




 SitNet是一种用于零样本哈希的深度学习方法,旨在解决传统哈希方法在处理未知类别时的局限性。它通过词向量转移相似性,利用multi-task结构优化哈希编码的可区分性和语义结构,设计离散哈希层避免信息损失。实验表明,SitNet在无监督和有监督方法中表现出色,尤其在处理零样本任务时。
SitNet是一种用于零样本哈希的深度学习方法,旨在解决传统哈希方法在处理未知类别时的局限性。它通过词向量转移相似性,利用multi-task结构优化哈希编码的可区分性和语义结构,设计离散哈希层避免信息损失。实验表明,SitNet在无监督和有监督方法中表现出色,尤其在处理零样本任务时。
目录
Motivation
1、传统的哈希方法对已知类别的性能很好(因为有正确的标签信息指导哈希学习),但是无法适用于新兴概念(从未见过的类别)。一方面,对新概念进行人工标注的成本高;另一方面,标注后再重新训练哈希函数的时间成本大。
2、Zero-shot Hashing研究如何构建通用的哈希模型,从而对已知类别和未知类别都能较好地进行哈希编码。ZSH的主要挑战是如何从已知类别推测出未知类别的信息。而传统的哈希方法认为类别之间是互相独立的(0/1形式的标签向量),弊端是导致每个类别既不能从与它相关的类别中获得有用信息,也不能将它的信息贡献给其他类别。zero-shot learning研究表明,可以通过词向量构建已知类别和未知类别之间的联系,来迁移监督信息。
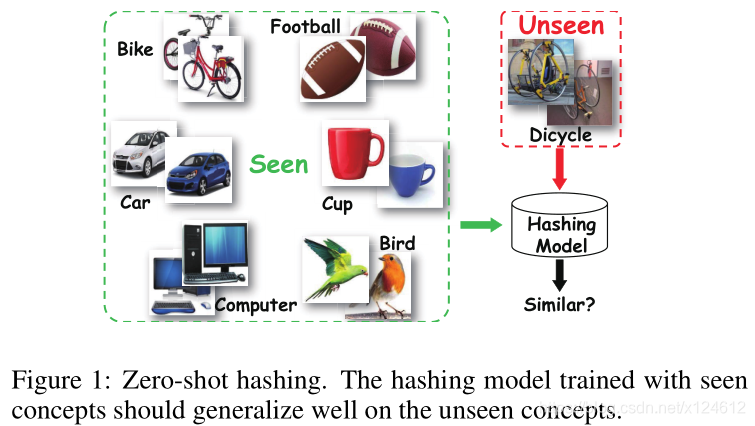
Contributions
提出基于CNN的ZSH方法,Discrete Similarity Transfer Network (SitNet),考虑以下三个方面:
1、 similarity transfer:利用类别标签的词向量作为辅助信息,并且迫使网络生成的哈希编码能够保留词向量空间中的语义结构
2、 discriminability:利用multi-task结构来联合优化regularized center loss和semantic embedding loss,以保证可区分性
3、 discrete layer:传统的基于CNN哈希方法要么分别学习哈希编码和哈希函数,要么采用实值松弛,本文设计 discrete layer来直接生成哈希编码,避免量化导致的信息损失。并且,通过straight-through estimator来计算discrete layer的梯度,以保证梯度的反向传播
贡献总结为:
1、提出SitNet,可以通过词向量空间迁移监督知识,从而对未知类别也能生成有效的哈希编码;
2、采用multi-task结构,同时考虑已知类别的监督信息(regularized center loss)和类别之间的关系(semantic embedding loss),这是首次将CNN哈希用于解决ZSH问题;
3、设计 discrete layer来直接生成哈希编码,避免量化导致的信息损失,并且采用straight-through estimator来保证discrete layer的反向传播
Note: Yang et al. [2016]提出的zero-shot hashing不能有效地利用监督信息,也没有借助深度学习。本文基于此改进。
Methods
Network Architecture
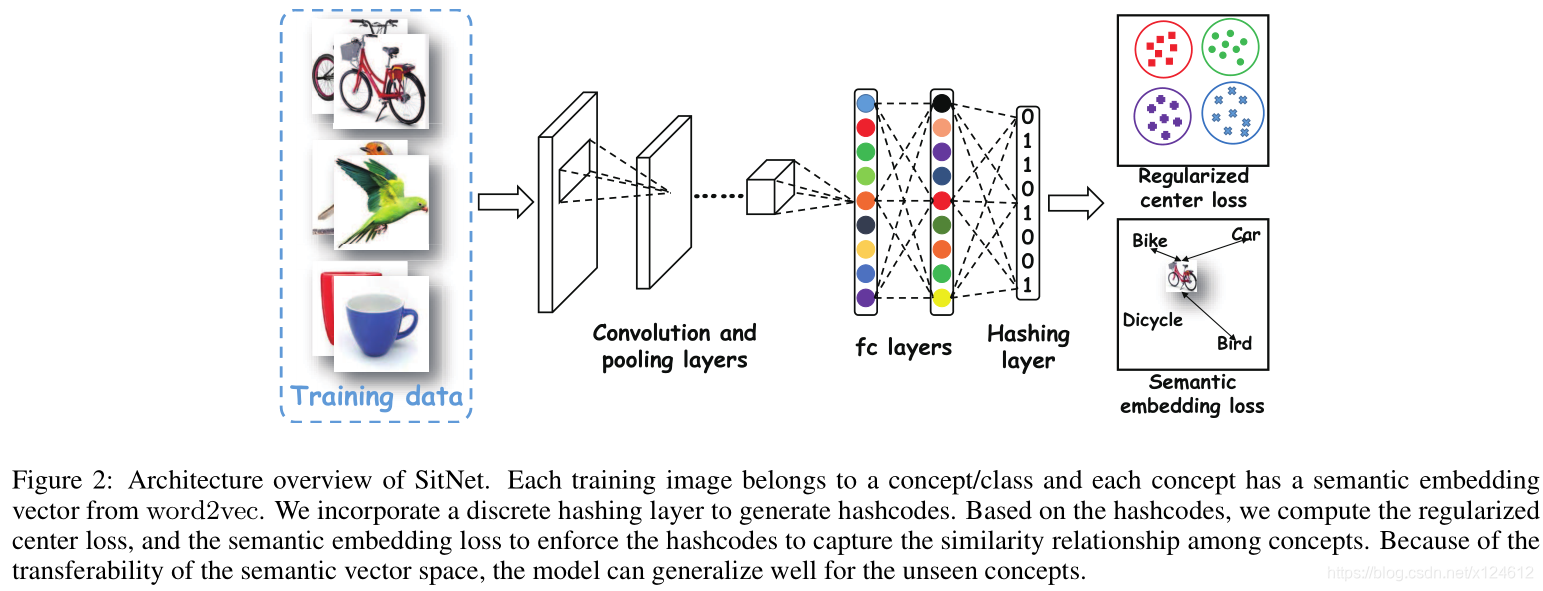 整体框架如上,借助AlexNet提取图像特征(5 conv+2 fc),然后经过discrete hashing layer得到哈希编码(全连接+sgn激活函数),再经过全连接层将哈希编码映射到词向量空间中,从而计算loss。损失函数包含两部分, 生成的词向量和目标词向量的max
整体框架如上,借助AlexNet提取图像特征(5 conv+2 fc),然后经过discrete hashing layer得到哈希编码(全连接+sgn激活函数),再经过全连接层将哈希编码映射到词向量空间中,从而计算loss。损失函数包含两部分, 生成的词向量和目标词向量的max
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









