



 本文介绍了Spark的诞生背景,大数据系统中的不足以及MapReduce的优缺点。Spark作为MapReduce的替代品,具备速度优势、易用性、通用性和跨平台运行的特点。文章详细阐述了Spark的架构、运行原理,以及核心概念如RDD、转换和行动操作。最后,通过Spark与HBase和Kafka的连接示例,展示了Spark的实践应用。
本文介绍了Spark的诞生背景,大数据系统中的不足以及MapReduce的优缺点。Spark作为MapReduce的替代品,具备速度优势、易用性、通用性和跨平台运行的特点。文章详细阐述了Spark的架构、运行原理,以及核心概念如RDD、转换和行动操作。最后,通过Spark与HBase和Kafka的连接示例,展示了Spark的实践应用。
这篇文章主要写一些spark很基础的东西,如果你是老司机了,请绕道 or 轻喷。
1、背景
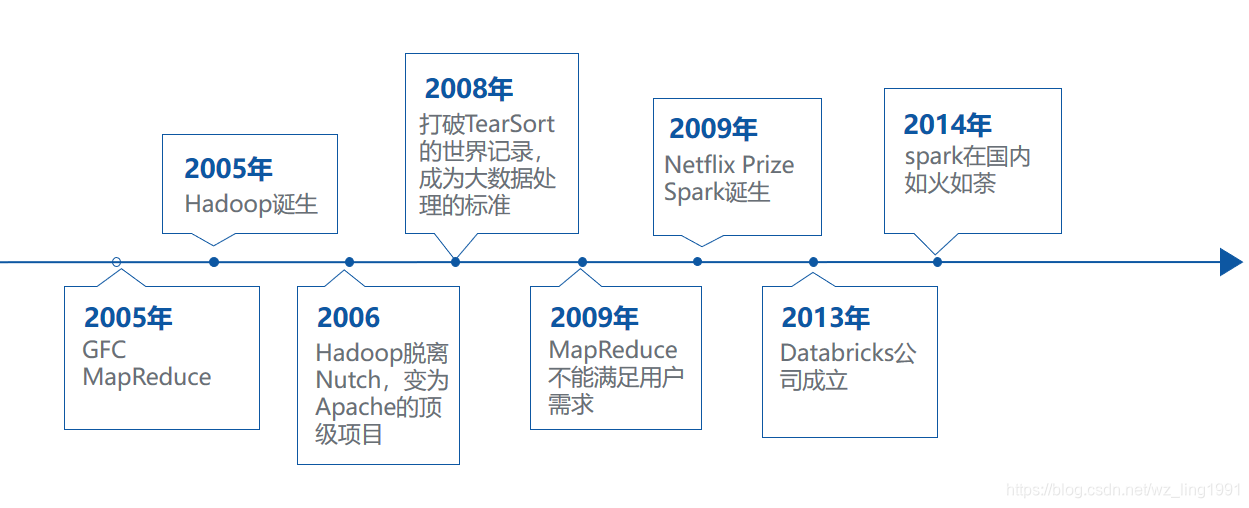
- Google的3大论文 GFC:2003年,Google发布Google File
System论文,这是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。从根本上说:文件被分割成很多块,使用冗余的方式储存于商用机器集群上。
MR:2004年,Google发布MapReduce论文,论文描述了大数据的分布式计算方式,主要思想是将任务分解然后在多台处理能力较弱的计算节点中同时处理,然后将结果合并从而完成大数据处理。
Bigtable:发布于2006年,启发了无数的NoSQL数据库,比如:HBase等。BigTable 是建立在 GFS 和MapReduce之上的。每个Table都是一个多维的稀疏图,为了管理巨大的Table,把Table根据行分割,这些分割后的数据统称为:Tablets。底层的架构是:GFS。
由此引申了3个重要的概念Distribute data、Distribute computation、Tolerate faults。 - 2005年hadoop诞生,最开始Hadoop只是用来支撑Nutch(一个基于java实现的搜索引擎);于2006年脱离Nutch成为apache的顶级项目;
- 紧着2008年,打破TearSort的世界记录,成为大数据处理的标准
- 2009年,MapReduce越来越不能满足用户的需求了。同年,Netflix举办NetflixPrize,百万美金的算法比赛,加州大学伯克利分校的Lester Mackey参加了这个比赛,但是他在做的过程中,发现一直在解决MapReduce的一些问题,然后他就找到了Matai Zaharia来解决这个问题,由此spark就诞生了。遗憾的是,他们设计出了和取得百万美金的Bellkor‘s pragmatic chaos有一样的效率的算法,然而代码晚提交了20min,导致与百万美金失之交臂。
- 2013年,Spark大数据处理系统多位创始人联合创立Databricks公司,致力于发展Spark
- 2014年之后,Spark在国内迅猛发展。
2、大数据系统中的一些不足、MapReduce的优缺点
针对集群环境出现了大量的大数据编程框架,一般随者一些新的业务场景、业务需求的出现,就需要新的系统/处理框架才能够完成,虽然说,也能解决问题,但是呢还是有一些不足:
- 重复工作:许多专有系统都在解决同样的问题,比如分布式作业及容错
- 组合问题:比如不同系统之间进行组合计算,有可能数据传输得代价比计算得代价更大
- 适用范围的局限性:如果不适用一个专有的计算系统,好像就只能换1个或者重新写1个
- 资源分配:在不同的计算引擎之间资源的动态共享比较难
- 管理问题:对于多个系统,使用者需要学习各种部署方案、各种api、各种系统模型
MapReduce的优点:可扩展性和容错性强
MapReduce的缺点:
- 不支持交互式计算、流式计算;
- 仅有Map和reduce两种操作,复杂任务不便处理,或者说处理起来很麻烦;
- 性能瓶颈,MapReduce的中间结果需要写磁盘。
3、spark是什么及特性
spark可以看作是MapReduce的替代品,但是个人觉得,他有种想在大数据生态系统中,在引擎这层想一统天下。
官网:http://spark.apache.org/
官方给的解释:Apache Spark is a unified analytics engine for large-scale data processing.
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。
它是一个计算引擎,引擎这个词很准确,说明它只是1个工具,只做数据的加工、处理、分析,不存储数据。
Lightning-fast unified analytics engine,通用、大数据处理、分析引擎。这里补充一点,spark主要是基于内存做计算的。
所以它具有以下特性
- a、speed:速度是hadoop的100倍,是hive的10倍(hive底层是mapreduce ),不知道现在这个速度有没有继续提高
- b、ease of use: 支持scala、java、python等多种语言,提供了80多个高级操作符
- c、generality:它包括spark core,spark sql(连接数据库,进行一些sql操作),spark streaming(接入实时流)、spark MlLib(机器学习)、sparkGraphx(图计算)
- d、run everywhere:它有多种运行模式,可以运行中Hadoop、Mesos、Yarn等等
4、spark架构及运行原理
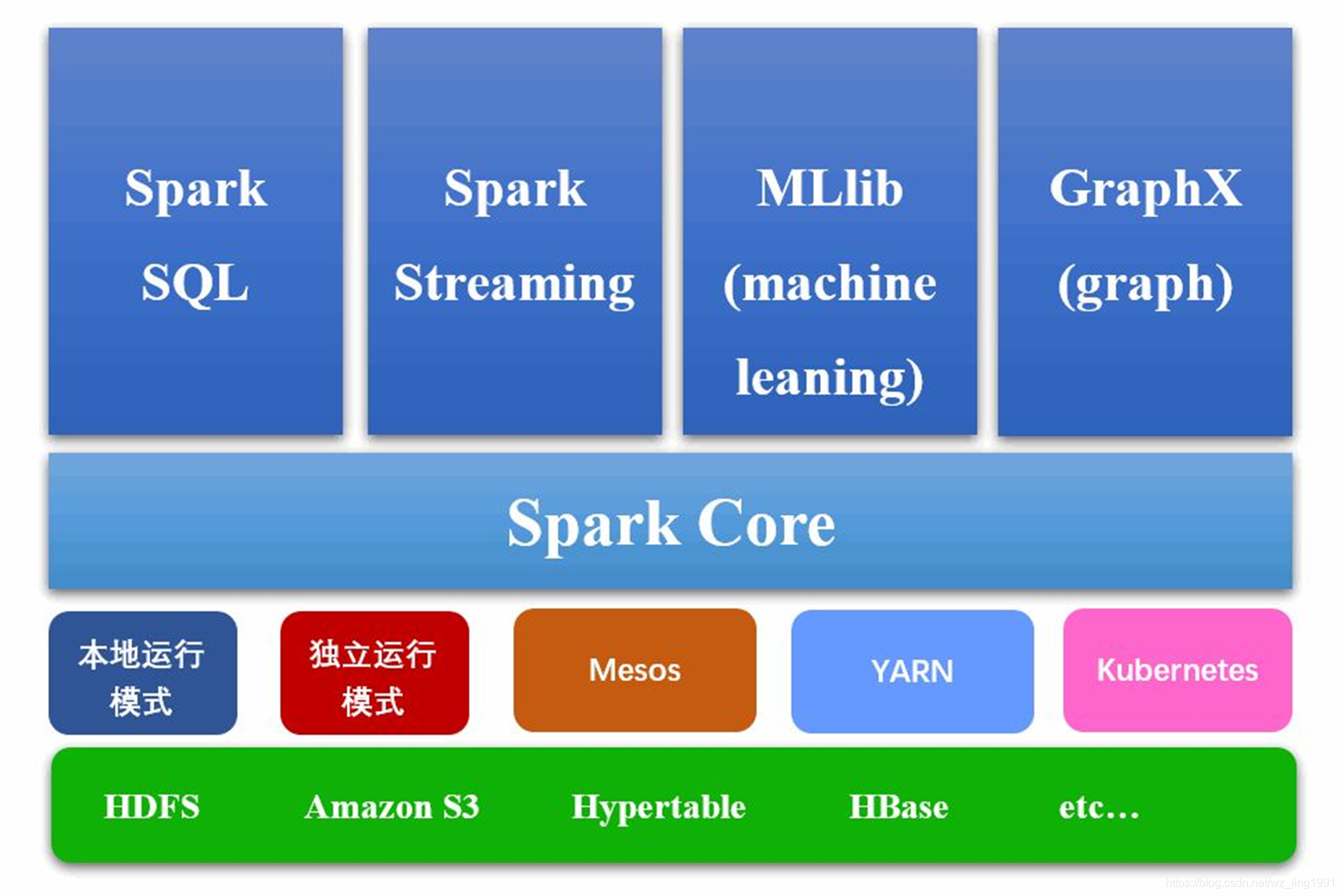
- 最底层为存储层,可以为Hdfs、Habse等等;
- 第2层为运行环境/模式层,运行模式多种多样,可以本地运行,也可以运行在Yarn、Mesos上,目前比较多的都是运行在Yarn上;
- 第3层spark核心的一些功能,spark的一些核心实现都是在这个里面;
- 第4层,个人认为是基于spark核心之上的一些扩展,
spark sql(shark的替代升级版,可以对比hive); spark streaming(一般处理实时流,多个storm做比较);spark MlLib(一般用在机器学习,里面有很多算法、模型,比如随机森林、决策树等等);spark Graph(一般用在图计算,什么向量计算、欧式距离、马氏距离等等)
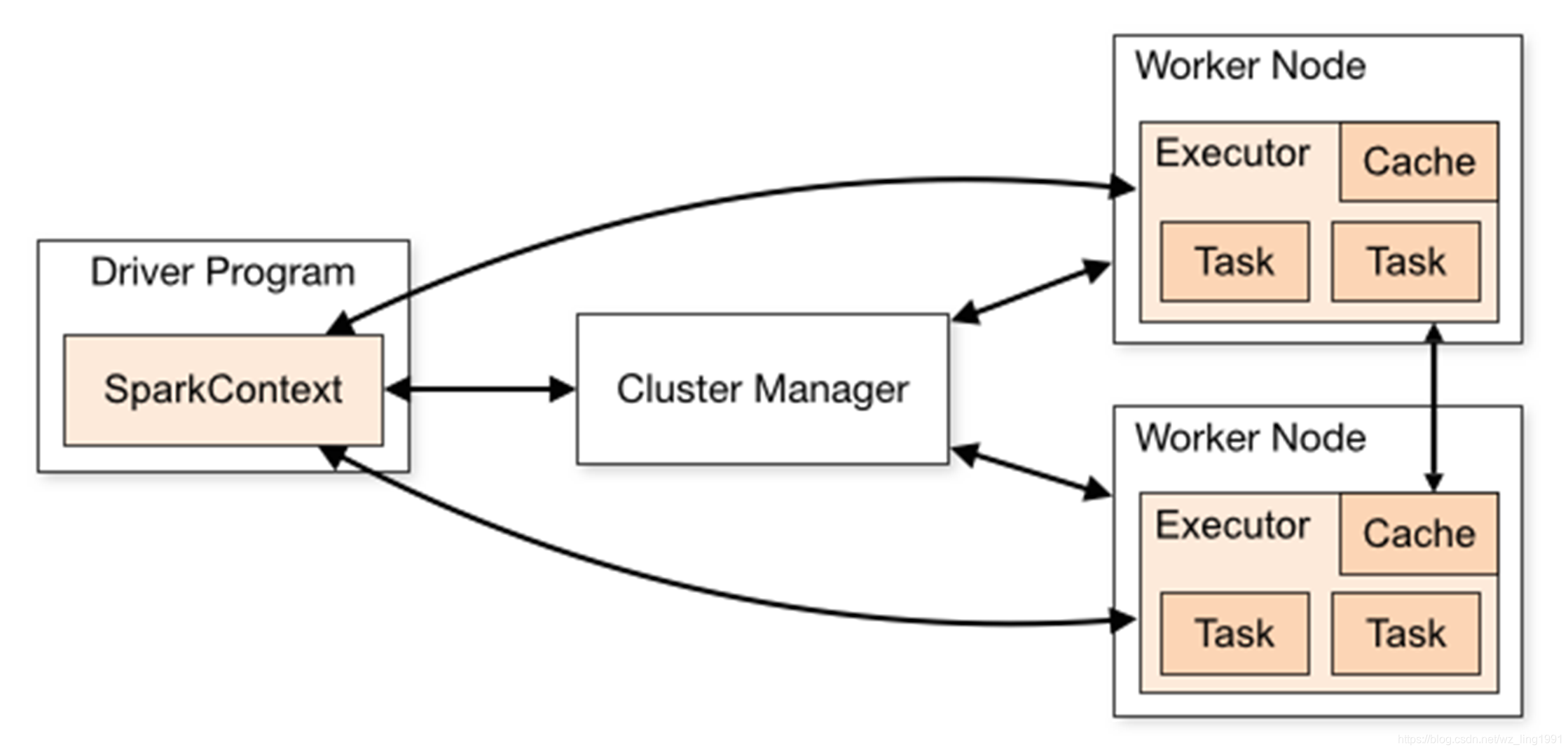
spark运行原理大体如上图,对于提交给不同的Cluster Manager有细微的差别。
spark的应用分为任务调度和任务执行两部分。sparkcontext有用户程序启动,通过资源调度模块(Cluster Manager)和Executor通信。因此sparkcontext和Executor的核心代码在各种模式下都是一样的,根据Cluster Manager不同,包装了不同的调度模块及相关适配代码。
以SparkContext为程序入口,在SparkContext的初始化过程中,spark会创建DAGScheduler作业调度和TaskScheduler任务调度,根据shuffle将spark分为多个stage,每个stage又分为多个task,然后将一组任务提交给任务调度模块,任务调度模块负责启动任务、监控、汇报任务的执行情况,而executor则负责具体的任务执行。
5、spark中的一些概念
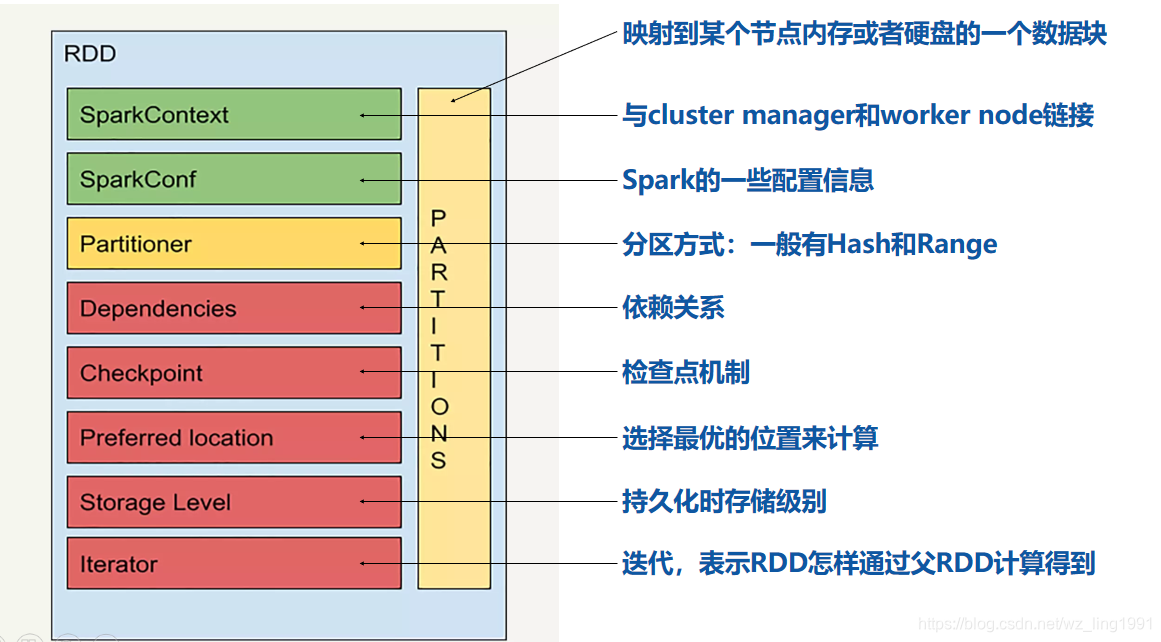
- RDD-Resilient Distributed DataSet
弹性分布式数据集,是1个抽象意义的数据集合。
a、弹性
①数据存储在不同的分区(每个分区对应1个数据块,分区中实际存储的是数据块的index)----->因此可以并行计算、内存迭代
②存储一般优先内存,当内存不足时,存储到磁盘 ③具有容错性(checkpoint机制、rdd之间具有依赖关系)
b、不可变
①rdd只读
②rdd两种来源(初始化-从内存、磁盘读取数据,从别的rdd转换而来) - 转换操作(transformation)和行动(action)操作
①转换操作是惰性操作,不会触发真正的计算,一般来说转换之后的类型不变,即还是rdd
②行动操作,触发真正的计算,一般结果不是rdd
③这里列了一些转换操作和行动操作:https://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations - 宽依赖和窄依赖
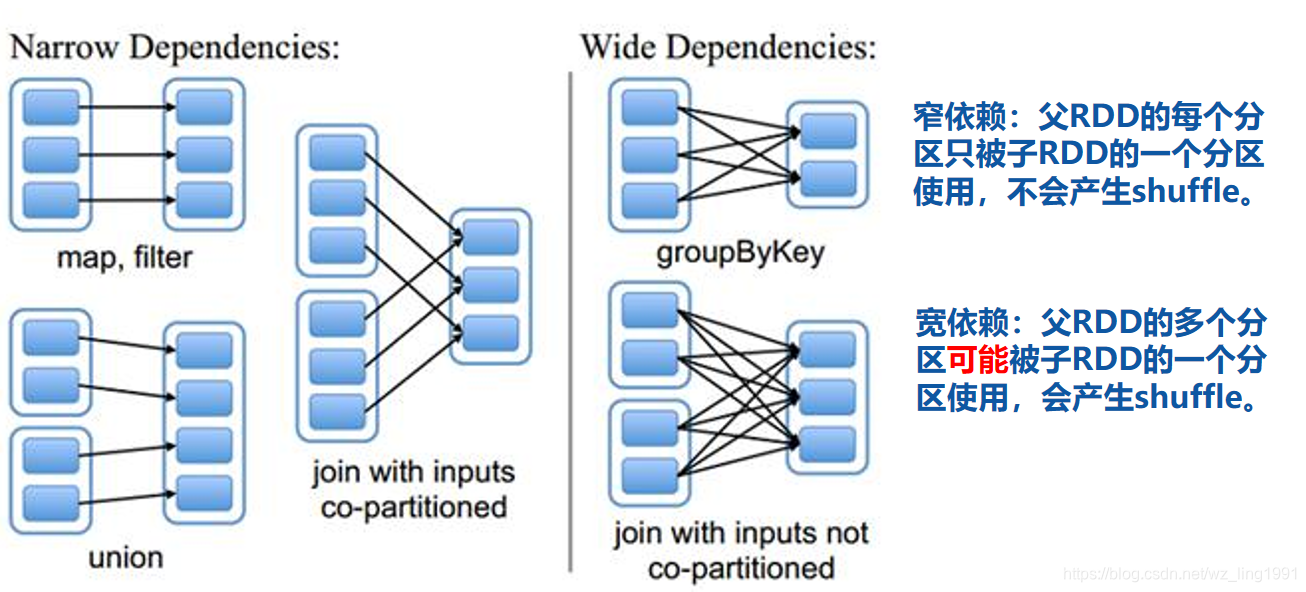
- shuffle
数据混洗,这个过程很复杂,本人能力有限,很难讲清楚底层具体执行过程。而且shuffle过程还经历了一些优化 - job、stage和task
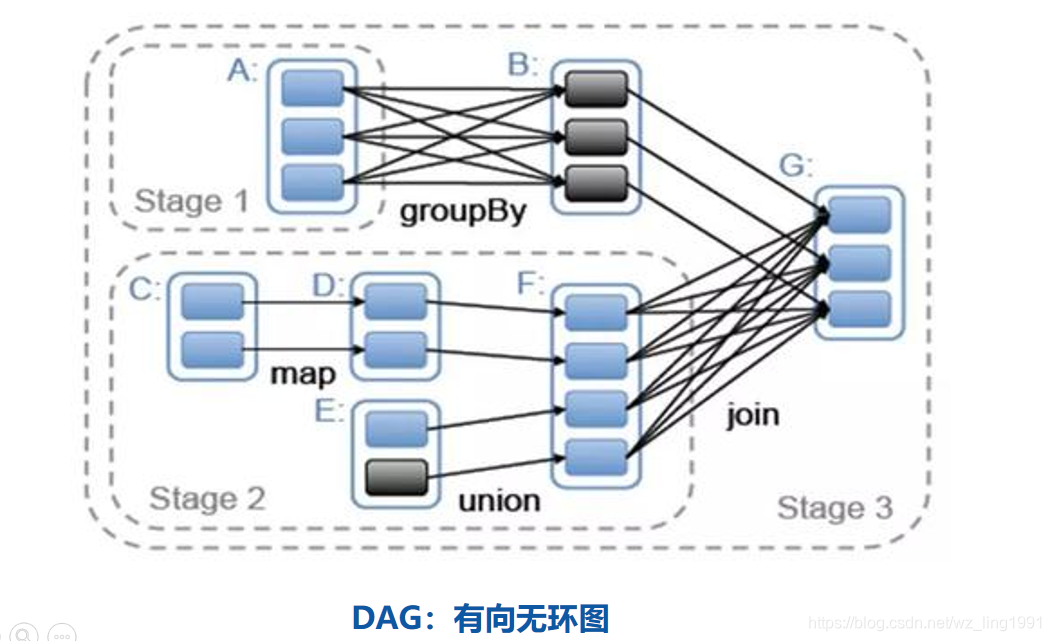
一般一个application包含多个job、1个job根据宽依赖分成多个stage、1个stage内包含多个task,一般而言每个stage包含的task的数量是分区数。
6、一些demo
源码:
https://github.com/wz-elysion/spark-demo
spark连hbase
hbase server version 1.3.2
spark 2.4.1
package wz_ling1991.spark;
import lombok.Getter;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* docker run -d --net=host --name hbase1.3 harisekhon/hbase:1.3
* 本例采用的hbase是容器跑的,为了避免端口映射麻烦,这里直接是host模式,如果机器上相关端口被占用,可能会导致启动失败
* 如果启动中报错请检查配置,
* 如果配置无误,还报错请在hosts下添加10.231.50.179 143f268bfea6(docker容器id)
*/
@Slf4j
public class SparkHBaseDemo {
public static void main(String[] args) {
String tableName = "test_hBase";
String family = "column1";
HBaseDemo hBaseDemo = new HBaseDemo(tableName);
Configuration hConfig = hBaseDemo.getHConfig();
// hBaseDemo.createTable(tableName,family);
// hBaseDemo.insertList(tableName, family, 1000000, 10000000);
// hBaseDemo.scan(tableName);
// hBaseDemo.delete(tableName);
spark(hConfig);
}
public static void spark(Configuration hConfig) {
SparkConf sparkConf = new SparkConf().setAppName("SparkHBaseDemo").setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
jsc.setLogLevel("WARN");
JavaPairRDD<ImmutableBytesWritable, Result> resultRDD = jsc.newAPIHadoopRDD(hConfig, TableInputFormat.class, ImmutableBytesWritable.class, Result.class);
log.warn("count:" + resultRDD.count());
resultRDD.flatMapToPair(x -> {
List<Tuple2<String, Integer>> list = new ArrayList();
for (Cell cell : x._2.rawCells()) {
String rowName = new String(CellUtil.cloneQualifier(cell));
String value = new String(CellUtil.cloneValue(cell));
list.add(new Tuple2<>(rowName, 1));
}
return list.iterator();
}).reduceByKey((x1, x2) -> x1 + x2).foreach(x -> log.info(x._1 + ":" + x._2));
while (true) {
//为了查看4040界面
}
}
}
@Slf4j
class HBaseDemo {
@Getter
private Configuration hConfig;
private Connection connection;
public HBaseDemo(String tableName) {
try {
hConfig = HBaseConfiguration.create();
hConfig.set("hbase.zookeeper.property.clientPort", "2181");
hConfig.set("hbase.zookeeper.quorum", "10.231.50.179");
hConfig.set(TableInputFormat.INPUT_TABLE, tableName);
connection = ConnectionFactory.createConnection(hConfig);
} catch (Exception e) {
log.error("init error", e);
}
}
public void createTable(String tableName, String... familyNames) {
try {
Admin hBaseAdmin = connection.getAdmin();
TableName table = TableName.valueOf(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(table);
for (String familyName : familyNames) {
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(familyName);
hTableDescriptor.addFamily(hColumnDescriptor);
}
hBaseAdmin.createTable(hTableDescriptor);
log.info("create table success");
} catch (Exception e) {
log.error("create table error:", e);
}
}
public void insertList(String tableName, String familyName, int start, int end) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
List<Put> putList = new ArrayList<>();
Random r = new Random();
int count = 0;
for (int i = start; i < end; i++) {
Put put = new Put(Bytes.toBytes("rowKey" + i));
String key = "key-" + r.nextInt(5);
put.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(key), Bytes.toBytes("value-" + i));
putList.add(put);
count++;
if (count / 1000000 == 1) {
table.put(putList);
log.info("插入1000000条数据");
putList.clear();
count = 0;
}
}
table.put(putList);
log.info("insert data success");
} catch (Exception e) {
log.error("insert data failed:", e);
}
}
public void scan(String tableName) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
ResultScanner resultScanner = table.getScanner(new Scan());
for (Result result : resultScanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
this.handleCell(cell);
}
}
} catch (Exception e) {
}
}
public void handleCell(Cell cell) {
String family = new String(CellUtil.cloneFamily(cell));
String rowKey = new String(CellUtil.cloneRow(cell));
String rowName = new String(CellUtil.cloneQualifier(cell));
String value = new String(CellUtil.cloneValue(cell));
log.info("column Family={},rowKey={},rowName={},value={}", family, rowKey, rowName, value);
}
public void delete(String tableName) {
try {
TableName tn = TableName.valueOf(tableName);
Admin admin = connection.getAdmin();
admin.disableTable(tn);
admin.deleteTable(tn);
log.info("delete table success");
} catch (Exception e) {
log.error("delete table failed:", e);
}
}
}
spark streaming连kafka
package wz_ling1991.spark;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.*;
@Slf4j
public class SparkStreamingDemo {
private static String bootstrapServers = "MEGVII818534267:19192";
private static String topic = "spark_streaming";
private static String groupId = "spark_streaming_demo";
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setAppName("Spark Streaming demo").setMaster("local[*]");
JavaStreamingContext jsc = new JavaStreamingContext(sparkConf, Durations.seconds(1));
jsc.sparkContext().setLogLevel("WARN");
kafkaStream(jsc);
jsc.start();
new Thread(() -> {
writeMsg(10000);
}).start();
jsc.awaitTermination();
}
public static void kafkaStream(JavaStreamingContext jsc) {
Collection<String> topics = Arrays.asList(topic);
JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
jsc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, consumerConfig())
);
JavaDStream<Tuple2<String, String>> rs = stream.map(record -> new Tuple2<>(record.key(), record.value()));
rs.foreachRDD(x -> {
log.warn("x.size={}", x.count());
x.collect().forEach(y -> log.warn("get message:{}", y));
});
}
public static Map<String, Object> producerConfig() {
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "MEGVII818534267:19192");
kafkaParams.put("key.serializer", StringSerializer.class);
kafkaParams.put("value.serializer", StringSerializer.class);
return kafkaParams;
}
public static Map<String, Object> consumerConfig() {
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", bootstrapServers);
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", groupId);
return kafkaParams;
}
public static void writeMsg(int size) {
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig());
for (int i = 0; i < size; i++) {
try {
String v = UUID.randomUUID().toString();
ProducerRecord<String, String> record = new ProducerRecord<>(topic, v);
producer.send(record).get();
log.warn("send success:v={}", v);
} catch (Exception e) {
log.error("send error:", e);
}
}
producer.close();
}
}
pom依赖(这里有其他的一些多余依赖,不需要的请自行删掉)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<name>spark-demo</name>
<properties>
<java.version>1.8</java.version>
<spark.version>2.4.1</spark.version>
<hbase.version>1.3.2</hbase.version>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- streaming-kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- mongo依赖 -->
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>2.4.1</version>
</dependency>
<!-- hbase依赖包 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- hadoop依赖包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>
</project>

















 2985
2985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









