









 本文深入探讨Ceph存储系统的优化策略,涵盖SSD与HDD混合使用技巧,以及Rack级隔离确保双副本数据安全的方法。通过实例演示,读者将学会如何在不同存储介质间平衡性能与成本,同时掌握在资源受限场景下,通过Rack级Bucket实现数据分布,保障数据安全性的具体步骤。
本文深入探讨Ceph存储系统的优化策略,涵盖SSD与HDD混合使用技巧,以及Rack级隔离确保双副本数据安全的方法。通过实例演示,读者将学会如何在不同存储介质间平衡性能与成本,同时掌握在资源受限场景下,通过Rack级Bucket实现数据分布,保障数据安全性的具体步骤。
作者:【吴业亮】
博客:https://wuyeliang.blog.youkuaiyun.com/
开篇:
目前企业的业务场景多种多样,并非所有Ceph存储解决方案都是相同的,了解工作负载和容量要求对于设Ceph解决方案至关重要。Ceph可帮助企业通过统一的分布式集群提供对象存储、块存储或文件系统存储。在设计流程中,这些集群解决方案针对每项要求都进行了优化。该设计流程的首要因素包括 IOPS 或带宽要求、存储容量需求以及架构和组件选择,确保这些因素的合理性有助于完美平衡性能和成本。不同类型的工作负载需要不同的存储基础设施方案。

下面将从以下6个方面介绍ceph的通用解决方案
- 性能方面:
1、如何ssd作为Ceph-osd的日志盘使用
2、如何同一个Ceph集群分别创建ssd和hdd池
3、如何将ssd作为hdd的缓存池
4、如何指定ssd盘为主osd,hdd为从osd
- 稳定及数据安全性方面:
5、Ceph双副本如何保证宕机数据的安全性
6、Ceph纠删码理论与实践
注意:该文章同时在华云数据官方公众号上发布过
智汇华云 | Ceph的正确玩法之Ceph双副本如何保证宕机数据的安全性
下面我们开始专题:Ceph双副本如何保证宕机数据的安全性
场景一:
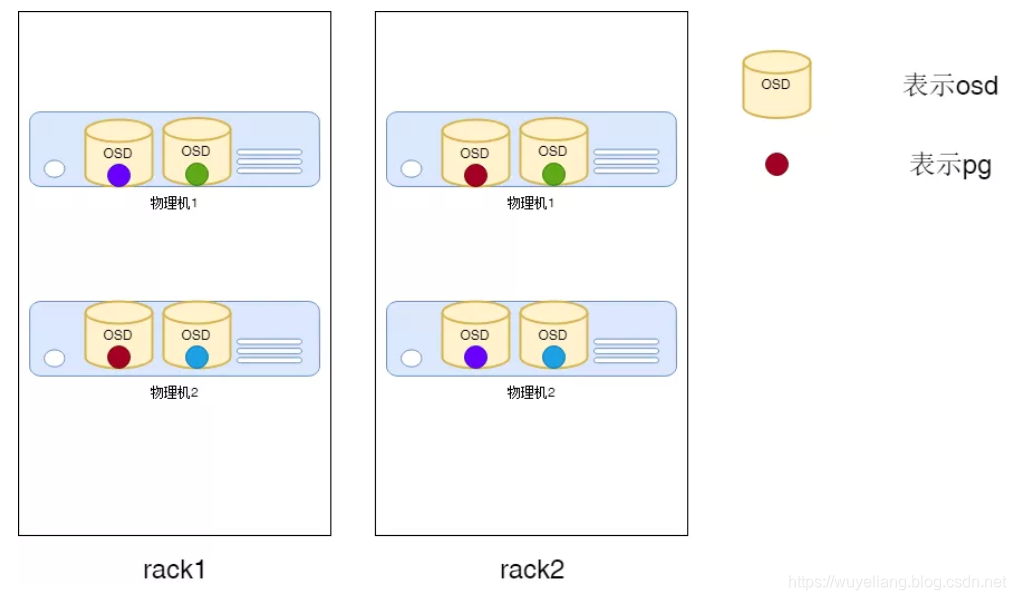
生产环境一般都是三副本存储,但一些场景为了节省资源,将副本调整为2副本。两副本要求将数据分布在不同的机器上,防止集群故障时数据丢失。
我们为此添加Rack级的Bucket,分别包含两个存储节点(以Host的Bucket),然后以Rack为隔离域,保证两个副本分别落在不同的Rack上。
示意图如下:
1、修改操作
修改前数据备份,以防万一。crushmap备份
# ceph osd getcrushmap -o backup.txt
恢复:
# ceph osd setcrushmap -i backup.txt
2、理论与实践相结合
1)、创建机柜
ceph osd crush add-bucket rack1 rack
ceph osd crush add-bucket rack2 rack
2)、将rack移动到root下
# ceph osd crush move rack1 root=default
# ceph osd crush move rack2 root=default
3)、将主机移动到机柜中
# ceph osd crush move node1 rack=rack1
# ceph osd crush move node2 rack=rack2
4)、创建rule
# ceph osd crush rule create-simpletestrule default rack firstn
5)、修改已经创建pool的rule
luminus 以后版本设置pool规则的语法是
# ceph osd pool set demo crush_ruletestrule
luminus以前版本设置pool规则的语法是
查看rule的ID
# ceph osd crush rule dump | grep testrule
# ceph osd pool set demo crush_ruleset 1
此处1是指在rule里rule_ id设置的值
6)、创建pool
# ceph osd pool create demo 64 64replicated testrule
7)、在ceph.conf中加入防止集群重启crush map被重置
osd crush update on start = false

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









