




目录
引言:文件系统的重要性
在数字时代,数据存储已成为计算机系统的核心功能。想象一下,你的电脑硬盘就像一个大仓库,里面堆满了各种文件。如果没有一个合理的整理方式,找起东西来简直是大海捞针。文件系统就是这个仓库的"档案管理员",它负责把数据分门别类放好,让你能快速找到需要的文件。
Ext(Extended File System)系列是Linux系统中最经典的文件系统家族,从1992年诞生至今已经发展出多个版本:
- Ext2:最基础的版本,速度快但容易"丢三落四"(崩溃后可能丢失数据)
- Ext3:给Ext2加了个"记事本"(日志功能),出问题时能更快恢复
- Ext4:现在的"顶配版",支持超大文件和更智能的空间管理
一、磁盘的物理与逻辑结构
1.1 磁盘的物理组成
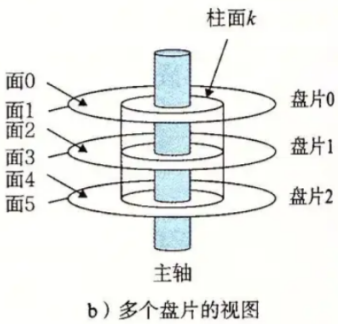
传统机械硬盘由多个盘片(platter)堆叠组成,每个盘片表面覆盖磁性材料,用于存储数据。盘片以每分钟5400-15000转的速度旋转,而磁头(head)则在盘片表面移动,读写数据。
数据存储在盘片的同心圆磁道(track)上,相同半径的磁道组成柱面(cylinder)。每个磁道又被划分为多个扇区(sector),通常是512字节大小,这是磁盘读写的最小物理单位。
就像老式唱片机一样:
- 盘片:数据存储的"唱片",一个硬盘可能有多个盘片叠在一起
- 磁头:读写数据的"唱针",每个盘面有一个
- 磁道:盘片上的同心圆,像田径场的跑道
- 扇区:最小的存储单元,固定512字节大小

1.2 CHS寻址与LBA转换
传统磁盘使用CHS(Cylinder-Head-Sector)三维坐标定位数据:
- 柱面号(C):确定磁道位置
- 磁头号(H):选择具体盘面
- 扇区号(S):定位磁道上的具体扇区
现代操作系统更倾向于使用LBA(Logical Block Address)线性寻址,将磁盘视为一维数组。CHS与LBA的转换公式为:
LBA = C × (磁头数 × 每磁道扇区数) + H × 每磁道扇区数 + S - 1给每个扇区一个连续的编号,就像给仓库的每个货架编号。这种抽象大大简化了磁盘访问逻辑,操作系统只需处理简单的块号,而磁盘控制器负责转换为物理位置。
1.3 块(Block):文件系统的基本单位
虽然磁盘物理读写以扇区(512B)为单位,但文件系统通常把多个扇区打包成一个大箱子,也就是将多个连续扇区组合成"块"(block),常见大小为4KB(8个扇区)。这种设计减少了I/O操作次数,提高了效率。
块是文件系统管理的最小单位,文件内容和元数据都以块为单位存储。选择适当的块大小需要在空间利用率与I/O性能间取得平衡:较大的块适合大文件但浪费空间,较小的块适合小文件但增加管理开销。
二、Ext2文件系统架构解析
2.1 整体布局设计
Ext2文件系统将分区划分为多个块组(Block Group),每个块组包含以下关键部分:
- 超级块(Super Block):记录文件系统全局信息,如大小、块数、inode数等
- 块组描述符表(GDT):描述每个块组的属性信息
- 块位图(Block Bitmap):标记数据块使用情况(1位代表1个块)
- inode位图(Inode Bitmap):标记inode使用情况
- inode表(Inode Table):存储所有inode结构
- 数据块(Data Block):实际存储文件内容
这种分组设计提高了可靠性和性能:部分块组损坏不会影响整个文件系统,且相关数据集中存储减少了磁头移动。
2.2 关键数据结构剖析
超级块是文件系统的控制中心,其结构包含:
struct ext2_super_block {
__le32 s_inodes_count; // inode总数
__le32 s_blocks_count; // 块总数
__le32 s_r_blocks_count; // 保留块数
__le32 s_free_blocks_count;// 空闲块数
__le32 s_free_inodes_count;// 空闲inode数
// ...其他字段...
};inode是文件系统的核心概念,每个文件/目录对应一个inode,存储元数据和数据块指针:
struct ext2_inode {
__le16 i_mode; // 文件类型和权限
__le16 i_uid; // 所有者UID
__le32 i_size; // 文件大小(字节)
__le32 i_atime; // 最后访问时间
__le32 i_ctime; // 创建时间
__le32 i_mtime; // 最后修改时间
__le32 i_blocks; // 占用块数(512B为单位)
__le32 i_block[15]; // 数据块指针数组
// ...其他字段...
};inode中的15个块指针采用多级索引设计:
- 前12个为直接指针,指向数据块
- 第13个为一级间接指针,指向包含块指针的块
- 第14个为二级间接指针
- 第15个为三级间接指针
这种设计使Ext2支持最大2TB的单个文件。
三、文件存储与管理机制
3.1 文件与inode的关联
Linux采用"文件=内容+属性"的分离存储模式:
- 内容:存储在分散的数据块中
- 属性:集中在inode中,包括权限、所有者、时间戳等
每个inode有唯一编号,通过ls -i命令可查看。文件系统通过inode号而非文件名识别文件,这也是硬链接实现的基础。
3.2 目录的实现原理
目录本质上是一种特殊文件,其内容不是普通数据,而是"文件名→inode号"的映射表。例如:
文件名 inode号
test.c 1596260
home 1596261路径解析过程如/home/user/file:
- 从根目录inode(通常为2)开始
- 查找"home"目录名对应的inode
- 在home目录中查找"user"
- 最终找到"file"的inode和数据块
3.3 路径缓存(dentry)优化
为避免每次路径解析都访问磁盘,内核维护dentry缓存,存储最近访问的目录项:
struct dentry {
atomic_t d_count; // 引用计数
struct inode *d_inode; // 关联的inode
struct hlist_node d_hash; // 哈希表节点
// ...其他字段...
};这种内存中的目录树结构可大幅提高文件访问速度,特别是频繁访问的路径。
四、Ext文件系统演进历程
4.1 Ext3:引入日志的里程碑
Ext3在Ext2基础上增加了日志功能,解决了系统崩溃后的长时间fsck问题。提供三种日志模式:
- journal:最高安全性,元数据和数据都先写日志
- ordered(默认):先写数据,再写元数据日志
- writeback:最高性能,不保证写入顺序
日志记录文件系统操作顺序,崩溃后只需重放日志即可恢复一致性,而非全盘扫描。
4.2 Ext4:现代存储的全面进化
Ext4带来了多项重要改进:
-
Extent分配:取代传统块指针,记录连续块范围,减少元数据量
struct ext4_extent { __le32 ee_block; // 起始逻辑块号 __le16 ee_len; // 连续块数 // ...物理块指针... };100个连续块仅需1条extent记录,较传统方案减少99%元数据
-
延迟分配:写入缓冲区时不立即分配块,待实际写入磁盘时统一分配,提高连续性
-
更大支持:文件系统最大1EB,单个文件最大16TB
-
其他特性:日志校验、无限制子目录、持久预分配等
Ext4的extent树形结构支持四层索引,可寻址最大128TB文件。
五、实用技术与性能优化
5.1 分区挂载与管理
创建和使用Ext4文件系统的基本命令:
# 创建磁盘镜像并格式化
dd if=/dev/zero of=./disk.img bs=1M count=1024
mkfs.ext4 ./disk.img
# 挂载到目录树
mount -t ext4 ./disk.img /mnt/data
# 调整参数
tune2fs -c 30 /dev/sda1 # 每30次挂载后检查5.2 链接机制对比
硬链接:
- 多个目录项指向同一inode
- 不能跨文件系统
ln file1 file2创建
软链接(符号链接):
- 特殊文件存储目标路径
- 可跨文件系统
ln -s target link创建
5.3 性能优化建议
-
挂载选项:
noatime:禁止更新访问时间,减少写入data=writeback:更高性能的日志模式(牺牲一些安全性)
-
维护工具:
e2fsck:检查修复文件系统resize2fs:调整文件系统大小e4defrag:碎片整理
-
SSD优化:
- 启用
discard挂载选项支持TRIM - 考虑减小日志大小(
tune2fs -J size=100)
- 启用
六、Ext文件系统的设计哲学
Ext系列体现了Unix的"一切皆文件"理念,无论是普通文件、目录、设备还是套接字,都通过统一的文件接口访问。这种一致性简化了系统设计,提高了灵活性。
文件系统的核心挑战在于平衡多个矛盾需求:
- 空间利用率与访问性能
- 数据安全与写入速度
- 简单设计与丰富功能
Ext系列通过分层设计(物理块→逻辑文件)、缓存机制和渐进式演进,在数十年间保持了其作为Linux默认文件系统的地位。
结语:为什么理解文件系统很重要
深入理解Ext文件系统不仅有助于系统管理和故障排查,更能启发我们设计高效的数据存储方案。从嵌入式设备到云服务器,从数据库存储到容器镜像,文件系统的选择与优化直接影响着整个系统的性能与可靠性。
下次当使用ls命令时,不妨思考这背后复杂的机制:磁头如何移动、inode如何被查找、数据如何被组织。正是这些精妙的设计,让简单的文件操作成为可能,也让数字世界的有序存储得以实现。
随着非易失性内存和分布式存储的发展,文件系统技术仍在快速演进。但Ext系列所确立的基本理念和架构,将继续影响未来的存储系统设计。

















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









