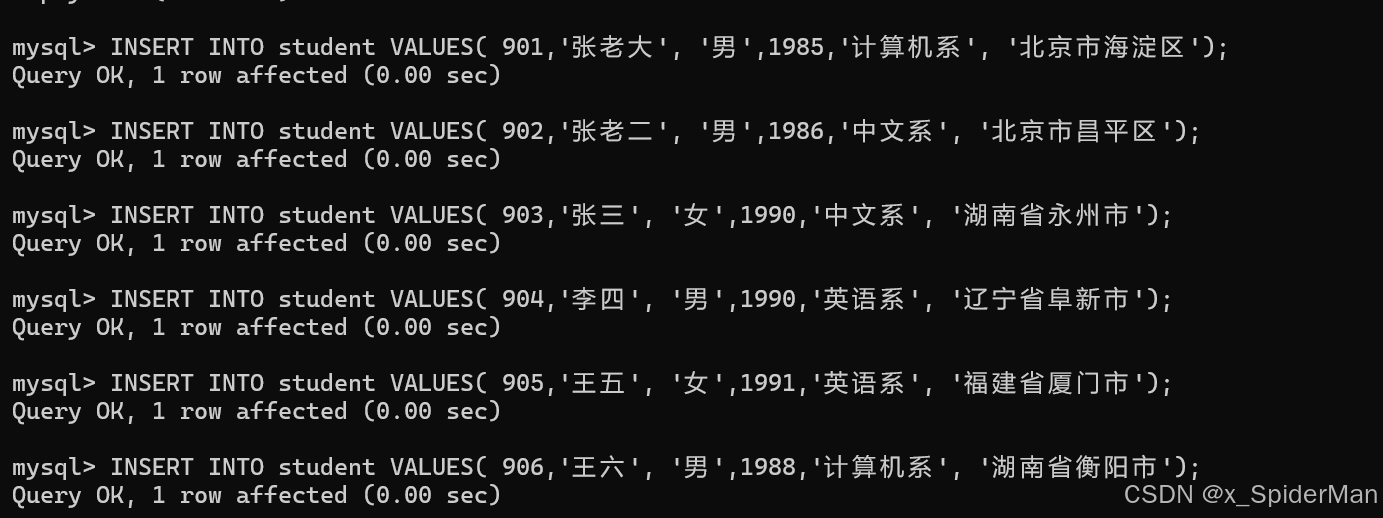
INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区');
INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);
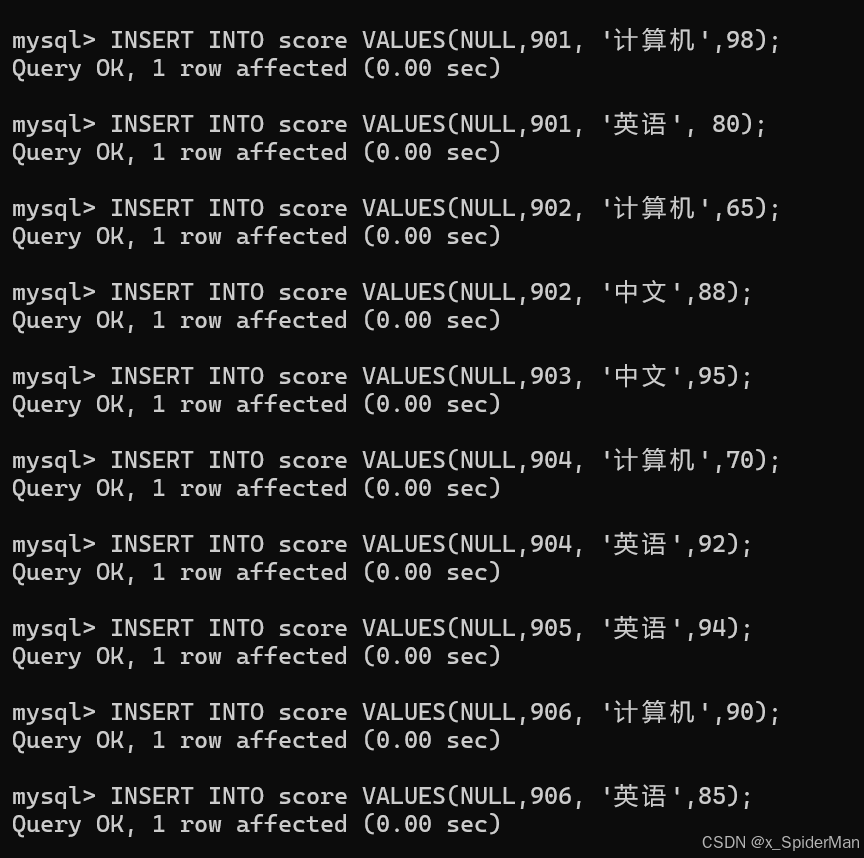
1.查询student表的所有记录
select * from student;
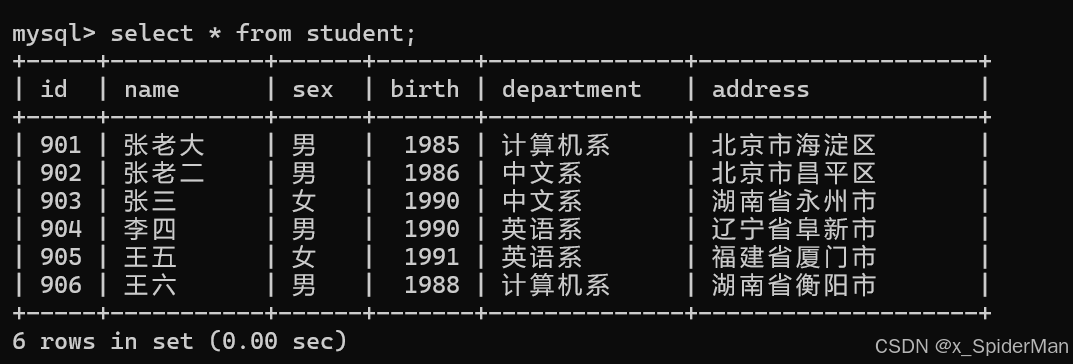
2.查询student表的第2条到4条记录
select * from student limit 1,3;
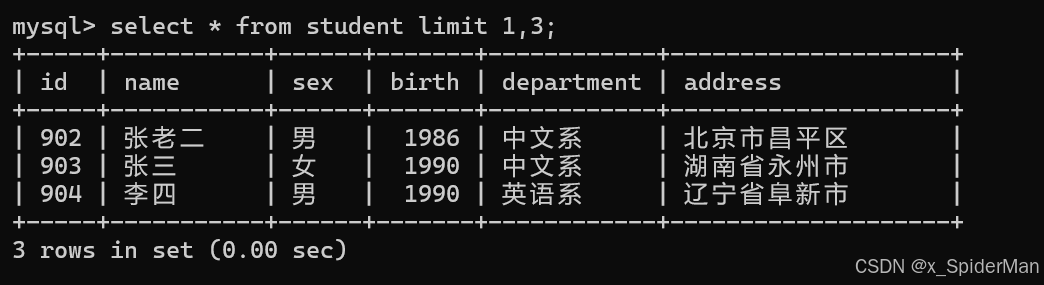
3.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
select id,name,department from student
4.从student表中查询计算机系和英语系的学生的信息
select * from student where department='计算机系' or department='英语系';
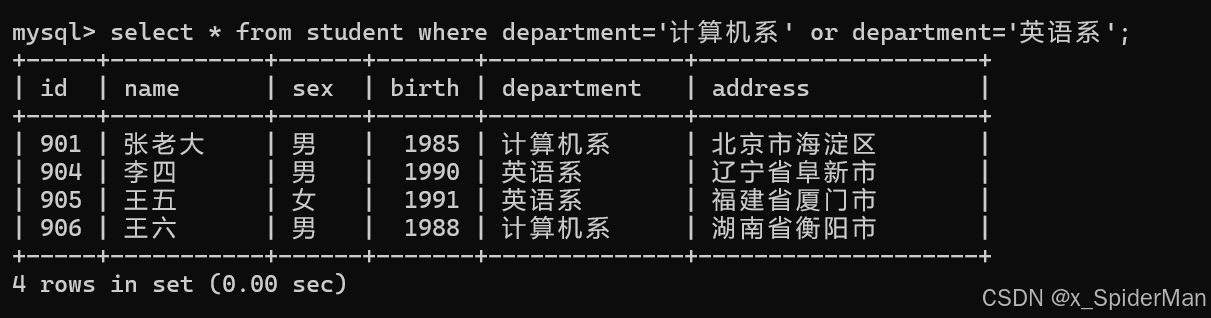
5.从student表中查询年龄35~40岁的学生信息
select name from student where year(curdate())-birth>35 and year(curdate())-birth<40;

6.从student表中查询每个院系有多少人
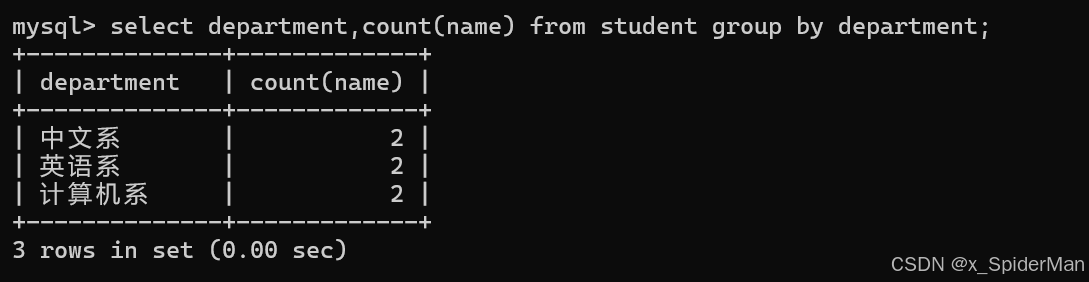
select department,count(name) from student group by department;
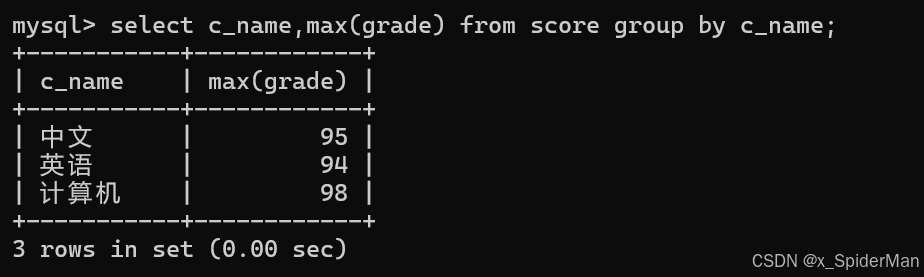
7.从score表中查询每个科目的最高分
select c_name,max(grade) from score group by c_name;
8.查询李四的考试科目(c_name)和考试成绩(grade)
select name,c_name,grade from student,score where student.id=score.stu_id and student.name='李四';

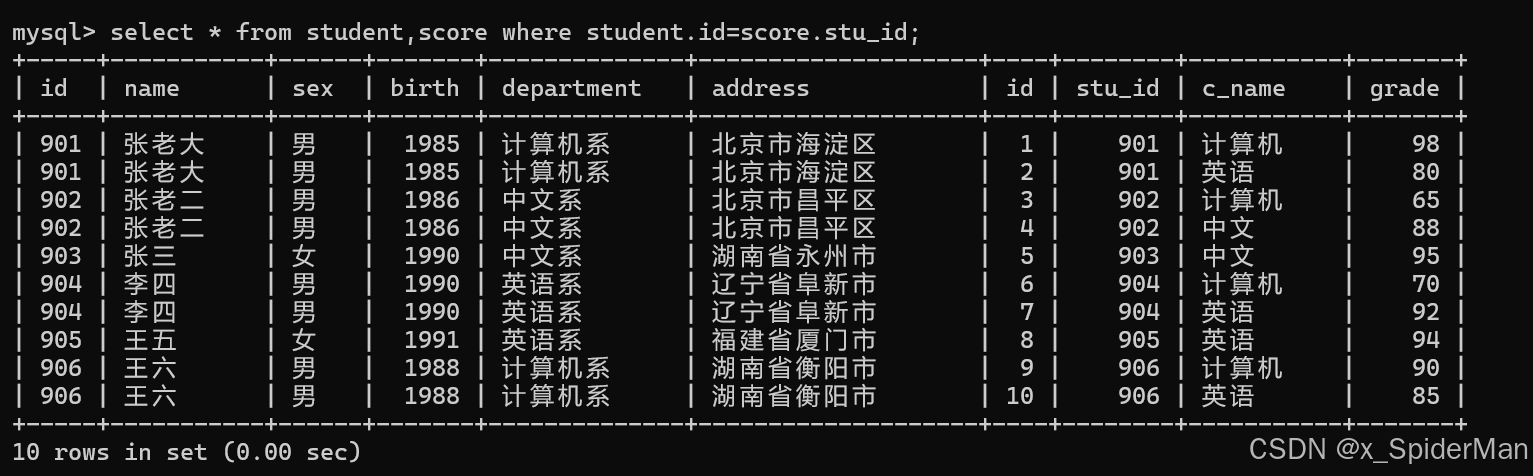
9.用连接的方式查询所有学生的信息和考试信息
select * from student,score where student.id=score.stu_id;
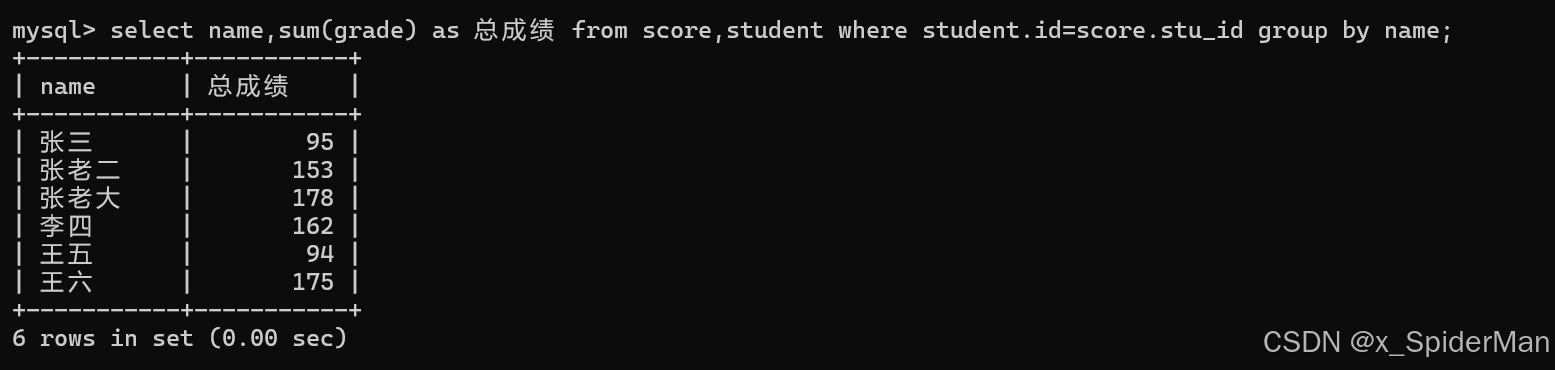
10.计算每个学生的总成绩
select name,sum(grade) as 总成绩 from score,student where student.id=score.stu_id group by name;
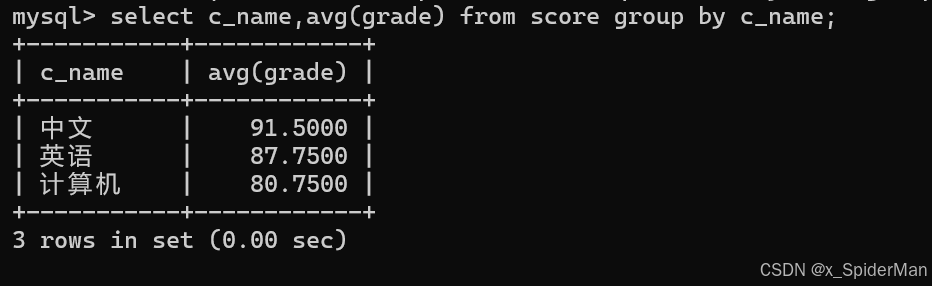
11.计算每个考试科目的平均成绩
select c_name,avg(grade) from score group by c_name;
12.查询计算机成绩低于95的学生信息
select name,grade from score,student where student.id=score.stu_id and c_name='计算机' and grade<95;

13.查询同时参加计算机和英语考试的学生的信息
select id,name from student where id in(select stu_id from score where c_name='计算机') and id in(select stu_id from score where c_name='英语');

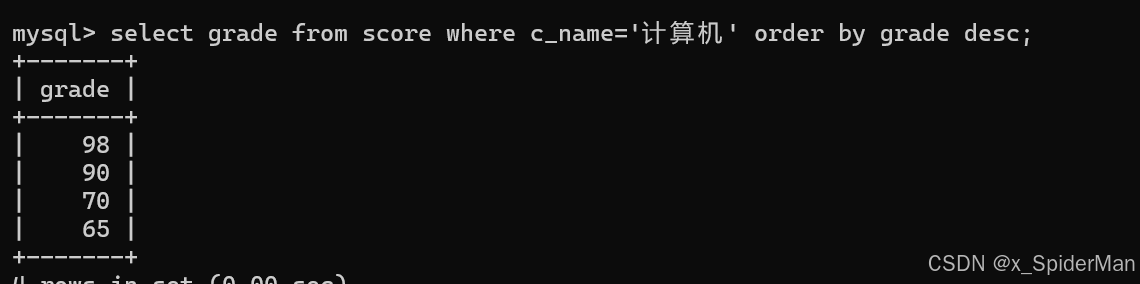
14.将计算机考试成绩按从高到低进行排序(desc:从高到低,asc:从低到高)
select grade from score where c_name='计算机' order by grade desc;
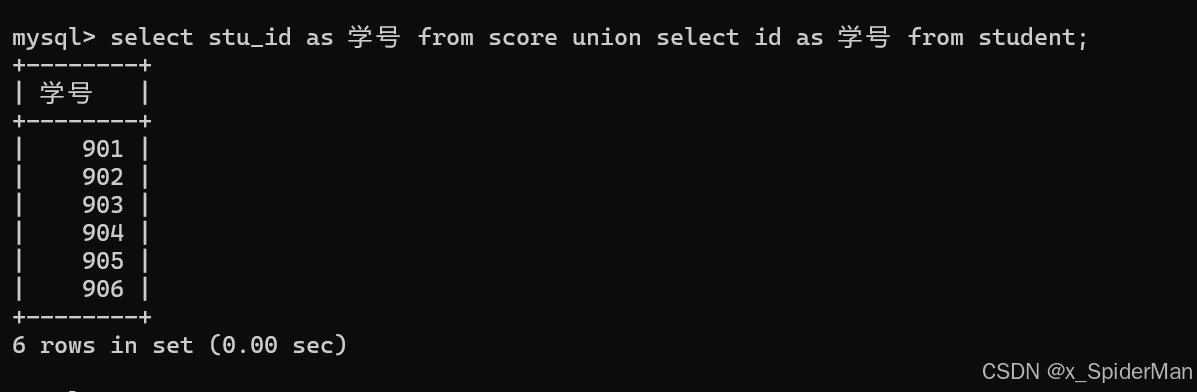
15.从student表和score表中查询出学生的学号,然后合并查询结果
select stu_id as 学号 from score union select id as 学号 from student;
16.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
select name,department,c_name,grade from student join score on student.id=score.stu_id where name like '张%' or name like '王%';
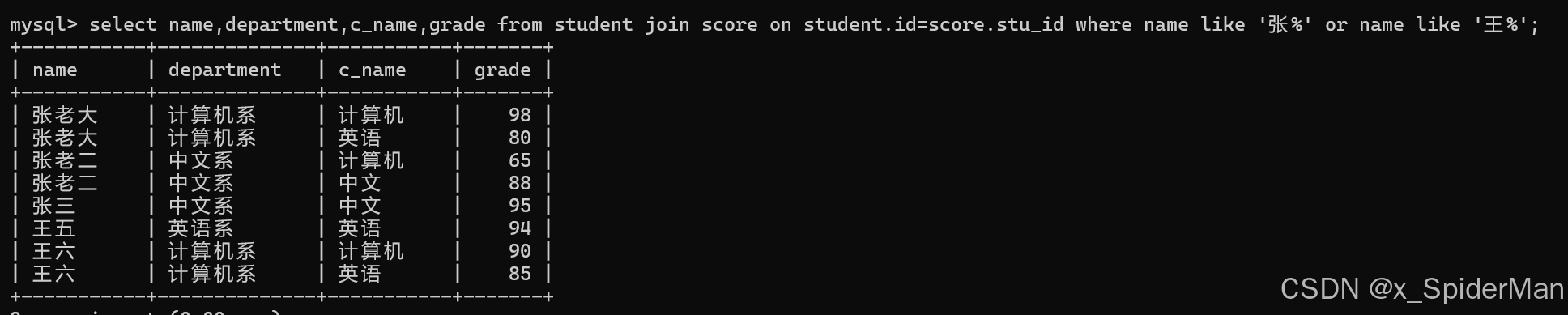
17.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
SELECT name,YEAR(CURDATE()) - birth AS age,department,c_name,grade,address FROM score JOIN student ON score.stu_id = student.id WHERE address LIKE '%湖南%';






















 5451
5451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









