



 本文介绍Spark中的广播变量机制,解释其工作原理及如何减少Executor内存占用。通过代码示例展示了如何定义并使用广播变量,以及它与RDD的区别。
本文介绍Spark中的广播变量机制,解释其工作原理及如何减少Executor内存占用。通过代码示例展示了如何定义并使用广播变量,以及它与RDD的区别。
1.广播变量
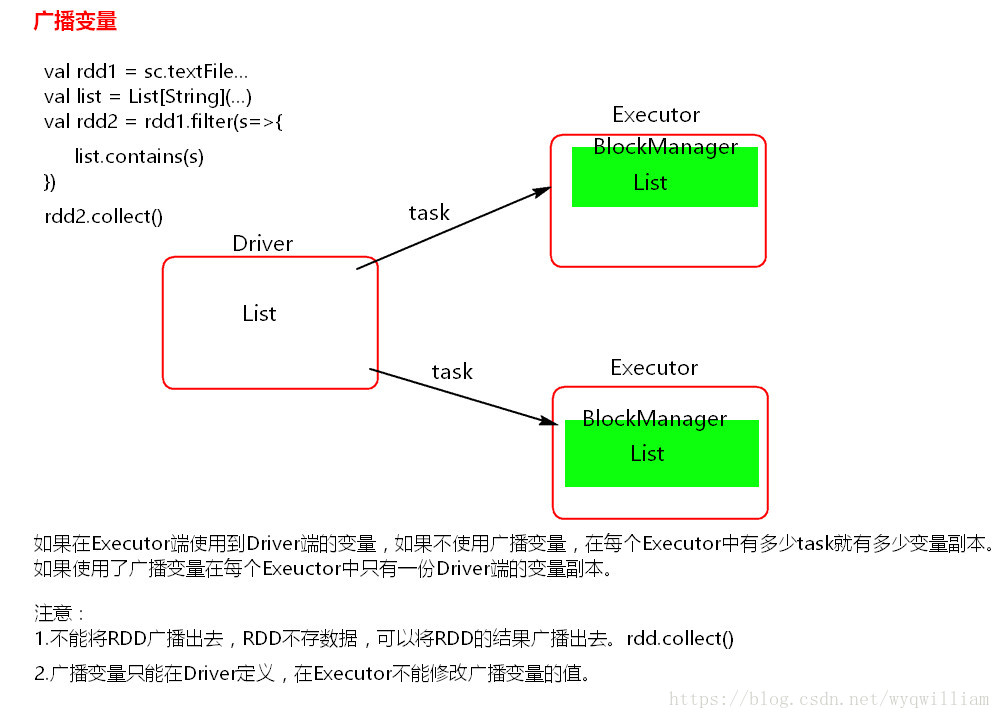
当在Executor端用到了Driver变量,不使用广播变量,在每个Executor中有多少个task就有多少个Driver端变量副本。
如果使用广播变量在每个Executor端中只有一份Driver端的变量副本。
val broadcast = sc.broadCast(...)
broadcast.value()
注意:
1).不能将RDD广播出去,可以将RDD的结果广播出去
2).广播变量在Driver定义,在Exector端不可改变,在Executor端不能定义
一.原理
广播变量:实际上就是Executor端用到了driver端的变量
如果在executor端你使用到了driver端的广播变量,如果不使用广播变量,在每个executor中有多少task就有多少变量副本。
注意:
- 不能将RDD广播出去,RDD不存数据,可以将RDD的结果广播出去,rdd.collect()
- 广播变量只能在Driver定义,在Executor端不能修改广播变量的值。
使用了广播变量,实际上就是为了减少executor端的备份,最终减少executor端的内存。
举个简单的例子:driver端有1000个变量,如果不使用广播变量的话,从driver端发给executor端有1000个备份,使用了广播变量,就会只有一个备份,从而可以减少executor端的内存。
二.图解说明
三.代码实现
package com.bjsxt;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.broadcast.Broadcast;
public class Add {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("test").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
/**
* 对于广播变量的理解
*/
// list要转换成final类型的修饰
final List<String> asList = Arrays.asList("hello java", "hello python", "hello word");
/**
* 设置广播变量 将aslist广播出去
*/
final Broadcast<List<String>> broadcast = sc.broadcast(asList);
JavaRDD<String> rdd1 = sc.parallelize(Arrays.asList("hello java", "hello python", "hello text"));
JavaRDD<String> rdd2 = rdd1.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String line) throws Exception {
/**
* aslist中包含line的部分 然后再在此基础上取反
*/
// return !asList.contains(line);
/**
* 返回广播变量获取的值
*/
return !broadcast.value().contains(line);
}
});
/**
* 循环打印输出 同时也是触发执行
*/
rdd2.foreach(new VoidFunction<String>() {
@Override
public void call(String arg0) throws Exception {
System.out.println(arg0);
}
});
}
}


















 4427
4427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









