




 本文详细介绍了Python中正则表达式的使用,包括值匹配、次数匹配、定位符匹配、贪婪模式与非贪婪模式,以及在接口自动化测试中的应用,如group()方法、re.search等,并强调了在测试用例中#XXX#的值替换技巧。
本文详细介绍了Python中正则表达式的使用,包括值匹配、次数匹配、定位符匹配、贪婪模式与非贪婪模式,以及在接口自动化测试中的应用,如group()方法、re.search等,并强调了在测试用例中#XXX#的值替换技巧。
一、值匹配
1、. 表示匹配任意1个字符(除了\n换行符)默认字符串中第一个
span()表示匹配到的位置;
group()获取匹配到的字符串;
re.search()只找一个,符合的出现了就不再找了
import re
string = 'python337'
data = re.search(pattern=('.'),string=string)
print(data)
print(data.group())
输出
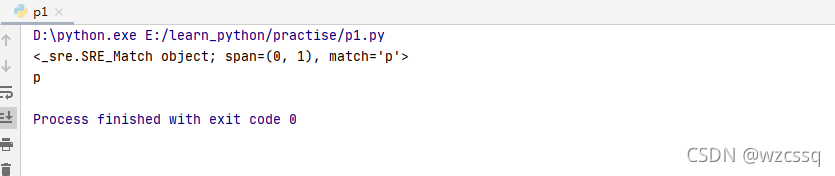
2、[value1,value2]匹配value1、value2中的任意一个
import re
string = 'python337'
data = re.search(pattern=('[yt]'),string=string)
print(data)
print(data.group())
输出
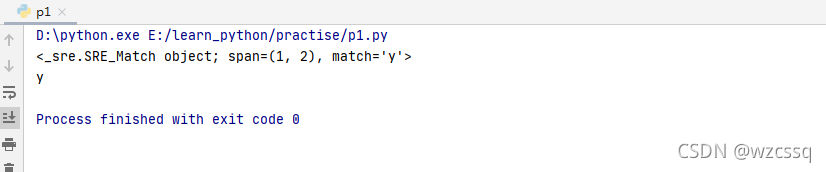
3、\d匹配任意数字0~9
import re
string = 'python337'
data = re.search(pattern=('\d'),string=string)
print(data)
print(data.group())输出
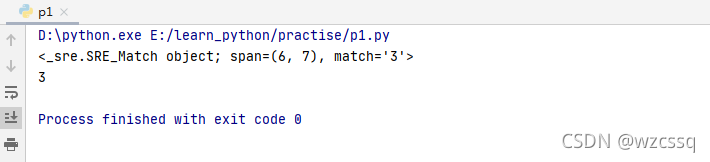
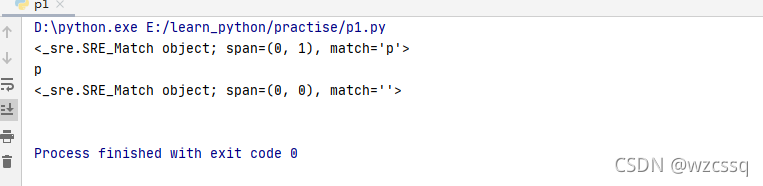
4、其余常用:
\D匹配非数字;
\s匹配空格(相当于tab键,空白);
\S匹配非空格;
\w匹配特殊字符除外的字符(包含大小写字母、数字、下划线_);
\W匹配特殊字符
二、次数匹配
1、* 一个字符出现0次或无限次,若是没有匹配到则是空字符串;匹配连着的
import re
string = 'python337'
data = re.search(pattern=('p*'),string=string)
print(data)
print(data.group())
data = re.search(pattern=('a*'),string=string)
print(data)
print(data.group())输出
2、+ 一个字符出现1次或无限次,至少1次;1以及1以上
import re
string = 'python337'
data = re.search(pattern=('3+'),string=string)
print(data)
print(data.group())输出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









