




 本文介绍了Storm事务处理的三个阶段:单个tuple的tid执行、批量提交提高效率、多节点并行保持强有序性。同时指出该机制可能导致资源浪费,并在消费时可以选择不从头开始。
本文介绍了Storm事务处理的三个阶段:单个tuple的tid执行、批量提交提高效率、多节点并行保持强有序性。同时指出该机制可能导致资源浪费,并在消费时可以选择不从头开始。


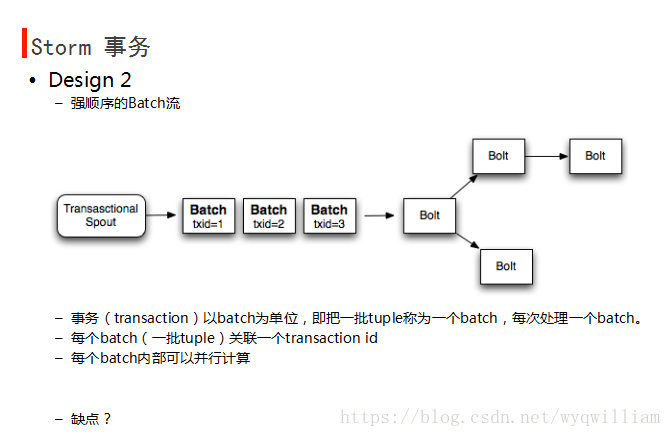



Storm事务基本原理分为三个阶段:
第一阶段:每一个tuple都有一个tid,一直到数据库,仅当第一个执行完之后才会执行第二个
第二阶段:每批次给一个tid,一批次一批次的执行,按批次提交,按批次提交效率较高
如果当前的事务没有提交到数据库,后边的就不允许处理
缺点是造成了资源的浪费,相当于hadoop中的federation情况
第三阶段:多个节点并行,但依然是强有序性,tuple不是简单的几百几千,要求绝对准确性。
消费的时候,可以设置不从头开始。不用设置from beginning
![]()

Storm事务基本原理分为三个阶段:
第一阶段:每一个tuple都有一个tid,一直到数据库,仅当第一个执行完之后才会执行第二个
第二阶段:每批次给一个tid,一批次一批次的执行,按批次提交,按批次提交效率较高
如果当前的事务没有提交到数据库,后边的就不允许处理
缺点是造成了资源的浪费,相当于hadoop中的federation情况
第三阶段:多个节点并行,但依然是强有序性,tuple不是简单的几百几千,要求绝对准确性。
消费的时候,可以设置不从头开始。不用设置from beginning
![]()
 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























