




 本文深入探讨了Java面试中的核心知识点,包括Object类方法、类加载机制、多态使用原则、集合类内部实现、SpringMVC及Struts2的工作流程、数据库索引与事务管理、Hibernate与MyBatis对比等内容。
本文深入探讨了Java面试中的核心知识点,包括Object类方法、类加载机制、多态使用原则、集合类内部实现、SpringMVC及Struts2的工作流程、数据库索引与事务管理、Hibernate与MyBatis对比等内容。
综合这段时间的面试经验和自己错的题目,以及详解
1.以下哪几个方法不是object自带的方法:toString,clone,equal,hashcode。
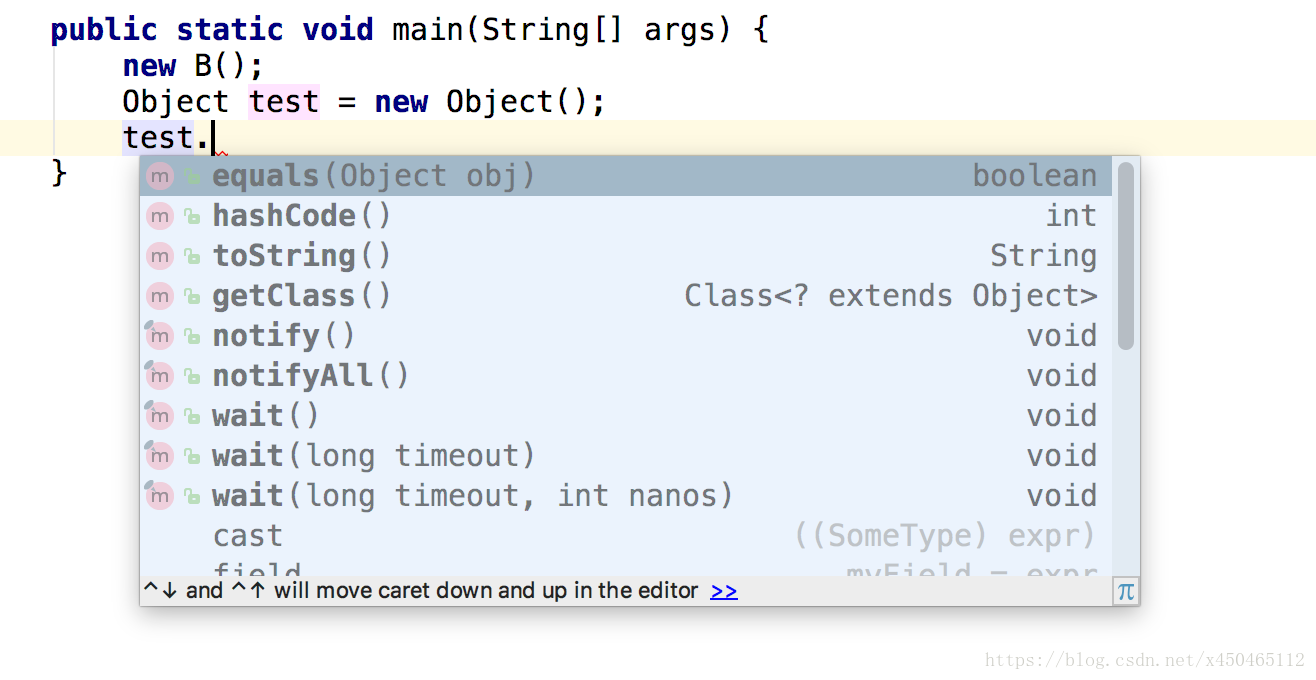 回来敲代码得知。没有clone方法,查了下资料
回来敲代码得知。没有clone方法,查了下资料
protected native Object clone() throws CloneNotSupportedException;这里原生使用了protected。但是所有的类都是object子类,为啥不能使用,继续查资料。
需要实现clonable接口!然后重写clone方法!
2.以下输出结果:
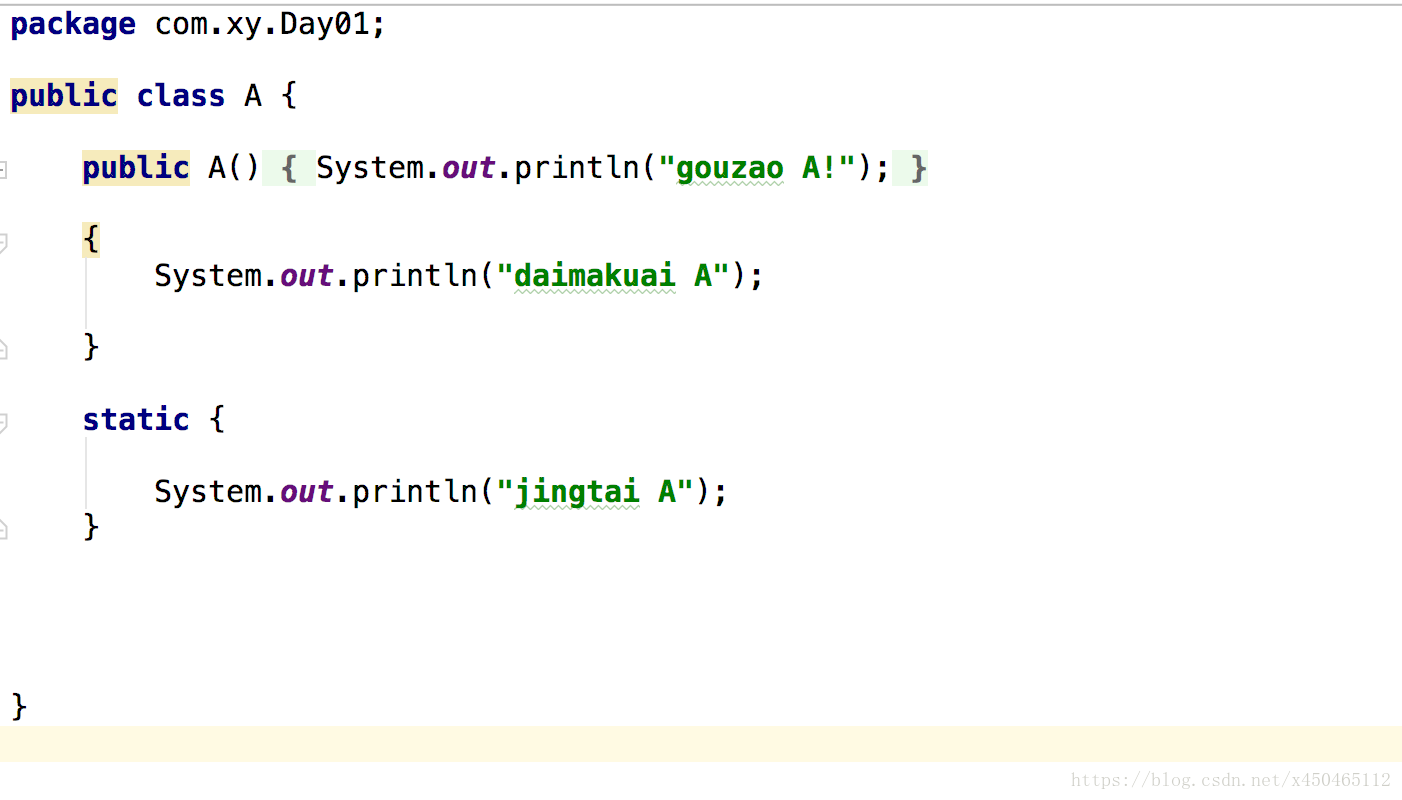
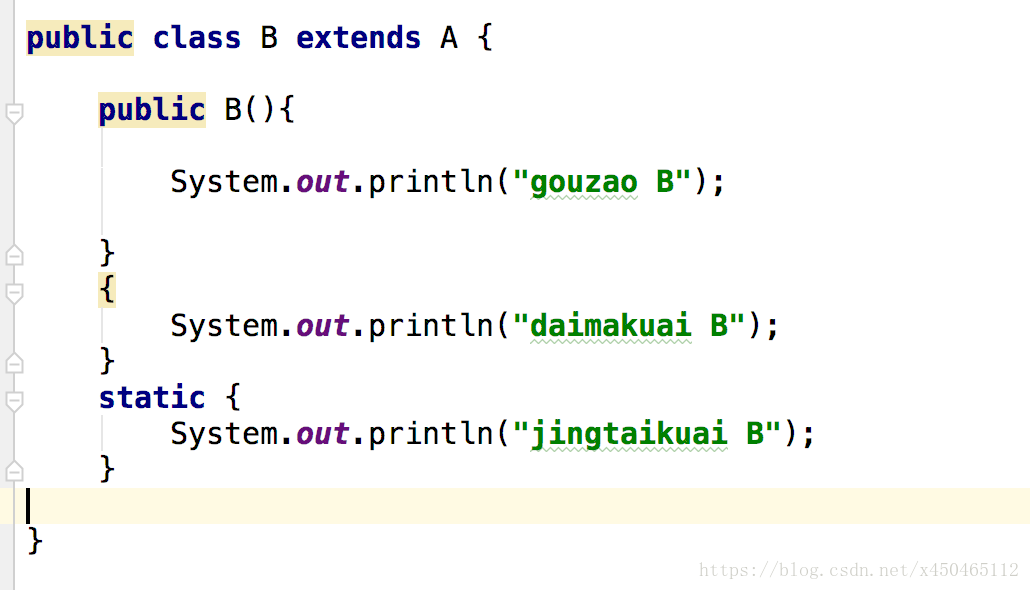
输出结果为:

说明创建类的顺序为:
1.先生成父类,同时执行父类的静态代码块(静态代码块的优先级是最高的)
2.执行子类的静态代码块
3.执行父类的代码块
4.执行父类的构造方法
5.执行子类的代码块
6.执行子类的构造方法
3.多态经典问题
记住优先级:this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O);
4.List和Map的问题
List和set都是Collection的接口
List下面分
Arraylist:底层采用数组的数据结构,增删慢,查询快,
原理是因为在开辟的时候,是一串连续地址的数组
源代码中。默认的构造方法,new ArrayList
是使用了
EmptyArray.OBJECT;
也就是生成了一个object[0]的数组,
如果采用传集合进去的构造方法,则先将此集合转换为数组:collection.toArray()
然后使用system.arraycopy的方法,新生成一个以入参集合的长度数组,返回
add方法:
把array成员变量赋给局部变量,把长度成员变量赋给局部变量。判断当前集合的长度和数组的长度是否相等
,相等,则说明满了,然后判断当前集合长度是否小于6(有个常量),如果小于6,则把数组的长度增加12.
如果大于6,则把数组的长度增加当前集合的1/2.然后利用system.arraycopy的方法,返回新数组
linkedList:
基于双向链表的数据结构,前面是前节点信息,中间是数据内容,后面的是后节点信息
空的构造函数是相当于前节点信息和后节点信息都指向自己本身的内容,相当于是一个空的链表
add方法:
1.根据本身的entry,生成一个new entry,新的entry的前节点信息和后节点信息都指向自己
2.调整本身entry的前后节点信息
vector:线程安全的集合(底层也是数组,只是是线程安全的)
set:hashSet(),底层使用hashmap的存储结构
linkedhashSet(),底层使用linkedHashMAP
Map:HashMap:底层使用的数组结构,只不过数组里面每一项是一个个的链表,
Entry[] table
Entry里面
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; ……}
put方法:如果key为空,则使用putfornullkey的方法,将value放置在数组的第一个位置
不为空,则根据key的key的hashcode重新计算hash值
搜索指定的hash值在对应table中的索引,使用indexFor的方法
如果i索引处的的entry不为null。通过循环不断遍历e元素的下一个元素
为空,则利用addEntry加载在索引处,如果有元素,判断是否equal,如果equal,则覆盖
get方法:如果为null,则直接返回第一个
不为空,则通过key的hashcode再计算hash方法,通过indexfor,找到元素下标。再调用equals方法找到元素
linkedHashMap:保留了插入的顺序
HashTable:线程安全
5.SpringMVC的工作流程
1.通过dispatcherServlet
2.dispatcherServlet将URL里面的请求通过handlerMapper去映射到handlerexcutorchain
3.dispatcherServlet找到合适的adapt去处理
4.返回给dispatcher一个modelandview
5.dispatcher通过viewresolver解析出真正的视图返回给用户
6.strut2的工作流程
1.通过过滤器fillerdispatcher,通过actionmapper去判断是否归struts2框架处理
2.判断是处理,然后生成actionproxy
3.通过configmanager去获取struts.xml的配置文件
4.创建actioninvocation去执行方法,执行方法前会经过过滤器1,2,3.。。填充值之类的
5.再出来3,2,1
6.返回sturts.xml里面的结果
7.数据库的索引
数据库的索引类型:1.普通索引 2.主键索引 3.唯一索引 4.组合索引
索引应该怎么创建比较好?

这里详解。
索引其实是一种数据结构
8.数据库的事务(mysql)
事务隔离方式分为四种:1.读未提交:没有提交的事务,别的事务也能读的到,导致脏读
2.读已提交:只能读取到已经提交的事务。但是如果之前读到的是1.提交后改为了2.则读到2.导致不可重复读
3.不可重复读:保证读取的唯一性。之前读到的是1.即使提交改为了2.也读的是1.但是如果读取的是范围,里面插入了新的数据。则会把新的数据也读出来。导致幻读
4.序列话读:相当于把整个表都锁了
9.spring 的隔离方式(7种。):
常用的:require:有事务,则加入事务,无事务,则新建事务
support: 有事务,就加入事务,无事务,就非事务进行
mandatory:支持当前事务,如果没有事务,则抛出异常
require_new :新建事务,挂起当时事务
never:非事务方式,如果有事务,排除异常
not_support:非事务。挂起当前事务
nested
10.hibernate与mybaits(转载 【 落尘曦的博客:http://blog.youkuaiyun.com/qq_23994787 】):
1.开发速度上面:mybatis比hibernate更好上手,如果一个项目中大部分都是简单的增删改查,建议使用hibernate,因为里面有成型的封装,
如果一个项目中有复杂的sql语句。选择mybatis上面比较好,去维护sql也比较方便
2.开发工作量:hibernate有很好的映射机制,可以更专注业务代码,mybatis需要自己去维护sql和mapper以及resultmapper
3.sql优化方面:hibernate需要把所有的字段查询出来,调sql时候需要打印出来再调,mybatis不需要。可以更精细的去管理sql,但是hibernate自带日志,mybatis需要第三方log4j来去执行
4.对象管理方面:hibernate是完整的对象/关系映射方案,用户不需要去考虑底层数据库,只需要关心hibernate的对象状态,mybatis在这一块比较欠缺
5.缓存方面
11.hibernate工作流程:

三种状态:
临时态:new 出来的对象 没有id 没有和session绑定
持久态 有具体id,与session绑定,没有提交
游离态 有id,但是没有与session绑定

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









