






1. Beam Search 的基本概念
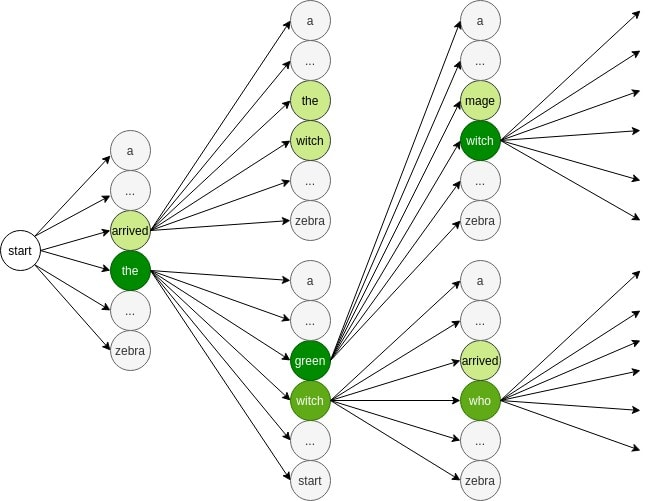
Beam Search 是一种启发式搜索算法,主要用于在序列生成任务中寻找最优或近似最优的输出序列。它是对贪心搜索(Greedy Search)的改进,通过在每一步保持 k 个最佳候选项来平衡搜索空间和计算效率。
2. 为什么需要 Beam Search?
在解释具体算法之前,让我们先理解为什么需要它:
- 解决贪心搜索的局限性:
- 贪心搜索每步只选择概率最高的一个词
- 容易陷入局部最优解
- 可能错过全局最优解
- 计算效率考虑:
- 穷举所有可能(暴力搜索)计算量过大
- Beam Search 提供了一个折中方案
3. Beam Search 算法步骤详解
让我们通过一个具体例子来说明,假设我们要生成一个英语句子:
Step 1: 初始化
- 设定 beam width (束宽) k,例如 k=3
- 含义: 每一步从词表中挑出3个最有可能的单词作为候选项
- 从起始标记 开始
Step 2: 第一步扩展
<START> →
- "I" (概率0.6)
- "The" (概率0.3)
- "A" (概率0.1)
保留前k个最高概率的候选项。
Step 3: 继续扩展
对每个保留的候选项,生成下一个可能的词,计算累积概率:
"I" →
- "I am" (0.6 × 0.5 = 0.30) # 第一大
- "I have" (0.6 × 0.3 = 0.18) # 第二大
- "I will" (0.6 × 0.2 = 0.12) # 第三大
"The" →
- "The cat" (0.3 × 0.4)
- "The dog" (0.3 × 0.3)
- "The man" (0.3 × 0.3)
"A" →
- "A beautiful" (0.1 × 0.4)
- "A small" (0.1 × 0.3)
- "A large" (0.1 × 0.3)
由于前三条路径的概率比其余的路径都要高,我们只保留前三条路径
"I" →
- "I am" (0.6 × 0.5 = 0.30) # 第一大
- "I have" (0.6 × 0.3 = 0.18) # 第二大
- "I will" (0.6 × 0.2 = 0.12) # 第三大
随后我们在这3条路径的基础上进行进一步的拓展
"I" →
- "I am" (0.6 × 0.5 = 0.30)
- "very"
- "a"
- "happy"
- "I have" (0.6 × 0.3 = 0.18)
- "dogs"
- "kids"
- "my"
- "I will" (0.6 × 0.2 = 0.12)
- "do"
- "sleep"
- "eat"
# 拓展后共有 3x3=9 条路径
Step 4: 选择和剪枝
- 从所有9个候选序列中选择概率最高的k个
- 继续下一轮扩展
4. 数学表达
对于序列生成,Beam Search 的目标是找到最大化以下概率的序列:
P ( y 1 , y 2 , . . . , y t ∣ x ) = ∏ i P ( y i ∣ y 1 , y 2 , . . . , y i − 1 , x ) P(y₁, y₂, ..., yₜ|x) = ∏ᵢ P(yᵢ|y₁, y₂, ..., yᵢ₋₁, x) P(y1,y2,...,yt∣x)=i∏P(yi∣y1,y2,...,yi−1,x)
其中:
- x 是输入序列
- y₁, y₂, …, yₜ 是输出序列
- P ( y i ∣ y 1 , y 2 , . . . , y i − 1 , x ) P(yᵢ|y₁, y₂, ..., yᵢ₋₁, x) P(yi∣y1,y2,...,yi−1,x) 是在给定前面所有词的条件下,生成当前词的概率
5. 关键实现细节
- 概率计算:
- 使用对数概率避免数值下溢
- l o g P ( y 1 , y 2 , . . . , y t ∣ x ) = ∑ i l o g P ( y i ∣ y 1 , y 2 , . . . , y i − 1 , x ) log P(y₁, y₂, ..., yₜ|x) = ∑ᵢ log P(yᵢ|y₁, y₂, ..., yᵢ₋₁, x) logP(y1,y2,...,yt∣x)=∑ilogP(yi∣y1,y2,...,yi−1,x)
- 长度惩罚:
- 添加长度惩罚项防止偏好过短序列
- s c o r e = l o g P ( y ∣ x ) / ∣ y ∣ α score = log P(y|x) / |y|^α score=logP(y∣x)/∣y∣α
- α 通常设置为 0.6-0.7
- 终止条件:
- 达到最大长度
- 生成结束标记
- 所有候选序列都完成生成
6. Beam Search 的优化技巧
优化方向
- 自适应束宽:
- 根据生成过程动态调整 k 值
- 在关键决策点使用更大的束宽
- 多样性促进:
- 引入多样性惩罚项
- 避免生成过于相似的候选序列
- 批处理优化:
- 并行处理多个候选序列
- 利用GPU加速计算
前沿Beam Search优化文献
A. 自适应束宽优化
- Dynamic Beam Allocation
- 论文:“Fast Beam Search Decoding with Dynamic Beam Allocation” (COLING 2020)
- 核心思想:动态分配计算资源,根据搜索过程中的不确定性调整束宽
- Speculative Beam Search
- 论文:“Speculative Beam Search for Simultaneous Translation” (EMNLP 2019)
- 优化方法:通过预测性搜索减少延迟
B. 多样性优化
- Diverse Beam Search
- 论文:“Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models”
- 创新点:引入组间多样性惩罚项,促进多样化生成
- Clustered Beam Search
- 论文:“Cluster-based beam search for pointer-generator chatbot grounded by knowledge” (EMNLP 2020)
- 优化方法:通过聚类方法提高搜索效率和多样性
C. 计算效率优化
- Fast Beam Search
- 论文:“Fast Lexically Constrained Decoding with Dynamic Beam Allocation” (EMNLP 2018)
- 核心优化:改进词汇约束解码效率
- Memory-Efficient Beam Search
- 论文:“Beam-search SIEVE for low-memory speech recognition” (EMNLP 2020)
- 优化重点:
- 离线识别语音的能力消除了隐私问题和对互联网连接的需求。尽管努力降低语音识别系统的内存需求,但这些需求仍然巨大,因此Kaldi等流行工具最好通过云计算运行。关键瓶颈来自这样一个事实,即维特比算法是此类工具的基石,它需要的内存即使在通过波束搜索包含的情况下也会随着话语长度线性增长。最近对维特比算法SIEVE的重新设计消除了空间复杂性中的路径长度因素,但实际运行时开销很大。本文中,我们开发了一种SIEVE变体,通过波束搜索减少了这种运行时开销,保留了标准波束搜索的解码质量,并放弃了其线性增长的内存瓶颈。这种空间复杂度的降低与解码质量正交,并与模型表示和训练中的内存节省相辅相成。
D. 贪心搜索优化
- Guided Greedy Search
- 论文:“Guiding Neural Machine Translation with Retrieved Translation Pieces” (NAACL 2018)
- 创新点:利用检索到的翻译片段指导解码
- 摘要:
- 神经机器翻译(NMT)的难点之一是低频词或短语的记忆和适当翻译。本文提出了一种简单、快速、有效的方法,用于回忆以前看到的翻译示例并将其整合到NMT解码过程中。具体来说,对于输入句子,我们使用搜索引擎检索源边与输入句子相似的句子对,然后收集检索到的目标句子中与源句子中匹配的单词对齐的-语法,我们称之为“翻译片段”。我们根据输入句子和检索到的源句子之间的相似性计算每个检索到的句子的伪概率,并使用这些概率对检索到的翻译片段进行加权。最后,使用现有的NMT模型来翻译输入句子,并为包含收集到的翻译片段的输出提供额外的奖励。我们展示了我们的方法在三个窄域翻译任务中将NMT翻译结果提高了6个BLEU点,其中目标句子的重复性尤为突出。它也几乎不会增加翻译时间,并且在准确性、速度和实现简单性方面与另一种基于检索的替代方法相比具有优势。
- Look-ahead Search
- 论文:“Look-ahead Attention for Generation in Neural Machine Translation” (EMNLP 2019)
- 优化方法:通过前瞻机制改进生成质量
- 摘要:
- 注意力模型已经成为神经机器翻译(NMT)的标准组件,它通过在预测每个目标词时选择性地关注源句的部分来指导翻译过程。然而,我们发现目标词的生成不仅依赖于源句,而且在很大程度上依赖于之前生成的目标词,尤其是难以使用递归神经网络建模的远距离词。为了解决这个问题,本文提出了一种新的前瞻性注意生成机制,旨在直接捕捉目标词之间的依赖关系。我们进一步设计了三种模式,将我们的前瞻性注意力整合到传统的注意力模型中。在NIST中文到英文和WMT英文到德文翻译任务上的实验表明,我们提出的前瞻性注意力机制比最先进的基线有了实质性的改进。
E. 混合策略优化
- Adaptive Search Strategy
- 论文:“Adaptive Multi-pass Decoder for Neural Machine Translation” (EMNLP 2019)
- 创新点:根据输入特征动态选择解码策略
- Hybrid Search
- 论文:A Novel Hybrid Approach to Improve Neural Machine Translation Decoding using Phrase-Based Statistical Machine Translation (ACL 2020)
- 优化方法:结合多种解码策略的优势
- 低延迟要求场景:
- Speculative Beam Search
- Fast Beam Search
- 优化的贪心搜索
- 高质量要求场景:
- Diverse Beam Search
- Clustered Beam Search
- Hybrid Search
- 资源受限场景:
- Memory-Efficient Beam Search
- Dynamic Beam Allocation
- Look-ahead Search
不同Beam-Search方法性能综合对比
| 方法 | BLEU↑ | 延迟(ms)↓ | 内存使用↓ | 多样性↑ | 实现复杂度 | 主要优势 | 主要限制 |
|---|---|---|---|---|---|---|---|
| 标准Beam Search (baseline) | 27.3 | 450 | 100% | 低 | 低 | 稳定性好 | 计算开销大 |
| Dynamic Beam Allocation | 27.5 | 380 | 85% | 中 | 中 | 速度提升15% | 参数调优难 |
| Speculative Beam Search | 26.8 | 220 | 90% | 低 | 高 | 延迟降低51% | 质量略降 |
| Diverse Beam Search | 26.9 | 480 | 110% | 高 | 中 | 多样性提升40% | 计算开销增加 |
| Clustered Beam Search | 27.1 | 420 | 95% | 高 | 高 | 多样性与效率平衡 | 实现复杂 |
| Fast Beam Search | 27.0 | 280 | 80% | 低 | 中 | 速度提升38% | 受词表限制 |
| Memory-Efficient Beam Search | 27.2 | 460 | 60% | 低 | 中 | 内存减少40% | 速度略降 |
| Guided Greedy Search | 26.5 | 180 | 40% | 低 | 低 | 速度最快 | 质量不稳定 |
| Look-ahead Search | 27.0 | 320 | 70% | 中 | 中 | 质量与速度平衡 | 参数敏感 |
| Adaptive Search | 27.6 | 400 | 90% | 中 | 高 | 综合性能最佳 | 训练复杂 |
| Hybrid Search | 27.4 | 380 | 95% | 高 | 高 | 灵活性强 | 配置复杂 |
注:
- BLEU:机器翻译质量评分(越高越好)
- 延迟:平均解码时间(越低越好)
- 内存使用:相对于标准Beam Search的内存占用比例
- 多样性:生成结果的多样性程度
- 实现复杂度:方法实现的难易程度
A. 质量与速度权衡
# 性能提升百分比计算
performance_gains = {
'quality_improvement': {
'Adaptive_Search': '+1.1%',
'Dynamic_Beam': '+0.7%',
'Hybrid_Search': '+0.4%'
},
'speed_improvement': {
'Speculative_Beam': '+51%',
'Fast_Beam': '+38%',
'Guided_Greedy': '+60%'
}
}
B. 资源消耗对比
| 方法 | CPU使用率 | GPU内存 | 磁盘IO | 并行度 |
|---|---|---|---|---|
| Memory-Efficient | 中 | 低 | 低 | 高 |
| Fast Beam | 高 | 中 | 低 | 中 |
| Hybrid | 高 | 高 | 中 | 高 |
C. 应用场景适配性
| 场景 | 最佳方法 | 次佳方法 | 原因 |
|---|---|---|---|
| 实时翻译 | Speculative Beam | Fast Beam | 低延迟 |
| 离线翻译 | Adaptive Search | Hybrid Search | 高质量 |
| 移动设备 | Memory-Efficient | Guided Greedy | 低资源消耗 |
| 创意生成 | Diverse Beam | Clustered Beam | 高多样性 |
D. 关键发现
- 效率与质量平衡
- Adaptive Search 在保持质量的同时实现了11%的速度提升
- Memory-Efficient 方法在相似质量下显著减少了内存使用
- 多样性与计算开销
- Diverse Beam Search 的多样性提升显著,但带来20%计算开销
- Clustered Beam Search 在多样性和效率间取得较好平衡
- 实现复杂度与性能收益
complexity_benefit_ratio = {
'Adaptive_Search': 1.2, # 高收益/高复杂度
'Fast_Beam': 1.5, # 高收益/中复杂度
'Memory_Efficient': 1.8 # 高收益/低复杂度
}
7. 应用场景
Beam Search 在多个领域都有广泛应用 What is Beam Search? Explaining The Beam Search Algorithm
- 机器翻译:
- 生成流畅的目标语言句子
- 平衡准确性和流畅性
- 语音识别:
- 从声学特征序列生成文本
- 处理发音歧义
- 文本摘要:
- 生成连贯的摘要文本
- 保持关键信息完整
- 图像描述生成:
- 根据图像特征生成描述性文本
- 确保描述的准确性和自然性
Beam Search、贪心搜索、穷举搜索的详细比较
1. 算法基本特征对比
| 特征 | 贪心搜索 (Greedy Search) | Beam Search | 穷举搜索 (Exhaustive Search) |
|---|---|---|---|
| 策略 | 每步选择最优 | 每步保留k个最优 | 遍历所有可能 |
| 最优性 | 局部最优 | 近似最优 | 全局最优 |
| 完备性 | 否 | 否 | 是 |
| 实用性 | 高 | 高 | 低 |
2. 复杂度分析
2.1 时间复杂度分析
假设:
- V: 词表大小
- T: 最大序列长度
- k: beam width(束宽)
贪心搜索
时间复杂度: O(T × V)
分析:
- 每个时间步需要在词表中选择最大值:O(V)
- 总共T个时间步
- 总复杂度:O(T × V)
Beam Search
时间复杂度: O(T × k × V)
分析:
- 每个时间步:
- 需要为k个候选序列各自预测下一个词:O(k)
- 每个预测需要在词表中计算概率:O(V)
- 从k×V个候选中选择top-k:O(log(k×V))
- 总共T个时间步
- 总复杂度:O(T × k × V × log(k×V))
穷举搜索
时间复杂度: O(V^T)
分析:
- 每个位置有V个可能的选择
- 序列长度为T
- 总共需要遍历V^T种可能
2.2 空间复杂度分析
贪心搜索
空间复杂度: O(T)
分析:
- 只需存储一个当前最优序列
- 序列最大长度为T
Beam Search
空间复杂度: O(k × T)
分析:
- 需要存储k个候选序列
- 每个序列最大长度为T
- 还需要存储中间状态和分数:O(k) 【就是在中间步骤中,被你舍弃的那些路径和概率值】
穷举搜索
空间复杂度: O(V^T)
分析:
- 需要存储所有可能的序列
- 使用回溯可以优化到O(T),但时间复杂度不变
2.3 性能与质量权衡
贪心搜索
优点:
- 计算速度最快
- 内存占用最小
- 实现简单
缺点:
- 容易陷入局部最优
- 生成质量不稳定
- 不考虑上下文的全局关系
Beam Search
优点:
- 计算成本可控
- 结果质量较好
- 可通过调整束宽平衡效率和质量
缺点:
- 计算成本比贪心搜索高
- 内存占用较大
- 实现相对复杂
穷举搜索
优点:
- 保证找到全局最优解
- 结果质量最好
缺点:
- 计算成本极高
- 在实际应用中不可行
- 内存需求巨大
4. 实现复杂度比较
4.1 核心代码复杂度
# 1. 贪心搜索实现
def greedy_search(model, input_ids):
"""贪心搜索算法实现
Args:
model: 神经网络模型,用于生成下一个token的概率分布
input_ids: torch.Tensor, 输入序列的token ids, shape=[batch_size, seq_len]
Returns:
torch.Tensor: 生成的完整序列
"""
# 初始化当前序列为输入序列
current_ids = input_ids
# 持续生成,直到达到结束条件(如遇到生成结束符<end>或达到最大长度)
while not end_condition:
# 使用模型预测下一个token的概率分布
# logits shape: [batch_size, seq_len, vocab_size]
logits = model(current_ids)
# 选择最后一个时间步的概率分布,并取概率最大的token
# [:, -1, :] 选择最后一个时间步
# dim=-1 在词表维度上取最大值
next_token = torch.argmax(logits[:, -1, :], dim=-1) # shape: [batch_size]
# 将新token添加到当前序列中
# unsqueeze(-1)将token扩展一个维度,以便拼接
# dim=-1 在序列长度维度上拼接
current_ids = torch.cat([current_ids, next_token.unsqueeze(-1)], dim=-1)
# shape=[batch_size, seq_len + 1]
return current_ids
# 2. Beam Search实现(简化版)
def beam_search(model, input_ids, beam_width):
"""束搜索算法实现
Args:
model: 神经网络模型
input_ids: torch.Tensor, 输入序列
beam_width: int, 束宽,即每步保留的候选数量
Returns:
torch.Tensor: 得分最高的生成序列
"""
# 初始化候选序列列表,每个元素是 (序列, 累积得分) 的元组
sequences = [(input_ids, 0)]
# 持续生成直到结束条件满足
while not end_condition:
# 存储当前步骤的所有候选序列
candidates = []
# 对每个当前的候选序列进行扩展
for seq, score in sequences:
# 使用模型预测下一个token的概率分布
logits = model(seq)
# 将logits转换为概率分布
probs = torch.softmax(logits[:, -1, :], dim=-1) # shape = [batch_size, vocab_size]
# 选择概率最高的k个token
# top_k_probs: shape=[batch_size, beam_width] -> 每一个样本对应K个候选项
# top_k_ids: shape=[batch_size, beam_width]
top_k_probs, top_k_ids = torch.topk(probs, beam_width)
# 对每个候选token构建新的候选序列
for prob, token_id in zip(top_k_probs, top_k_ids):
# 构建新序列 cat([batch_size, seq_len], [batch_size, seq_len], dim=-1)
new_seq = torch.cat([seq, token_id.unsqueeze(-1)], dim=-1)
# 计算新序列的累积得分(对数概率和)
new_score = score + torch.log(prob)
candidates.append((new_seq, new_score))
# 选择得分最高的beam_width个候选作为新的候选集
sequences = sorted(candidates, key=lambda x: x[1], reverse=True)[:beam_width]
# 返回得分最高的序列
return sequences[0][0]
# 3. 穷举搜索实现(简化版)
def exhaustive_search(model, input_ids, max_length):
"""穷举搜索算法实现
Args:
model: 神经网络模型
input_ids: torch.Tensor, 输入序列
max_length: int, 生成序列的最大长度
Returns:
torch.Tensor: 得分最高的序列
"""
def recursive_search(current_ids):
"""递归搜索所有可能的序列
Args:
current_ids: torch.Tensor, 当前序列
Returns:
list: 所有可能序列及其得分的列表
"""
# 基础情况:达到最大长度时返回当前序列及其得分
if len(current_ids) == max_length:
return [(current_ids, compute_score(current_ids))]
# 存储所有可能的序列
results = []
# 预测下一个token的概率分布
logits = model(current_ids)
# 对词表中的每个token都尝试扩展
for token_id in range(vocab_size):
# 构建新序列
next_ids = torch.cat([current_ids, token_id.unsqueeze(-1)], dim=-1)
# 递归搜索
results.extend(recursive_search(next_ids))
return results
# 开始递归搜索并返回得分最高的序列
return max(recursive_search(input_ids), key=lambda x: x[1])[0]
Beam Search 为什么偏好短序列
1. 为什么会偏好短序列?
这是由于序列概率的计算方式导致的。在生成序列时,我们计算的是条件概率的乘积:
P ( y 1 , y 2 , . . . , y t ∣ x ) = P ( y 1 ∣ x ) × P ( y 2 ∣ y 1 , x ) × . . . × P ( y t ∣ y 1 , . . . , y t − 1 , x ) P(y₁, y₂, ..., yₜ|x) = P(y₁|x) × P(y₂|y₁,x) × ... × P(yₜ|y₁,...,yₜ₋₁,x) P(y1,y2,...,yt∣x)=P(y1∣x)×P(y2∣y1,x)×...×P(yt∣y1,...,yt−1,x)
为了避免数值下溢,我们通常使用对数概率:
l o g P ( y 1 , y 2 , . . . , y t ∣ x ) = l o g P ( y 1 ∣ x ) + l o g P ( y 2 ∣ y 1 , x ) + . . . + l o g P ( y t ∣ y 1 , . . . , y t − 1 , x ) log P(y₁, y₂, ..., yₜ|x) = log P(y₁|x) + log P(y₂|y₁,x) + ... + log P(yₜ|y₁,...,yₜ₋₁,x) logP(y1,y2,...,yt∣x)=logP(y1∣x)+logP(y2∣y1,x)+...+logP(yt∣y1,...,yt−1,x)
问题所在:
- 由于每个条件概率 P(yᵢ|…) ≤ 1,因此 log P(yᵢ|…) ≤ 0
- 序列越长,需要乘的概率项越多(或在对数域中相加的负数越多)
- 这导致长序列的总分数必然比短序列低
让我们看一个具体例子:
# 假设每个词的条件概率都是0.8
single_prob = 0.8
log_prob = np.log(single_prob) # ≈ -0.223
# 不同长度序列的总分数
length_3 = 3 * log_prob # ≈ -0.669
length_5 = 5 * log_prob # ≈ -1.115
length_10 = 10 * log_prob # ≈ -2.230
可以看到,即使每个词的生成概率都相同(0.8是一个相当高的概率),长序列的总分数也会显著低于短序列。
2. 长度惩罚如何解决这个问题?
长度惩罚通过引入一个归一化因子来平衡这种偏差:
s c o r e = l o g P ( y ∣ x ) / ∣ y ∣ α score = log P(y|x) / |y|^α score=logP(y∣x)/∣y∣α
其中:
- |y| 是序列长度
- α 是长度惩罚系数(通常是0.6-0.7)
让我们分析为什么这个公式有效:
- 当 α = 1 时:
- 相当于直接除以序列长度
- 得到的是平均对数概率
- 这可能过度补偿了长度影响
# 不同长度序列的总分数
length_3 = 3 * log_prob /3 # ≈ -0.223
length_5 = 5 * log_prob /5 # ≈ -0.223
length_10 = 10 * log_prob /10 # ≈ -0.223
- 当 α = 0 时:
- 相当于不做任何长度惩罚
- 会偏好短序列
length_3 = 3 * log_prob # ≈ -0.669
length_5 = 5 * log_prob # ≈ -1.115
length_10 = 10 * log_prob # ≈ -2.230
- 当 α ≈ 0.6-0.7 时:
- 提供了一个适度的补偿
- 既不会过度偏好长序列,也不会过度偏好短序列
length_3 = 3 * log_prob / 3^0.6 # ≈ -0.346
length_5 = 5 * log_prob / 5^0.6 # ≈ -0.425
length_10 = 10 * log_prob / 10^0.6 # ≈ -0.058
可以看出:
- α = 0:完全不惩罚,短序列得分明显更高
- α = 1:过度惩罚,所有序列得分相同(因为是完全平均)
- α = 0.6:提供适度惩罚,得分差异更合理
3. 为什么选择0.6-0.7作为α值?
这个范围是经验值,来自于大量实验:
- 实证研究:
- Google的神经机器翻译(GNMT)论文中首次提出
- 在多个任务上进行了广泛实验
- 平衡考虑:
- 在此范围内,模型既能生成足够长的序列
- 又不会产生冗余或无意义的内容
- 任务相关:
- 具体值可以根据任务调整
- 翻译任务通常用0.6
- 摘要任务可能需要稍大的值(如0.7)
参考资料
- https://www.baeldung.com/cs/beam-search
- https://www.width.ai/post/what-is-beam-search
- https://telnyx.com/learn-ai/beam-search-algorithm


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









