



 本文介绍了一种使用Hadoop MapReduce框架来统计每个月最高气温两天的方法。通过对源数据进行解析、自定义数据类型、排序规则和分组规则等步骤,最终实现了在大量气象数据中找出每月最热两天的目标。
本文介绍了一种使用Hadoop MapReduce框架来统计每个月最高气温两天的方法。通过对源数据进行解析、自定义数据类型、排序规则和分组规则等步骤,最终实现了在大量气象数据中找出每月最热两天的目标。
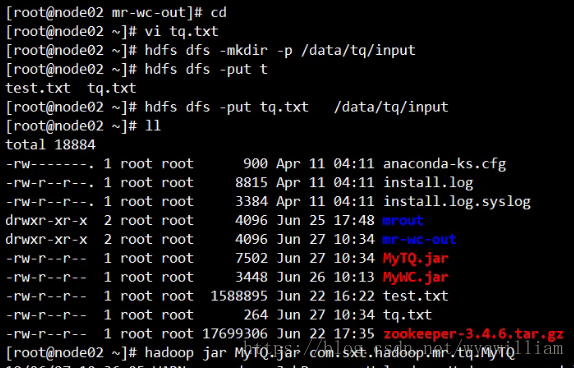
源数据:
1949-10-01 14:21:02 34c
1949-10-01 19:21:02 38c
1949-10-02 14:01:02 36c
1950-01-01 11:21:02 32c
1950-10-01 12:21:02 37c
1951-12-01 12:21:02 23c
1950-10-02 12:21:02 41c
1950-10-03 12:21:02 27c
1951-07-01 12:21:02 45c
1951-07-02 12:21:02 46c
1951-07-03 12:21:03 47c
需求: 找出每个月气温最高的2天
思路: 每年 每个月 最高 2天 1天多条记录?
进一部思考 年月分组 温度升序 key中要包含时间和温度呀!
MR原语:相同的key分到一组 通过GroupCompartor设置分组规则
自定义数据类型Weather 包含时间 包含温度
自定义排序比较规则
自定义分组比较 年月相同被视为相同的key 那么reduce迭代时,相同年月的记录有可能是同一天的 reduce中需要判断是否同一天 注意OOM 数据量很大 全
量数据可以切分成最少按一个月份的数据量进行判断
这种业务场景可以设置多个reduce 通过实现partition
代码:
主方法:
package com.bjsxt.tq;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestTQ {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(TestTQ.class);
job.setJobName("tq");
// input
Path input = new Path("/data/tq/input");
FileInputFormat.addInputPath(job, input);
// output
Path output =new Path("/data/tq/output");
if(output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
// maptask
// inputformat
// map
job.setMapperClass(TMapper.class);
job.setMapOutputKeyClass(TQ.class);
job.setMapOutputValueClass(IntWritable.class);
// partition
job.setPartitionerClass(TPartition.class);
// comp
job.setSortComparatorClass(TSortCompatator.class);
// reducetask
// groupingcomparator
job.setGroupingComparatorClass(TGroupingComparator.class);
// reduce
job.setReducerClass(TReducer.class);
job.waitForCompletion(true);
// submit
}
}
天气方法MapOutputKey:
package com.bjsxt.tq;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class TQ implements WritableComparable<TQ>{
private int year;
private int month;
private int day;
private int wd;
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
public int getWd() {
return wd;
}
public void setWd(int wd) {
this.wd = wd;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(year);
out.writeInt(month);
out.writeInt(day);
out.writeInt(wd);
}
@Override
public void readFields(DataInput in) throws IOException {
this.year = in.readInt();
this.month=in.readInt();
this.day = in.readInt();
this.wd=in.readInt();
}
@Override
public int compareTo(TQ that) {
int c1=Integer.compare(this.year, that.getYear());
if(c1==0){
int c2=Integer.compare(this.month, that.getMonth());
if(c2==0){
return Integer.compare(this.month,that.getMonth());
}
return c2;
}
return c1;
}
}
map端:
package com.bjsxt.tq;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TMapper extends Mapper<LongWritable,Text,TQ,IntWritable>{
TQ mkey = new TQ();
IntWritable mval = new IntWritable();
@Override
protected void map(LongWritable key,Text value,Context context){
String[] strs = StringUtils.split(value.toString(),'\t');
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
try {
Date date = sdf.parse(strs[0]);
Calendar cal =Calendar.getInstance();
cal.setTime(date);
mkey.setYear(cal.get(Calendar.YEAR));
mkey.setMonth(cal.get(Calendar.MONTH)+1);
mkey.setDay(cal.get(Calendar.DAY_OF_MONTH));
int wd= Integer.parseInt(strs[1].substring(0, strs[1].length()-1));
mkey.setWd(wd);
mval.set(wd);
context.write(mkey, mval);
} catch (Exception e) {
e.printStackTrace();
}
}
}
分区:
package com.bjsxt.tq;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class TPartition extends Partitioner<TQ , IntWritable>{
@Override
public int getPartition(TQ key, IntWritable value, int numPartitions) {
return key.getYear() % numPartitions;
}
}
map端的比较:
package com.bjsxt.tq;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class TSortCompatator extends WritableComparator{
public TSortCompatator(){
super(TQ.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
TQ t1 = (TQ)a;
TQ t2 = (TQ)b;
int c1 = Integer.compare(t1.getYear(), t2.getYear());
if(c1 == 0){
int c2 = Integer.compare(t1.getMonth(), t2.getMonth());
if(c2 == 0){
return -Integer.compare(t1.getWd(), t2.getWd());
}
return c2;
}
return c1;
}
}
reduce端的比较:
package com.bjsxt.tq;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class TGroupingComparator extends WritableComparator{
public TGroupingComparator(){
super(TQ.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b){
TQ t1 =(TQ)a;
TQ t2 =(TQ)b;
int c1=Integer.compare(t1.getYear(), t2.getYear());
if(c1==0){
return Integer.compare(t1.getMonth(), t2.getMonth());
}
return c1;
}
}
reduce端:
package com.bjsxt.tq;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TReducer extends Reducer<TQ,IntWritable,Text,IntWritable>{
Text rkey = new Text();
IntWritable rval = new IntWritable();
@Override
protected void reduce(TQ key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int flg =0 ;
int day = 0;
for (IntWritable v : values) {
if(flg == 0){
rkey.set(key.getYear()+"-"+key.getMonth()+"-"+key.getDay());
rval.set(key.getWd());
context.write(rkey, rval);
day=key.getDay();
flg ++;
}
if(flg != 0 && day != key.getDay()){
rkey.set(key.getYear()+"-"+key.getMonth()+"-"+key.getDay());
rval.set(key.getWd());
context.write(rkey, rval);
break;
}
}
}
}

写代码的前提是弄清楚框架,然后往里边填充:
写代码钱的配置
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(TestTQ.class);
job.setJobName("tq");
首先是输入路径
Path input = new Path("/data/tq/input");
FileInputFormat.addInputPath(job, input);
其次是输出路径
Path output =new Path("/data/tq/output");
if(output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
map端:
job.setMapperClass(TMapper.class);
分区个数:
job.setPartitionerClass(TPartition.class);
输出的key
job.setMapOutputKeyClass(TQ.class);
输出的value
job.setMapOutputValueClass(IntWritable.class);
map端的排序:
job.setSortComparatorClass(TSortCompatator.class);
reduce端:
job.setReducerClass(TReducer.class);
reduce端的排序:
job.setGroupingComparatorClass(TGroupingComparator.class);
提交:
job.waitForCompletion(true);

















 1526
1526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









