




1.简介
vLLM是一个专为大规模语言模型(LLMs)设计的高效推理和服务框架,旨在优化模型的推理速度、吞吐量和内存利用率。它由加州大学伯克利分校的研究团队开发,特别适合在生产环境中部署大模型(如GPT、LLaMA等)。以下是其核心特点和优势:
1.1核心技术:PagedAttention
●内存管理优化:vLLM的核心创新是PagedAttention(类似操作系统的内存分页机制),通过将注意力机制中的键值(Key-Value)缓存分割为固定大小的“块”,按需分配和管理。这显著减少了内存碎片化问题,尤其适合处理长文本或高并发请求。
●内存效率提升:相比传统框架(如Hugging Face Transformers),vLLM可降低4倍以上的内存占用,同时支持更高的并发请求量。
1.2核心优势
●高吞吐量:通过连续批处理(Continuous Batching)和动态调度,并行处理多个请求,最大化GPU利用率。
●低延迟:优化内存访问和计算效率,减少单次推理的响应时间。
●易用性:兼容HuggingFace模型格式,仅需少量代码修改即可部署现有模型。
●可扩展性:支持分布式推理和多 GPU 扩展,适应超大规模模型部署。
1.3典型应用场景
●大模型 API 服务:高并发场景下的推理服务(如ChatGPT类应用)。
●长文本生成:支持长上下文(如文档摘要、代码生成)而无需牺牲速度。
●资源受限环境:在有限GPU内存下部署更大模型或服务更多用户。
●学术研究:快速实验不同模型的推理性能,减少计算成本。
3.安装vLLM
3.1安装GPU版本
●准备环境
| 系统 | CPU | 内存 | 显卡 | 硬盘 |
| Ubuntu 22.04.1 LTS (Jammy Jellyfish) | 14 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz | 90GB | RTX 3090(24GB) * 1 | 80GB |
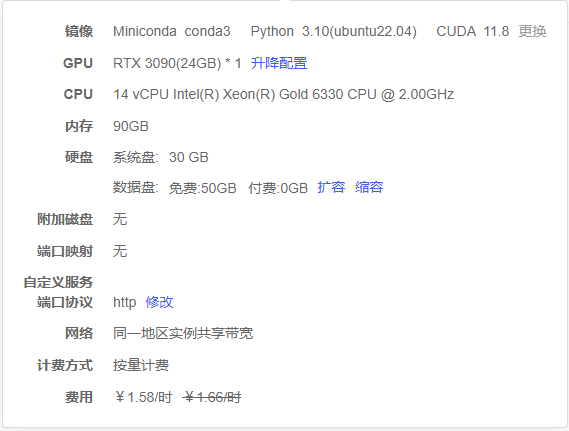
服务器信息如下:
●创建并激活conda虚拟环境
# 创建vllm虚拟环境
conda create -n vllm_env python=3.11 -y
# 激活vllm虚拟环境
conda activate vllm_env
●安装vllm包
# 安装vllm包
pip install vllm
●验证cuda和查看gpu信息
# 查看nvidia信息
nvidia-smi
因为我在autodl上租的服务器,已经安装好显卡驱动与cuda,所以不用手动安装,后面有时间再来学习如何安装显卡驱动与cuda。
●下载模型
从huggingface平台上提前下载好基于deepseek千问模型(deepseek-r1-distill-qwen-1.5b)与嵌入模型(nomic-embed-text-v1.5),路径为:/root/huggingface/models。
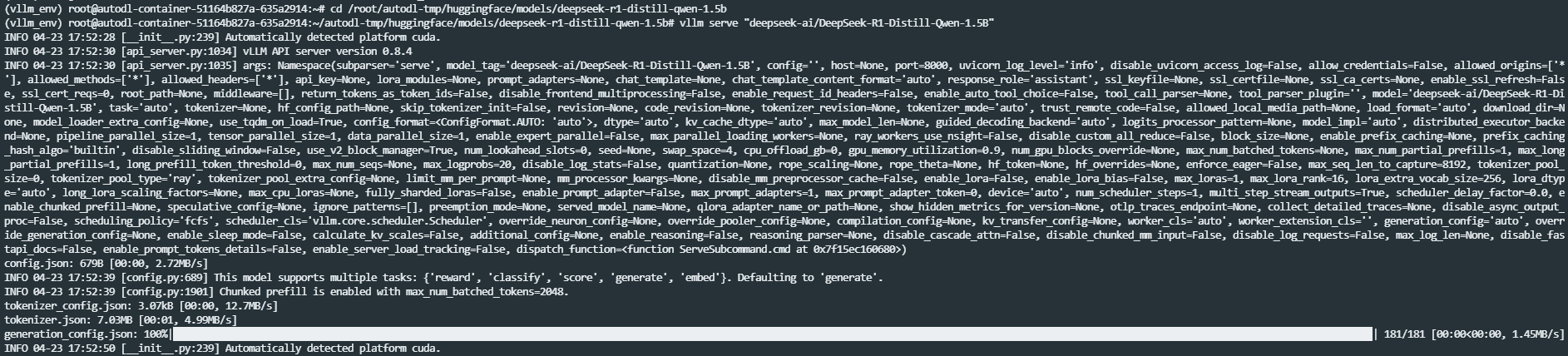
●基于vllm前台启动服务
# 切换到modelscope下载到qwen模型目录下
cd /root/modelscope/models/deepseek-r1-distill-qwen-1.5b
# 启动模型服务
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
如下图所示:
●基于vllm后台启动服务
◎创建vllm后台启动服务目录
# 创建一个vllm后台启动服务目录
mkdir -p /root/vllm-start-bash
◎创建大模型后台启动文件
# 创建一个关于不同大模型后台启动文件
vim /root/vllm-start-bash/vllm-ds-qwen-start.sh
#!/bin/bash
# 切换到modelscope下载到qwen模型目录下
cd /root/modelscope/models/deepseek-r1-distill-qwen-1.5b
# 启动vllm并将其放在后台执行
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --port 8000 &
# 输出后台进程的 PID
echo "vllm server is running in the background with PID $!"
◎授予后台启动文件权限
# 授予后台启动文件权限
chmod +x /root/vllm-start-bash/vllm-ds-qwen-start.sh
◎后台启动服务
# 后台启动服务
/root/vllm-start-bash/vllm-ds-qwen-start.sh
◎查看进程
# 查看进程
ps -ef | grep vllm
4.客户端调用
●vLLM可以部署为实现OpenAI API协议的服务器形式暴露出对外REST API接口,比如Chat Completions API交互:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
●代码实现
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
]
)
print("Chat response:", chat_response)
5.本地VSCode如何对远程服务器代码进行调试与开发
●安装Remote-SSH插件
点击VSCode左侧的扩展按钮(或按Ctrl+Shift+X),搜索插件Remote - SSH进行安装:
●打开并设置Remote-SSH配置文件
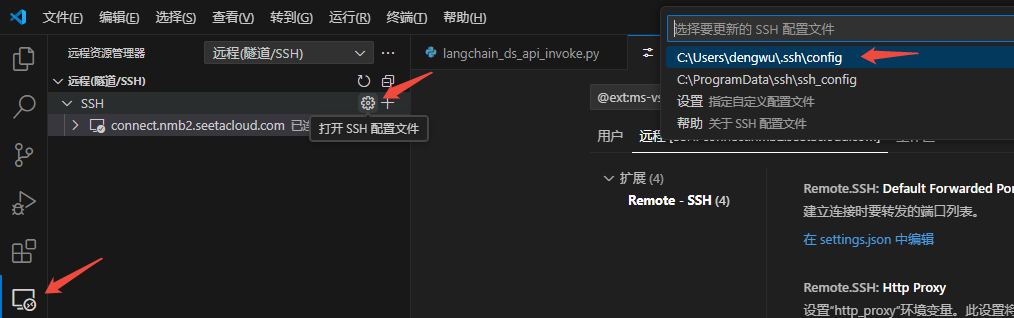
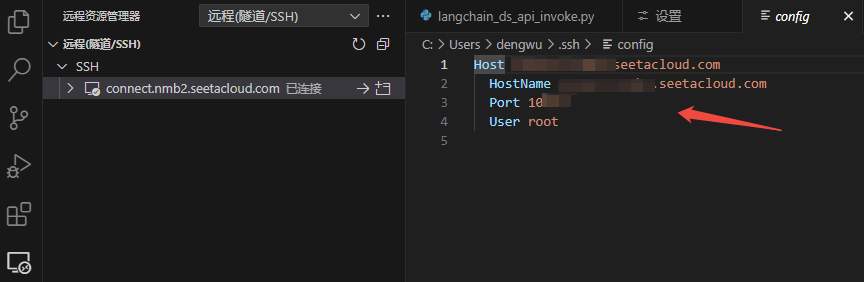
HostName是远程服务器的 IP 地址,Port是远程服务器端口,User是用于登录的用户名称。
参考文献
vllm_quickstart:https://docs.vllm.ai/en/stable/getting_started/quickstart.html



















 3434
3434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









