







图像语义分割开源数据集中的标签通常是多类的,并不一定适合实际场景的应用。比如某个场景只需要分割道路,其他场景都是背景。这就需要提取对应场景的标签。比如马赛州的语义分割数据集集包含了建筑和道路。如果只需要分割道路,那需要把道路的标签提取出来。

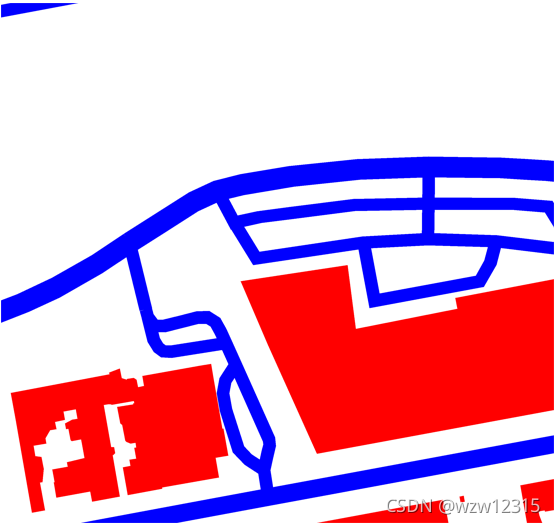
知识点:图像是RGB三通道颜色组成,原图中颜色越接近红色的地方在红色通道越接近白色。在纯红的地方在红色通道会出现纯白。绿色、蓝色也是同样的道理。
'''
通常做语义分割的时候,可能标签是多个语义的标签,如果你需要做二分割,比如水体,背景,那么存在将多标签修改或者
提取为二标签
'''
import numpy as np
import cv2
label = cv2.imread('F:\\SemanticImageDataSet\\CITY-OSM\\berlin\\berlin2_labels.png',cv2.IMREAD_UNCHANGED)
#cv2读取图像的通道排序是BGR
bule = label[:,:,0]
green = label[:,:,1]
red = label[:,:,2]
cv2.imwrite('F:\\SemanticImageDataSet\\CITY-OSM\\berlin\\berlin2_labels_road.png',red)分割结果如下:
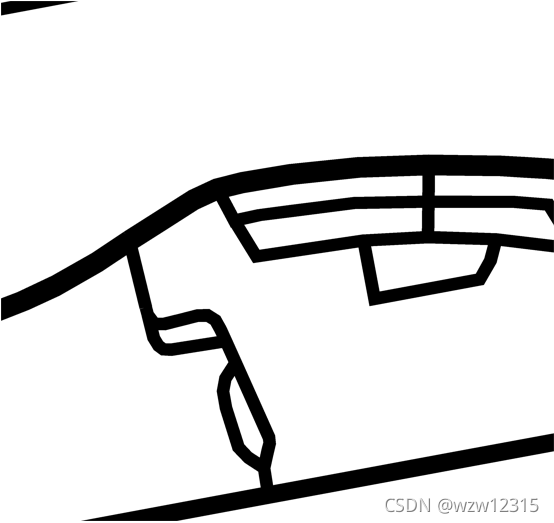

















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









