




摘要
Modern hierarchical vision transformers(ViT)模型在追求监督分类性能过程中加入的多个视觉特定组件。尽管这些组件提高了分类准确性并使计算复杂度(FLOP)看起来更具吸引力,但它们实际上使得这些模型的速度比标准ViT模型更慢。本文作者认为,这些额外的复杂性是没有必要的。
作者提出,通过在强大的视觉预训练任务(如MAE,Masked Autoencoders)上进行预训练,可以去除这些多余的组件,而不会损失模型的准确性。这个过程中,
创建了一个名为Hiera的极简层次化视觉Transformer模型。Hiera不仅比之前的模型更准确,而且在推理和训练过程中速度显著更快。
introduction
视觉变换器 (ViT) 主导了计算机视觉领域的多项任务。 虽然架构简单,但它们的准确性(Touvron 等人,2022)和扩展能力(Zhai 等人,2021)使它们今天仍然是一个流行的选择。 此外,它们的简单性使得可以使用强大的预训练策略,例如 MAE(He et al., 2022),这使得 ViT 在计算和数据上能够高效地进行训练。
然而这种简单性是有代价的:通过在整个网络中使用相同的空间分辨率和通道数量,ViT 无法有效地利用其参数。 这与之前的“分层”或“多尺度”模型形成鲜明对比(例如,Krizhevsky 等人(2012);He 等人(2016)),
在特征较简单的早期阶段,通道数较少,但空间分辨率较高;
在特征较复杂的模型后期,通道数较多,但空间分辨率较低。
已经引入了采用这种分层设计的几种特定领域视觉转换器,例如 Swin(Liu 等人,2021)或 MViT(Fan 等人,2021)。 然而,为了在 ImageNet-1K(ViT 历史上一直苦苦挣扎的领域)上使用完全监督训练来追求最先进的结果,这些模型随着添加专门的模块(例如十字形窗口)而变得越来越复杂。 在 CSWin (Dong et al., 2022) 中,分解了 MViTv2 中的相对位置嵌入 (Li et al., 2022c))。 虽然这些变化产生了具有有吸引力的浮点运算 (FLOP) 计数的有效模型,但在幕后增加的复杂性使这些模型整体速度变慢。
我们认为,其中很多实际上是不必要的。 由于 ViT 在初始修补操作后缺乏归纳偏差,因此后续视觉特定转换器提出的许多更改用于手动添加空间偏差。 但是,如果我们可以训练模型来学习它们,为什么我们要放慢架构来添加这些偏差呢? 特别是,MAE 预训练已被证明是教授 ViT 空间推理的非常有效的工具,允许纯视觉转换器在检测上获得良好的结果(Li 等人,2022b),这是以前由 Swin 或 MViT 等模型主导的任务 。
MAE预训练是稀疏的,并且速度可以是正常监督训练的 4 − 10 倍,这使其成为许多领域中理想的替代方案,而不仅仅是准确性(He et al., 2022;Feichtenhofer et al., 2022;Huang et al., 2022b)。
我们用一个简单的策略来测试这个假设:使用一些实现技巧(图 4),采用现有的分层 ViT(例如 MViTv2),并在使用 MAE 进行训练时小心地删除非必要组件(表 1)。
将 MAE 任务调整到这种新架构后(表 3),我们发现我们实际上可以简化或删除所有非变压器组件,同时提高准确性。 结果是一个非常高效的模型,没有任何附加功能:没有卷积,没有移位或十字形窗口,没有分解的相对位置嵌入。 只是一个纯粹、简单的分层 ViT,它比之前跨多个模型大小、领域和任务的工作更快、更准确。
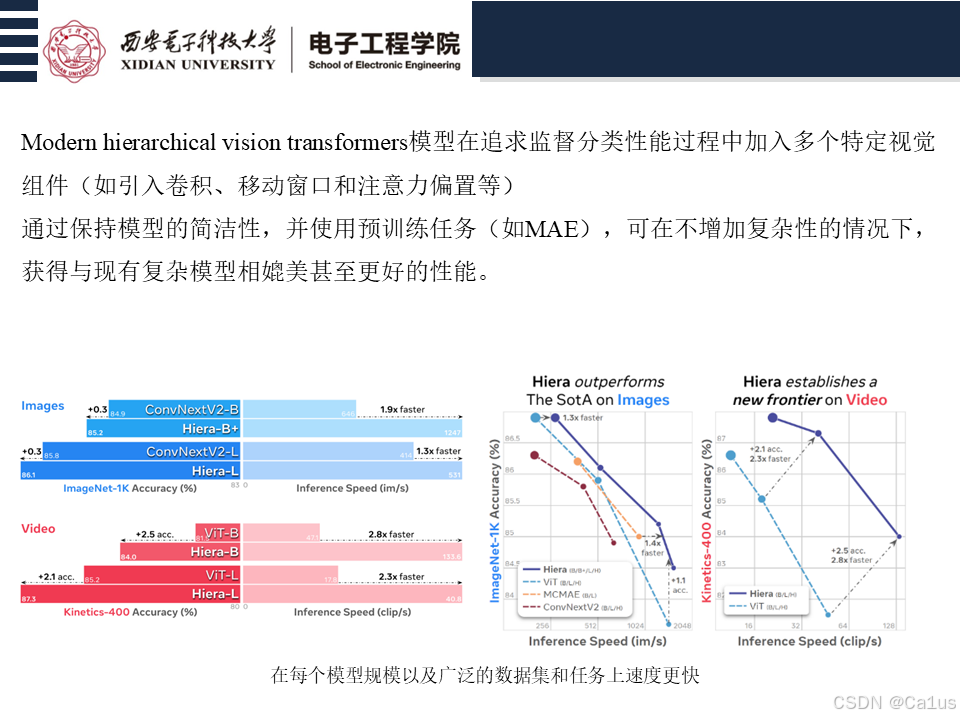
我们的简单分层视觉变换器(Hiera)在图像方面优于 SotA,并远远超过了之前在视频方面的工作,同时在每个模型规模(图 3)以及广泛的数据集和任务(第 5 节、第 6 节)上速度更快(图 1) )。
普通 ViT(Dosovitskiy 等人,2021)与之前的卷积神经网络(CNN)(LeCun 等人,1998)之间的主要区别:ViT 将图像划分为(例如)16×16 像素、不重叠的块并展平将空间网格转换为一维序列,而 CNN 在模型的多个阶段维护该网格,降低每个阶段的分辨率并引入归纳偏差,例如平移等方差。
最近,该领域对混合方法表现出了越来越大的兴趣(Fan et al., 2021; Liu et al., 2021; Li et al., 2022c; Dong et al., 2022; Wang et al., 2021),该方法结合了 具有类似卷积运算的 Transformer 和先前 CNN 的分层阶段结构。 这个方向已经取得了成功,并在各种视觉任务上取得了最先进的成果。 然而,在实践中,这些模型实际上比普通的 ViT 模型慢,并且卷积模型不容易与流行的自监督任务(例如蒙版图像建模)兼容。 我们在创建 Hiera 时解决了这两个问题。
3. Approach
目标:创建一个强大且高效的多尺度视觉转换器,最重要的是,它很简单。
我们认为我们不需要任何专门的模块,例如卷积(Fan et al., 2021)、移位窗口(Liu et al., 2021)或注意偏差(Graham et al., 2021;Li et al., 2022c) 以获得视觉任务的高精度。
这可能看起来很困难,因为这些技术增加了普通 Transformer(Dosovitskiy 等人,2021)所缺乏的非常需要的空间(和时间)偏差。 然而我们采用了不同的策略。 虽然之前的工作通过复杂的架构变化增加了空间偏差,但我们选择保持模型简单,并通过强大的借口任务来学习这些偏差。 为了展示这个想法的有效性,我们设计了一个简单的实验:采用现有的分层视觉变换器,并在使用强大的借口任务进行训练时消除其花哨的功能。
目标:创建一个既强大又高效的多尺度视觉Transformer模型,并且要保持模型的简洁性。作者认为,不需要像卷积(Convolution)、移动窗口(Shifted Windows)或注意力偏置(Attention Bias)等专门模块,就能够在视觉任务上取得高精度。虽然这些技术通过引入空间(和时间)偏置来弥补标准Transformer缺乏的位置敏感性,但作者采用了不同的策略。与前人的做法通过复杂的架构修改来引入空间偏置不同,作者选择通过强大的预训练任务来学习这些偏置,从而保持模型的简洁性。
为了验证这一想法,作者设计了一个简单的实验:他们将一个现有的层次化视觉Transformer模型进行删减,去掉其中的复杂组件,并在强大的预训练任务(即Masked Autoencoders,MAE)上进行训练。MAE任务通过让模型重建被遮挡的输入补丁,已被证明有效地帮助Transformer学习下游任务(如目标检测)的定位能力。需要注意的是,MAE的预训练是稀疏的,即遮挡的tokens被删除,而不是像其他遮挡图像建模方法那样被覆盖。
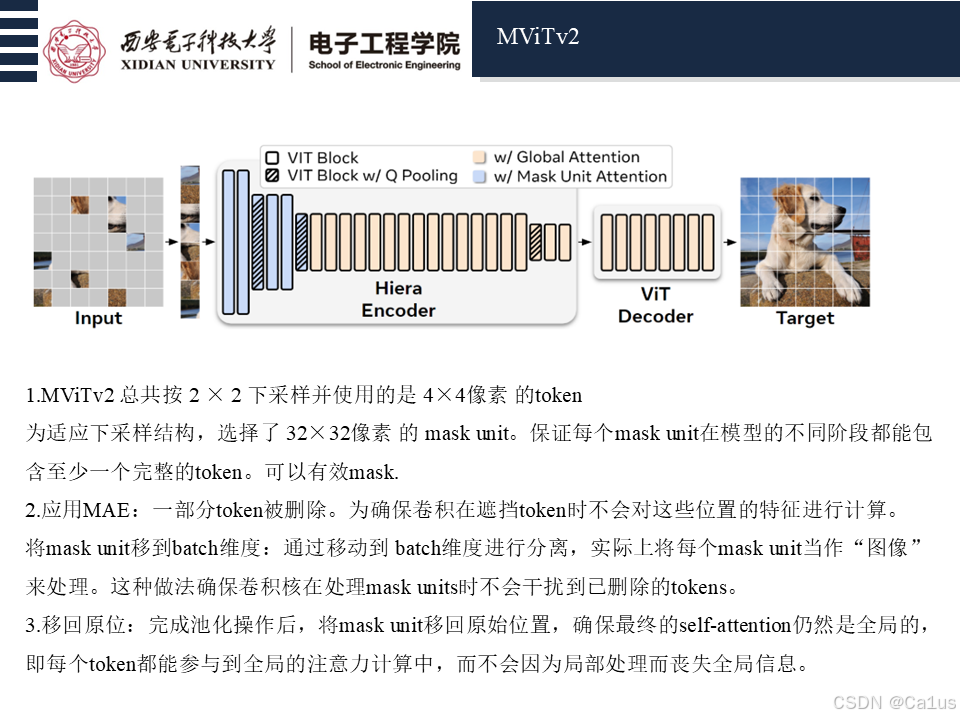
然而,MAE的稀疏性对现有的层次化模型构成了挑战,因为这会打破它们依赖的2D网格结构。此外,MAE通常会遮挡较大的16×16的补丁,而大多数层次化模型则使用更小的4×4补丁。为了解决这些问题,作者提出了“mask unit”(遮挡单元)与“token”(标记)之间的区分。在作者的方法中,mask unit是MAE遮挡的区域的分辨率,而token是模型内部的分辨率。具体来说,他们遮挡的是32×32像素区域,因此mask unit对应的是8×8的token。通过这种方式,作者能够巧妙地处理层次化模型,保持模型的结构完整,同时使用MAE进行训练。
总的来说,作者通过这种方法能够在不引入复杂架构修改的情况下,利用MAE预训练,测试和评估层次化视觉Transformer模型的效果。
3.1. 准备 MViTv2
我们选择 MViTv2 作为我们的基础架构,因为它的小 3 × 3 内核受图 4d 中描述的分离与填充技巧的影响最小,尽管我们可能选择不同的变压器并获得类似的最终结果。 下面我们简要回顾一下 MViTv2。

MViTv2(Li et al., 2022c)是一个分层模型。 也就是说,它在四个阶段学习多尺度表示。 它首先对具有小通道容量但高空间分辨率的低级特征进行建模,然后在每个阶段用通道容量换取空间分辨率,以在更深的层中建模更复杂的高级特征。 MViTv2 的一个关键特征是池化注意力(图 5a),其中在计算自注意力之前,通常使用 3 × 3 卷积在本地聚合特征。 在池化注意力中,K和V被池化以减少前两个阶段的计算量,而Q被池化以通过降低空间分辨率从一个阶段过渡到下一个阶段。 MViTv2 还具有分解的相对位置嵌入(而不是绝对位置嵌入)和残差池连接,用于在注意力块内的池化 Q 标记之间跳过。 请注意,默认情况下,即使不需要下采样,MViTv2 中的池化注意力也包含步幅为 1 的卷积。
应用MAE。 由于 MViTv2 总共按 2 × 2 下采样了 3 次(图 2),并且由于它使用 4 × 4 像素的标记大小,因此我们采用大小为 32 × 32 的掩模单元。这确保每个掩模单元对应于 82 、 42、22、12 个令牌分别位于第 1、2、3、4 阶段,允许每个掩码单元在每个阶段覆盖至少一个不同的令牌。 然后如图 4d 所示,为了确保卷积核不会渗透到已删除的标记中,我们将掩码单元转移到批量维度以将它们分开以进行池化(有效地将每个掩码单元视为“图像”),然后撤消 之后进行转移以确保自我注意力仍然是全局的。
简化 MViTv2
在本节中,我们在使用 MAE 进行训练时删除了 MViTv2 的非必要组件。 在选项卡中。 1,我们发现我们可以删除或以其他方式简化所有这些,并且仍然保持 ImageNet-1K 上图像分类的高精度。 我们使用 MViTv2-L 来确保我们的变更大规模发挥作用。
相对位置嵌入。
MViTv2 将 Dosovitskiy 等人(2021 年)的绝对位置嵌入换成了更强大的相对位置嵌入,并在每个区块中加入注意力。从技术上讲,我们可以实现与稀疏预训练兼容的版本,但这样做会增加很多复杂性。相反,我们选择在这里开始研究,取消这一改动,改用绝对位置嵌入。如表 1a 所示 1a 中所示,在使用 MAE 进行训练时,这些相对位置嵌入是不必要的。此外,绝对位置嵌入的速度要快得多。
去除卷积。
接下来,我们要移除模型中的卷积层,因为它们是视觉特定模块,可能会增加不必要的开销。我们首先尝试用 maxpools 替换每个卷积层(Fan 等人(2021 年)的研究表明这是次佳选择),这本身就相当昂贵。结果(表 1b)在图像上的准确率下降了 1%,但这是意料之中的:我们还用 maxpools 替换了所有额外的 stride=1 convs,这对特征的影响非常大(使用填充和小掩码单元,这实际上是对每个特征图执行了一次 relu)。一旦我们删除了这些额外的 stride=1 maxpools(表 1c),我们几乎恢复到了之前的准确度,同时将图像模型的速度提高了 22%,视频模型的速度提高了 27%。此时,只剩下阶段转换时的 Q 池层和前两个阶段的 KV 池层。
消除重叠
其余 maxpool 层的内核大小仍为 3 × 3,因此在训练和推理过程中都必须使用图 4d 中的分离和填充技巧。不过,如图 4e 所示,如果我们不让这些 maxpool 内核重叠,就可以完全避免这个问题。也就是说,如果我们为每个 maxpool 设置的核大小等于 stride,我们就可以使用稀疏 MAE 预训练,而无需使用分离和填充技巧。如表 1d 所示 1d 中所示,这在图像和视频上分别提高了模型速度的 20% 和 12%,同时提高了准确率,这可能是由于无需填充的缘故。
移除注意力残差。
MViTv2 在 Q 和输出之间的注意力层中添加了一个残余连接,以帮助学习汇集注意力。 不过,到目前为止,我们已经尽量减少了层数,使注意力更容易学习。 因此,我们可以放心地删除它(表 1e)。
屏蔽单位注意力。
至此,剩下的唯一专业模块就是汇集注意力了。汇集 Q 对于维持层次模型是必要的,但汇集 KV 只是为了在前两个阶段减少注意力矩阵的大小。我们可以完全取消这一功能,但这会大大增加网络的计算成本。相反,在表 1f 中,我们用一种实现方法取代了它。1f 中,我们用一个实施上微不足道的替代方案取而代之:掩码单元内的局部注意力。在 MAE 预训练过程中,我们已经需要在网络开始时分离出掩码单元(见图 2)。因此,当标记进入注意力时,它们已经被整齐地按单元分组。然后,我们只需在这些单元内执行局部注意即可,无需任何开销。虽然这种 “掩码单元注意力 ”是局部的,而不是像汇集注意力那样是全局的(图 5),但 K 和 V 只在前两个阶段汇集,全局注意力在前两个阶段并不那么有用。因此,如表 1 所示,这一变化对 “掩码单元注意力 ”没有影响。因此,如表 1 所示,这一变化对准确性没有影响,但却大大提高了吞吐量--在视频中提高了 32%。请注意,掩码单元注意力与窗口注意力不同,因为它是根据当前分辨率下掩码单元的大小来调整窗口大小的。窗口注意力在整个网络中的大小是固定的,这会在下采样后泄漏到被删除的标记中(见图 6)。
Hiera。
这些变化的结果是一个极其简单而高效的模型,我们将其命名为 “Hiera”。与我们最初使用的 MViTv2 相比,Hiera 在图像上的处理速度快 2.4 倍,在视频上的处理速度快 5.1 倍,而且由于 MAE 的存在,Hiera 实际上更加准确。此外,由于 Hiera 支持稀疏预训练,因此表 1 中的结果非常快速。1 中的结果非常快速。事实上,要在图像上获得更高的准确度,Hiera-L 的训练速度比有监督的 MViTv2-L 快 3 倍(图 7)。在视频方面,Wei 等人(2022 年)的研究报告显示,使用 MViTv2 的缩减版,前 3 个阶段的 KV 跨度增加一倍,准确率为 80.5%。与该模型相比,我们的 Hiera-L 在 800 个预训练历元中获得了 85.5%,同时训练速度快了 2.1 倍(图 7)。除非另有说明,本文中的所有基准测试都是在使用 fp16 的 A100 上进行的(因为这种设置在实践中最有用)。我们在本节的实验中使用了 Hiera-L,当然我们也可以将其实例化为不同的大小,如表 2 所示。2.
以下是本篇文章用于组会汇报的PPT ,如有错误请谅解:



























 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









