




 本文探讨了warmup策略在深度学习中的关键作用,如何通过线性或非线性方式逐步增加学习率,避免初期训练不稳定,提高模型收敛效率。通过实例和理论解释,揭示了warmup有效的原因,并提供了参考文献。
本文探讨了warmup策略在深度学习中的关键作用,如何通过线性或非线性方式逐步增加学习率,避免初期训练不稳定,提高模型收敛效率。通过实例和理论解释,揭示了warmup有效的原因,并提供了参考文献。
1. 什么是warmup
最近在看论文的时候看到了一个专业术语,如下所示:
Furthermore, we used a linear warm-up of the learning rate[12] in the first five epochs.
然后网上查了资料,称这个叫做: 预热学习率
📝 名词解释
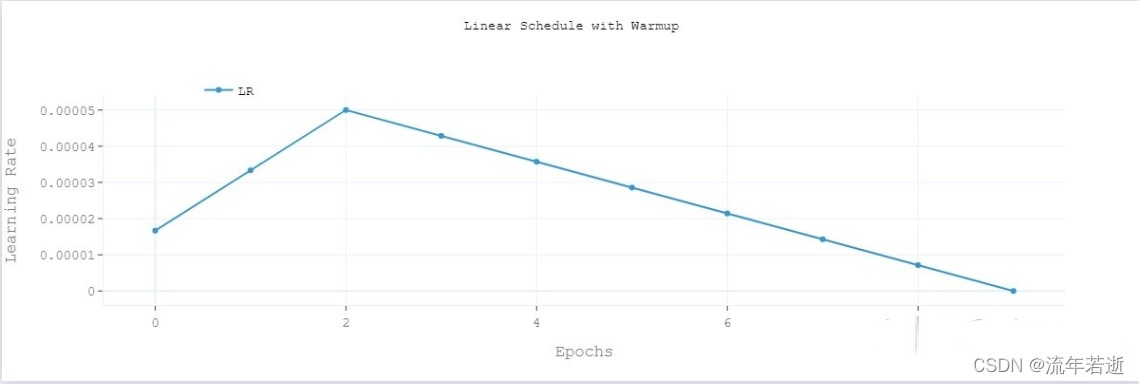
warm-up是针对学习率learning rate优化的一种策略,主要过程是:在预热期间,学习率从0线性(也可非线性)增加到优化器中的初始预设lr,
之后使其学习率从优化器中的初始lr线性降低到0。
如下图所示:
2. warmup的作用
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳
定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoch或者一些step内学习率较小,在预热的
小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变 得更快,模型效果更佳。
下面是自己看论文里面别人使用这个预热学习率的代码:
def warmup_learning_rate(args, epoch, batch_id, total_batches, optimizer):
if args.warm and epoch <= args.warm_epochs:
p = (batch_id + (epoch - 1) * total_batches) / \
(args.warm_epochs * total_batches)
lr = args.warmup_from + p * (args.warmup_to - args.warmup_from)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
🔗 参考链接: SupContrast: Supervised Contrastive Learning
3. 为什么warmup有效
为什么warm-up 有效这点我没有深究,但是从使用它的效果来看可以得到如下结论:
有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
有助于保持模型深层的稳定性
从训练效果可以体现为:
一开始神经网络输出比较random,loss比较大,容易不收敛,因此用小点的学习率, 学一丢丢,慢慢涨上去。
梯度偏离真正较优的方向可能性比较大,那就走短一点错了还可以掰回来。
这里有一篇文章关于解释为什么warm-up有效,但是还是没有完全说清楚:
🔗 参考链接: 神经网络中 warmup 策略为什么有效;有什么理论解释么?
4. 参考文献
5. 📞 联系 👨



















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









