







 本文深入对比了Spark与Hadoop、MapReduce、Hive和Storm的关系与特点。Spark凭借内存计算优势在速度上超越Hadoop和MapReduce,但在大数据处理时可能面临内存管理问题。Spark SQL虽快于Hive,但无法完全替代Hive的数据仓库功能。Spark Streaming作为准实时计算框架,与Storm相比在实时性和动态调整并行度上有不同优缺点。Spark在大数据体系中占据重要地位。
本文深入对比了Spark与Hadoop、MapReduce、Hive和Storm的关系与特点。Spark凭借内存计算优势在速度上超越Hadoop和MapReduce,但在大数据处理时可能面临内存管理问题。Spark SQL虽快于Hive,但无法完全替代Hive的数据仓库功能。Spark Streaming作为准实时计算框架,与Storm相比在实时性和动态调整并行度上有不同优缺点。Spark在大数据体系中占据重要地位。
学习目录
拿图,转发,请留言,谢谢,支持原创!!!
Spark VS Hadoop
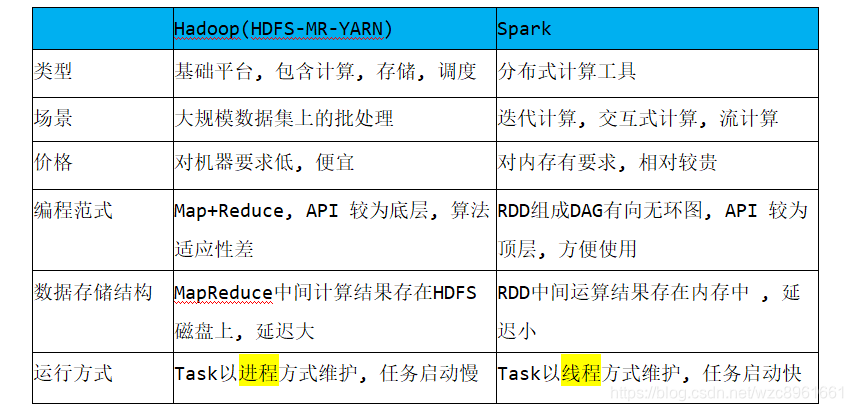
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop,Spark主要用于替代Hadoop中的MapReduce计算模型。存储依然可以使用HDFS,但是中间结果可以存放在内存中;调度可以使用Spark内置的,也可以使用更成熟的调度系统YARN等
实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。
此外,Hadoop可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark对硬件的要求稍高一些,对内存与CPU有一定的要求。
Spark VS MapReduce的计算模型
MapReduce能够完成的各种离线数据批处理功能,以及常见算法(比如二次排序、TopN等),基于Spark RDD的核心编程,都可以实现,并且可以更好地、更容易地实现,而且基于Spark RDD编写的离线批处理程序,运行速度是MapRe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3147
3147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









