



 本文详细讲解了CART算法、基尼指数应用及过拟合解决方案,通过Python代码展示数据预处理和决策树构建过程。
本文详细讲解了CART算法、基尼指数应用及过拟合解决方案,通过Python代码展示数据预处理和决策树构建过程。
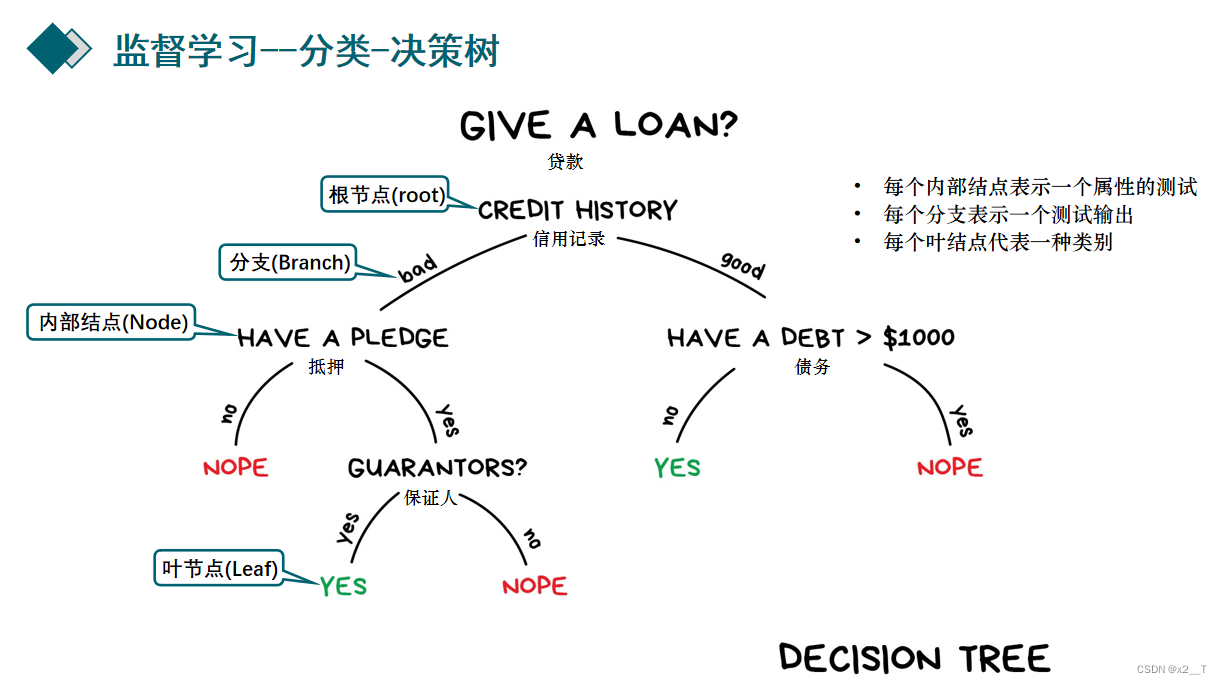
著名的决策树算法CART就是使用基尼指数来进行划分属性的挑选(当然,CART本身是二叉树结构,这一点和上述的 ID3 和 C4.5
不太一样)。
CART还是一个回归树,回归解析用来决定分布是否终止。理想地说每一个叶节点里都只有一个类别时分类应该停止,但是很多数据并不容易完全划分,或者完全划分需要很多次分裂,必然造成很长的运行时间,所以CART可以对每个叶节点里的数据分析其均值方差,当方差小于一定值可以终止分裂,以换取计算成本的降低。CART和ID3一样,存在偏向细小分割,即过度学习(过度拟合的问题),为了解决这一问题,对特别长的树进行剪枝处理,直接剪掉。
(一)实现求解基尼指数
import numpy as np
def calcGini(data_y): #根据基尼指数的定义,根据当前数据集中不同标签类出现次数,获取当前数据集D的基尼指数
m = data_y.size #获取全部数据数量
labels = np.unique(data_y) #获取所有标签值类别(去重后)
gini = 1.0 #初始基尼系数
for i in labels: #遍历每一个标签值种类
y_cnt = data_y[np.where(data_y==i)].size / m #出现概率
gini -= y_cnt**2 #基尼指数
return gini
测试:
print(calcGini(np.array([1,1,2,3,2,2,1,1,3])))
(二)实现数据集切分
def splitDataSet(data_X,data_Y,fea_axis,fea_val): #根据特征、和该特征下的特征值种类,实现切分数据集和标签
#根据伪算法可以知道,我们要将数据集划分为2部分:特征值=a和特征值不等于a
eqIdx = np.where(data_X[:,fea_axis]==fea_val)
neqIdx = np.where(data_X[:,fea_axis]!=fea_val)
return data_X[eqIdx],data_Y[eqIdx],data_X[neqIdx],data_Y[neqIdx]
(三)实现选取最优特征和特征值划分
def chooseBestFeature(data_X,data_Y): #遍历所有特征和特征值,选取最优划分
m,n = data_X.shape
bestFeature = -1
bestFeaVal = -1
minFeaGini = np.inf
for i in range(n): #遍历所有特征
fea_cls = np.unique(data_X[:,i]) #获取该特征下的所有特征值
# print("{}---".format(fea_cls))
for j in fea_cls: #遍历所有特征值
newEqDataX,newEqDataY,newNeqDataX,newNeqDataY=splitDataSet(data_X,data_Y,i,j) #进行数据集切分
feaGini = 0 #计算基尼指数
feaGini += newEqDataY.size/m*calcGini(newEqDataY) + newNeqDataY.size/m*calcGini(newNeqDataY)
if feaGini < minFeaGini:
bestFeature = i
bestFeaVal = j
minFeaGini = feaGini
return bestFeature,bestFeaVal #返回最优划分方式
(四)创建CART决策树
def createTree(data_X,data_Y,fea_idx): #创建决策树
y_labels = np.unique(data_Y)
#1.如果数据集中,所有实例都属于同一类,则返回
if y_labels.size == 1:
return data_Y[0]
#2.如果特征集为空,表示遍历了所有特征,使用多数投票进行决定
if data_X.shape[1] == 0:
bestFea,bestCnt = 0,0
for i in y_labels:
cnt = data_Y[np.where(data_Y==i)].size
if cnt > bestCnt:
bestFea = i
bestCnt = cnt
return bestFea
#按照基尼指数,选择特征,进行继续递归创建树
bestFeature, bestFeaVal = chooseBestFeature(data_X,data_Y)
# print(bestFeature,bestFeaVal)
feaBestIdx = fea_idx[bestFeature]
my_tree = {feaBestIdx:{}}
#获取划分结果
newEqDataX,newEqDataY,newNeqDataX,newNeqDataY = splitDataSet(data_X,data_Y,bestFeature,bestFeaVal)
#删除我们选择的最优特征
newEqDataX = np.delete(newEqDataX,bestFeature,1)
newNeqDataX = np.delete(newNeqDataX,bestFeature,1)
fea_idx = np.delete(fea_idx,bestFeature,0)
my_tree[feaBestIdx]["{}_{}".format(1,bestFeaVal)] = createTree(newEqDataX,newEqDataY,fea_idx)
my_tree[feaBestIdx]["{}_{}".format(0,bestFeaVal)] = createTree(newNeqDataX,newNeqDataY,fea_idx)
return my_tree
(五)测试函数
def preDealData(filename):
df = pd.read_table(filename,'\t',header = None)
columns = ["age","prescript","astigmatic","tearRate"] # df.columns = ["age","prescript","astigmatic","tearRate","Result"] #https://zhuanlan.zhihu.com/p/60248460
#数据预处理,变为可以处理的数据 #https://blog.youkuaiyun.com/liuweiyuxiang/article/details/78222818
new_df = pd.DataFrame()
for i in range(len(columns)):
new_df[i] = pd.factorize(df[i])[0] ##factorize函数可以将Series中的标称型数据映射称为一组数字,相同的标称型映射为相同的数字。
data_X = new_df.values
data_Y = pd.factorize(df[df.shape[1]-1])[0] #factorize返回的是ndarray类型
data_Y = np.array([data_Y]).T
return data_X,data_Y,columns
data_X,data_Y,fea_names = preDealData("lenses.txt")
fea_Idx = np.arange(len(fea_names))
print(createTree(data_X,data_Y,fea_Idx))


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









