







一、概念
命名实体识别(Named Entity Recognition,NER)中的“命名实体”一般是指文本中具有特别意义或者指代性非常强的实体,可分为三大类(实体类、时间类和数字类)和七小类(人名、机构名、地名、时间、日期、货币和百分比)。
命名实体识别的任务就是识别出文本中的命名实体,通常分为两个过程:实体边界识别和实体类别的确定。
二、问题转化
中文命名实体识别的本质就是序列标注。
设定3种命名实体标注符号PER、LOC、ORG分别代表人名、地名、机构名;3种命名实体标注符号B、I、O分别代表实体开始、实体中间、其它。
这样就有7种标记L={B-PER,I-PER,B-LOC,I-LOC,B-ORG,I-ORG,O},这样就把命名实体识别转换成了每个字的分类问题。例如:
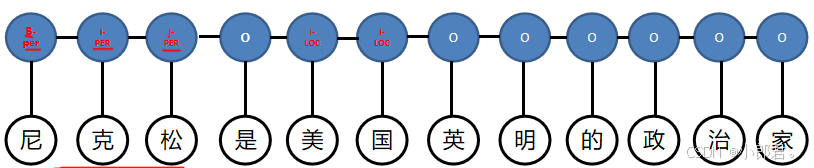
尼克松是一个人名吧,那就把开始的一个字‘尼’标注为 实体开始 ,即B-PER,其他的字标注为实体中间,即I-PER,依次类推标注其他命名实体。
这样就可以用分类模型去做了吧,但要注意以下几点:
- 中文词灵活多变:有些词语在不同语境下可能是不同的实体类型,辽宁有个市叫“沈阳”,也有一些人名叫“沈阳”。有些取名叫“高富帅”,但“高富帅” 是一个现代流行的形容词。
- 中文词的嵌套情况复杂:一些中文的命名实体中常常嵌套另外一个命名实体,如“北京大学附属中学”
- 中文词存在简化表达现象:通常对一些较长的命名实体词进行简化表达,如“北京大学”通常简化为“北大”,“北京大学附属中学”通常简化为“北大附中”
所以也并不是一个简单的分类,要把这些问题都考虑进模型中。
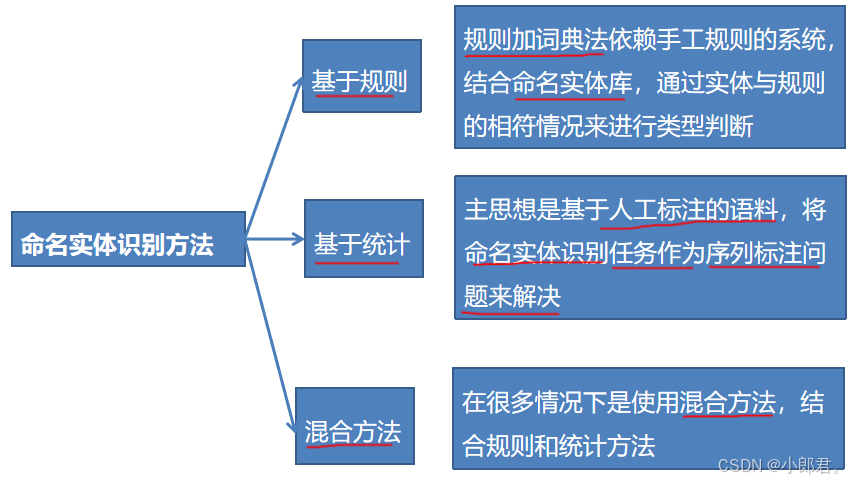
三、方法
主要有三大类方法
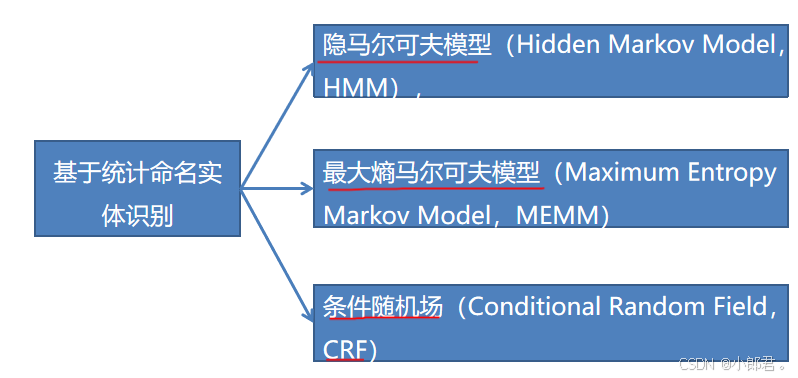
有了方法,那就构建模型呗,下面是基于统计的模型
四、CRF模型
这里简单介绍一下CRF模型,
**条件随机场(Conditional Random Fields, CRF)**是一种用于序列标注的概率图模型,广泛应用于自然语言处理任务,如命名实体识别(NER)、词性标注等。
CRF模型思想主要来源于最大熵模型。观察序列 X 和标注序列 Y 的条件概率 P(Y∣X),直接最大化条件概率来训练模型,相对于HMM和最大熵马尔可夫模型(MEMM),CRF模型它没有HMM那样严格的独立性假设,克服了MEMM标记偏置的缺点。
- 序列标注任务:给定输入序列
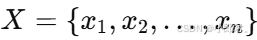 ,预测对应标注序列
,预测对应标注序列 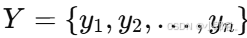 。
。 - CRF假设 Y 的条件概率可以通过一个图结构建模,常用的是线性链CRF。
1. 特征设计
因为输入序列X一般是一段文本序列,机器学习算法是不能直接使用的,需要将它们转化成机器学习算法可以识别的数值特征,然后再交给机器学习的算法进行操作。对于序列标注问题,需要先对输入序列进行特征提取。
&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









