



 本文主要探讨了深度学习中过拟合和欠拟合的概念,以及如何通过网络正则、数据增强、Dropout、EarlyStopping和BatchNormalization等技术来控制过拟合,提升模型的泛化能力。
本文主要探讨了深度学习中过拟合和欠拟合的概念,以及如何通过网络正则、数据增强、Dropout、EarlyStopping和BatchNormalization等技术来控制过拟合,提升模型的泛化能力。
常用深度学习技术
1.1过拟合与欠拟合
机器学习的基本问题是利用模型对数据进行拟合,学习的目的并非是对有限
训练集进行正确预测,而是对未曾出现在训练集合中的样本能够正确预测。模型
对训练集数据的误差称为经验误差,对测试集数据的误差称为泛化误差。模型对
训练集以外样本的预测能力就称为模型的泛化能力,追求这种泛化能力始终是机
器学习的目标。
过拟合和欠拟合是导致模型泛化能力不高的两种常见原因,都是模型学习能
力与数据复杂度之间失配的结果。“欠拟合”常常在模型学习能力较弱,而数据
复杂度较高的情况出现,此时模型由于学习能力不足,无法学习到数据集中的
“一般规律”,因而导致泛化能力弱。与之相反,“过拟合”常常出现在模型学习
能力过强的情况,此时的模型学习能力太强,以至于将训练集单个样本自身的
特点都能捕捉到,并将其认为是“一般规律”,同样这种情况也会导致模型泛化
能力下降。过拟合与欠拟合的区别在于,欠拟合在训练集和测试集上的性能都
较差,而过拟合往往能完美学习训练集数据的性质,而在测试集上的性能较差。
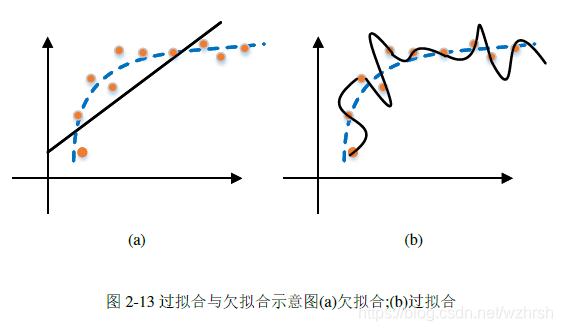
图2-13(a)与图2-13(b)分别展示了对二维数据进行拟合时过拟合与欠拟合的情况。
其中蓝色虚线代表数据的真实分布,橙色圆点为训练数据,黑色实线代表模型的
拟合结果。图2-13(a)使用简单的线性模型拟合,由于模型过于简单,没有能力捕
捉模型的真实分布,产生了欠拟合。图2-13(b)使用了高次多项式模型进行拟合,
由于模型过于复杂,因此对每个测试数据都能精确预测,但模型拟合的结果没有
抓住数据分布的本质特征,出现了过拟合。过拟合和欠拟合是所有机器学习算法
都要考虑的问题,其中欠拟合的情况比较容易克服,往往只要增加模型复杂度即
可。但过拟合却比较难以克服。过拟合广泛存在于机器学习算法中并难以完全消
除,因此本节讨论的主要问题是如何“控制”过拟合的程度,而不是如何“消除”
过拟合。深度学习模型复杂,模型学习能力强,因此过拟合的风险尤为显著,下
面我们将简要介绍深度学习中常用的控制过拟合的技术手段。
1.2 网络正则
一种经典的控制过拟合手段是对网络参数添加正则项。正则项可以看作是对
网络参数的约束或惩罚,它能引导网络的参数朝某个规定的方向进行优化。添加
了正则项后,网络的优化目标由原来的最小化损失函数?(?)变为最小化损失函数
与正则项的和?(?)+?(?)。
常见的正则项有?1范数、?2范数、?1 +?2约束(Elastic Net约束)等。正则
化可以看作一种先验假设,如?1范数对应于参数的拉普拉斯分布假设,?2约束对
应于参数的高斯分布假设。可以看到,在为损失函数增加?(?)约束项后,那些违
背先验假设的参数将会产生较大的惩罚值,因此在优化过程中网络的参数会朝着
先验假设的方向更新。例如,当为网络施加?2约束时,具有较大值的参数经过平
方后会产生一个很大的数值,不利于目标函数的最小化。因此在网络优化的过程
中,参数将避免出现极大或极小的值。参数的值趋向于正态分布时,接近0值的参
数较多,模型的复杂度趋于简单,因此能够达到控制过拟合的目的。
1.3 数据增强
数据增强是深度学习发展过程中提出的一种控制过拟合的方法。如上文所指
出,模型的过拟合是模型学习能力与数据复杂度之间的矛盾,网络正则的方法是
从降低模型复杂度的方面着手,而数据增强则从提升数据复杂度的方向着手。数
据增强多用于图像处理领域,其基本思想是通过噪声、翻转、平移、旋转等方法,
在不改变图片语义信息的前提下增加数据的多样性,从而抵消网络对训练集单个
样本特征的关注度,提高模型泛化能力。
1.4 Dropout
Dropout是一种随机断开神经元的技术,其具体内容前文已有介绍。Dropout控
制过拟合的原理有两点。第一是在神经网络的局部构造集成学习模型,在处理测
试集样本时,网络作出的推断实际上是不同神经元断开时的子网络所做出推断的
平均。集成学习模型,如随机森林,梯度提升树等在控制过拟合上往往效果明显。
第二是减少神经元之间的耦合,由于Dropout每次断开的神经元都不相同,这就阻
止了神经元耦合起来提取同一种特征的可能性,使得网络在缺失一些信息的情况
下仍然能够做出正确推断。
1.5 EarlyStopping
EarlyStopping是一种在训练中使用的回调函数,其基本思想是在训练过程中
监视神经网络在验证集上的性能,当验证集上的性能在连续的多轮训练中没有得
到提高,则提前终止训练。EarlyStopping控制过拟合的原理是控制模型的拟合程
度,在适当时机阻止模型继续学习而达到过拟合状态。当模型在验证集性能没有
提升时,意味着训练集已经不能提供更多的提高模型泛化能力的信息了,若继续
训练下去,模型会开始拟合训练集样本中的自身特点,从而进入过拟合。
1.6 BatchNormalization
BatchNormalization在前文已有介绍。通常而言,BatchNormalization的主要作
用是加速网络的训练。但同时,它也具有一定的控制过拟合的能力。实验验证,
使用BatchNormalization时可以不用或者以较低的断开率使用Dropout,或降低L2正
则的系数。使用BatchNormalization控制过拟合的原理是,过拟合通常发生在数据
边界,而BatchNormalization可以协助将初始化权重调整落入数据的内部,从而协
助控制过拟合。

















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









