









Flink
yum install java-11-openjdk-devel # 下载安装Java11
alternatives --config java # 切换Java环境
java -version # 查看当前java版本环境
tar -zxvf flink-1.16.0-bin-scala_2.12.tgz -C /opt/
cd /opt/flink-1.16.0/bin/
./start-cluster.sh
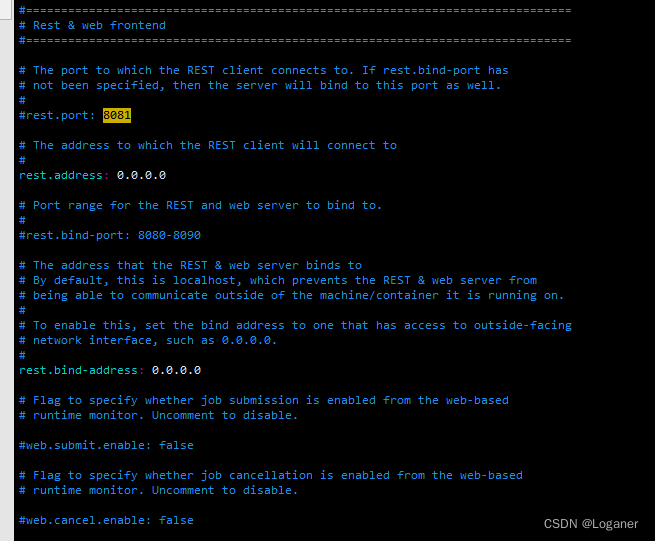
vim ../conf/flink-conf.yaml # 修改配置文件如下图所示
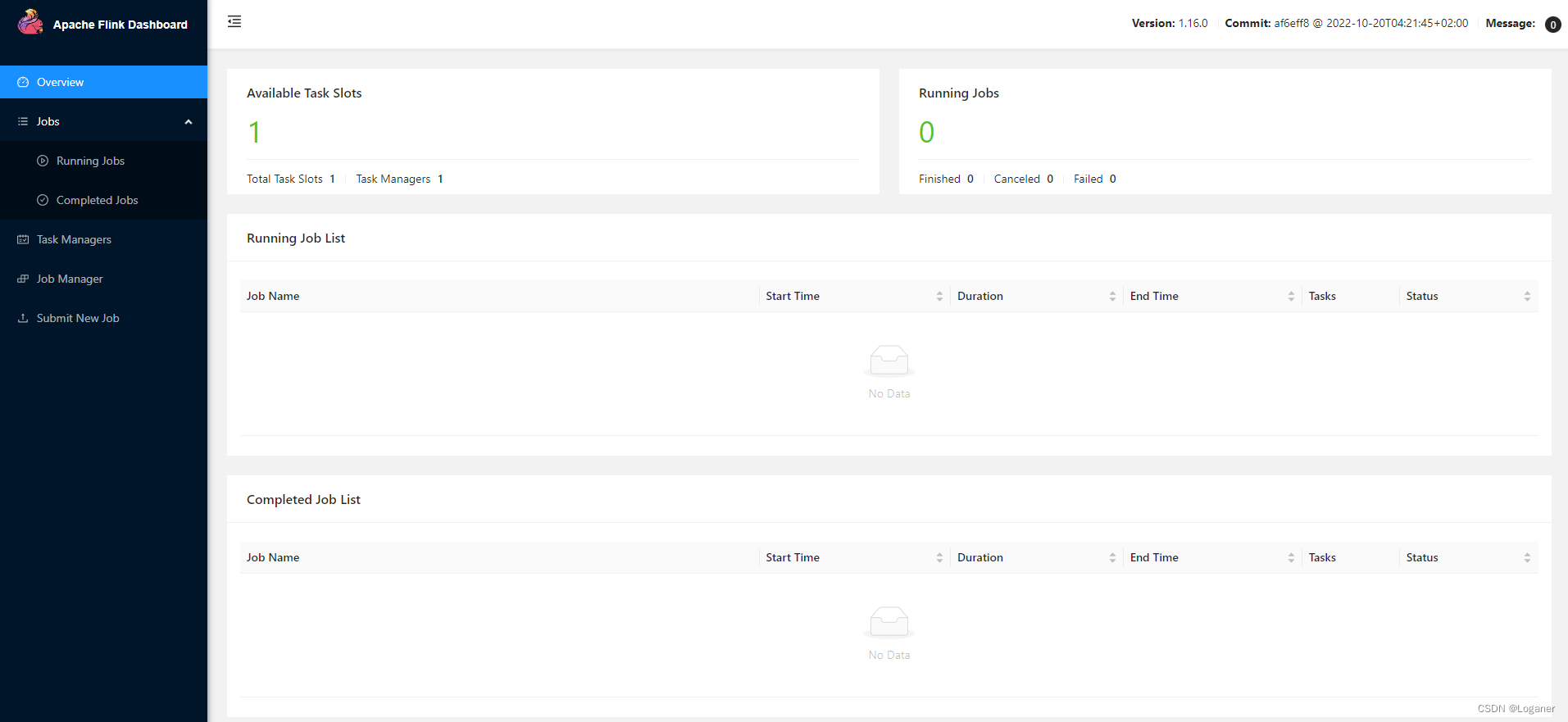
接着输入 ip:port(一般是8081) 就可以看到Flink自带的web管理界面
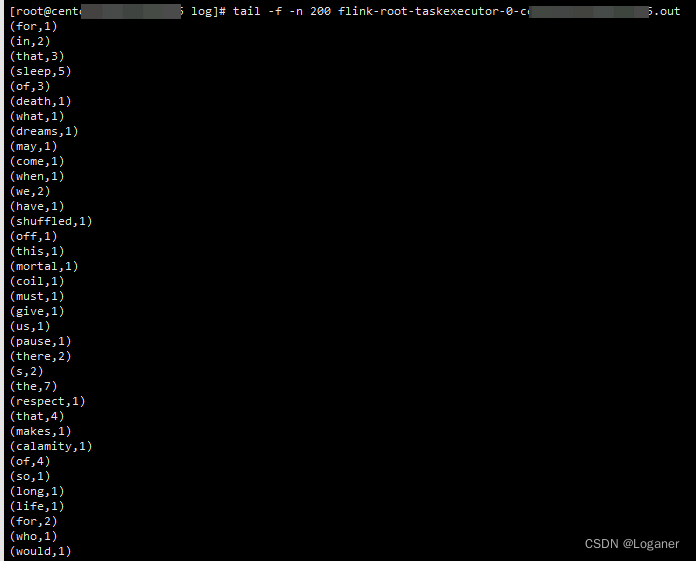
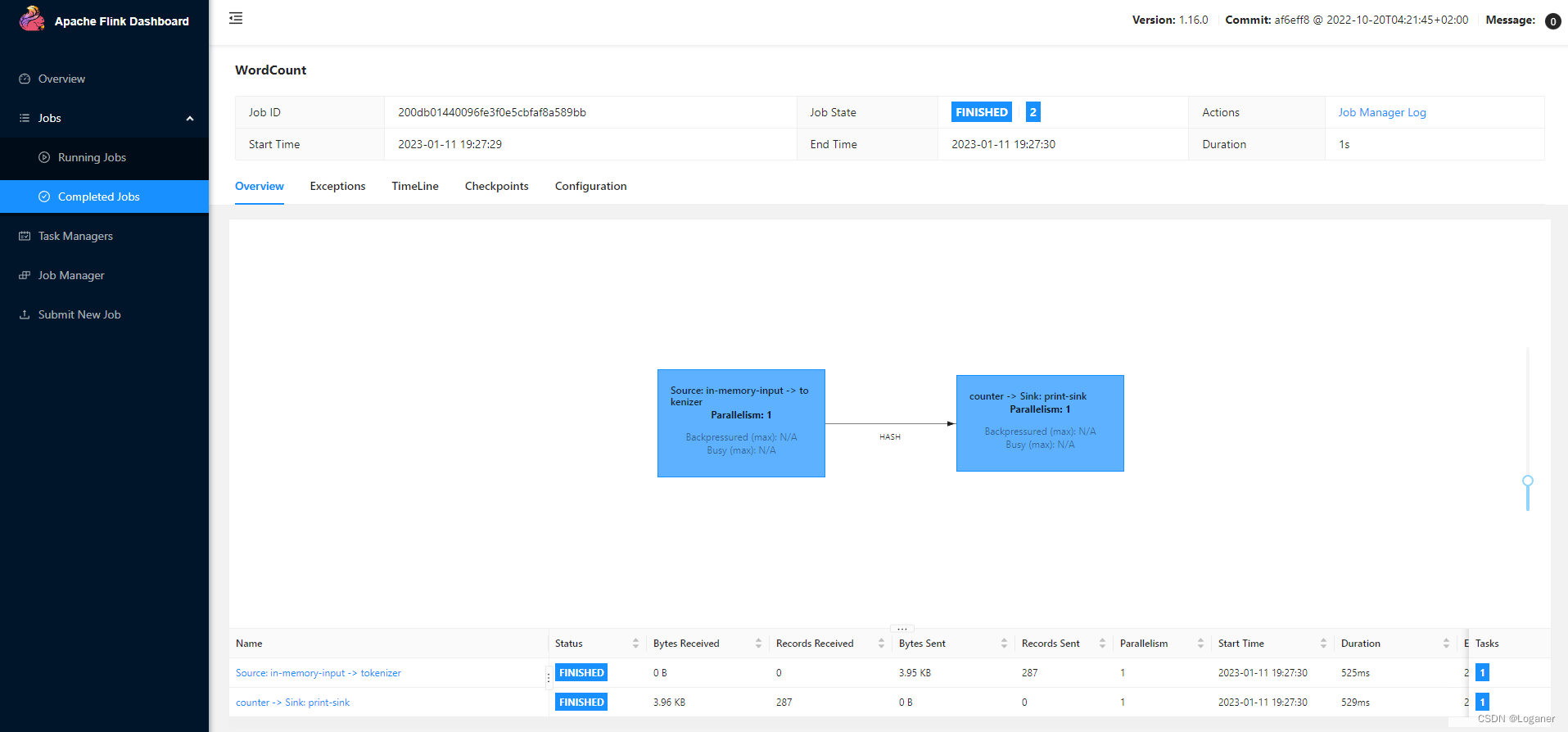
./flink run ../examples/streaming/WordCount.jar # 跑个官方demo
- 用sql-client 建个表
./bin/sql-client.sh
-- 创建 kafka 表, 读取 kafka 数据
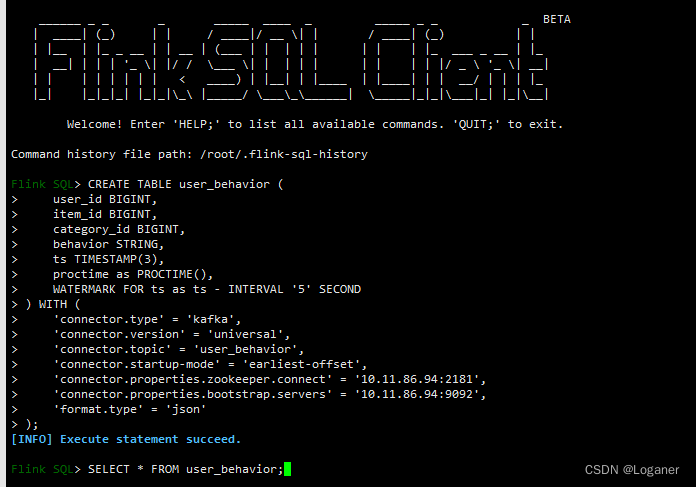
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3),
proctime as PROCTIME(),
WATERMARK FOR ts as ts - INTERVAL '5' SECOND
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'user_behavior',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.zookeeper.connect' = '10.11.86.94:2181',
'connector.properties.bootstrap.servers' = '10.11.86.94:9092',
'format.type' = 'json'
);
SELECT * FROM user_behavior;
Zookeeper
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local/zookeeper # 下载后解压到指定目录下
cd /usr/local/zookeeper/
cd apache-zookeeper-3.7.1-bin/
mkdir data # 新建data目录
cd conf/ && mv zoo_sample.cfg zoo.cfg # 重命名配置文件
vim zoo.cfg # 设置dataDir dataDir=/usr/local/zookeeper/apache-zookeeper-3.7.1-bin/data
cd ../bin/ # ./zkServer.sh start / stop / status

Kafka
tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/
cd /opt/
mv kafka_2.12-3.3.1/ kafka
cd /opt/kafka/config/
vi server.properties # 修改内容如下
broker.id=0
advertised.listeners=PLAINTEXT://192.168.247.201:9092
log.dirs=/opt/kafka/kafka-logs
zookeeper.connect=192.168.247.201:2181
kafka-server-start.sh -daemon ../config/server.properties
- 往Kafka中写入数据
import sys
import time
import json
import queue
from kafka import KafkaProducer
from concurrent.futures import ThreadPoolExecutor
servers = ['10.11.ip.ip:9092', ]
topic = 'user_behavior'
path = 'user_behavior.log'
producer = KafkaProducer(bootstrap_servers=servers, value_serializer=lambda m: json.dumps(m).encode('utf-8'))
def send(line):
cols = line.strip('\n').split(',')
ts = time.strftime("%Y-%m-%dT%H:%M:%SZ", time.localtime(int(cols[4])))
value = {"user_id": cols[0], "item_id": cols[1], "category_id": cols[2], "behavior": cols[3], "ts": ts}
producer.send(topic=topic, value=value).get(timeout=10)
if __name__ == "__main__":
num = 2000
if len(sys.argv) > 1:
num = int(sys.argv[1])
class BoundThreadPoolExecutor(ThreadPoolExecutor):
def __init__(self, *args, **kwargs):
super(BoundThreadPoolExecutor, self).__init__(*args, **kwargs)
self._work_queue = queue.Queue(num * 2)
with open(path, 'r', encoding='utf-8') as f:
pool = BoundThreadPoolExecutor(max_workers=num)
# for result in pool.map(send, f):
# ...
for arg in f:
pool.submit(send, arg)
pool.shutdown(wait=True)
print("SUCCESS!")
- 查看Topic列表
./bin/kafka-topics.sh --list --bootstrap-server 10.11.ip.ip:9092
- 查看Topic的describe
./bin/kafka-topics.sh --bootstrap-server 10.11.ip.ip:9092 --topic user_behavior --describe
未完待续…


















 5916
5916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











