






互联网风云变幻,最近网上的壮士们经过不懈努力,成功揪出作家莫言为一害,微博上的壮士们给出的理由是“如果莫言是个好人,会给他发诺贝尔文学奖?”

此风波的始作俑者来自某大V,他信誓旦旦要起诉莫言老师,他的诉讼请求,首先是代表“15亿中国人”要莫言道歉,然后再代表“15亿中国人”向莫言索赔。
我认为,你个人想整坏水就自己整,不要上升到中国人的高度,也不要代表其他人。这样的跳梁小丑,你不配,没资格。
对于网上的除害呼声,我特别凑了三个,与热映大片《周处除三害》相应景。
1、英语:一直在铲除,一直在努力,最多就一纸行政命令的事儿。

2、谷歌:铲除不了,那就雪藏,2014年已经这样干了。
3、ChatGPT:铲除不了,作法同谷歌,但效率更高。该产品发布当天,其官网已无法直接访问。

这三害,是某些人的毒草,但却是更多人的益生菌。
这两天“知识大航海”群里的姐姐分享了关于ChatGPT的学习心得。

我读了受益匪浅,摘录整理如下。
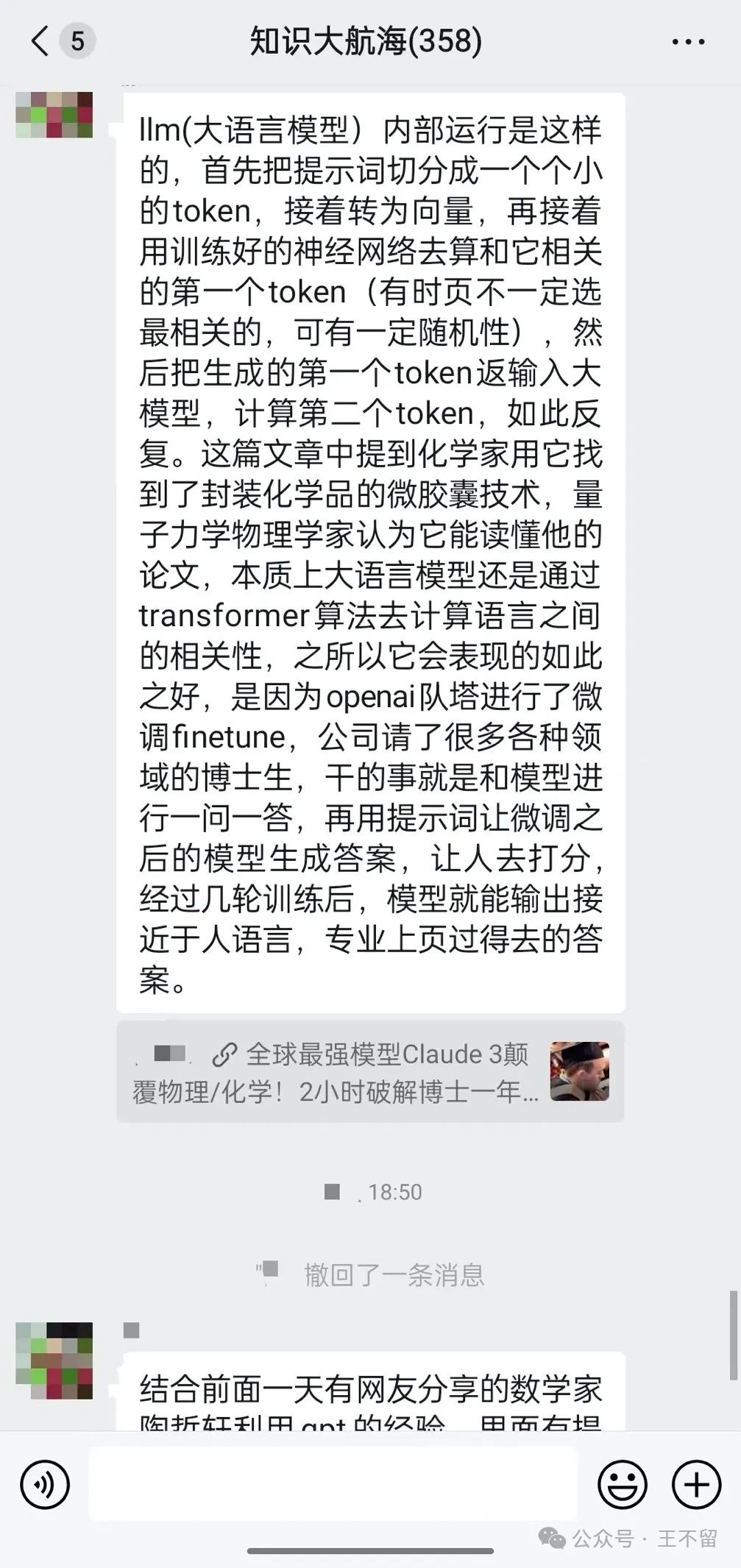
LLM(大语言模型)内部运行是这样的,首先把提示词切分成一个个小的token,接着转为向量,再接着用训练好的神经网络去算和它相关的第一个token(有时也不一定选最相关的,可有一定随机性),然后把生成的第一个token返输入大模型,计算第二个token,如此反复。
gpt之所以能够看似”创造性“地使用人类语言来完成任务,是因为人类的语言并不是像先前看似的那么”难以计算“。
gpt说到底,就是一个神经网络,它用了很多层”神经元"进行层层计算,最后得到一个结果(对gpt而言,就是得到一个token)。
但其本质还是“计算”,也就是说只能处理能够被计算的问题。而有些问题,在数学上被称为“不可计算约简性问题”,这类问题是不能由简单的计算就能得到结果的问题,比如生物学上很多问题,因为系统实在太过复杂。
目前看,只能用“模拟”它的步骤来得到一个近似结果,而非计算。
这些问题就是神经网络的局限。
另外,大语言模型真正有用的地方就是它比人类科学家学习的内容多,即使再天才的科学家也是人,人不可能穷尽某个领域的所有知识,所以科学家们每年都会到处开会,去看看别人在干嘛,怎么干的。
这样的话,大语言模型能帮助到人更快了解到他的研究领域内其他人干的事儿,从而帮助到工作。
只有好的数据,才能训练出好的模型。目前各家公司都没有把微调过程的数据公开,数据,算力,这些都决定了大语言模型的好坏。
我于是下载了Stephen Wolfram写的科普书《这就是ChatGPT》,166页,内容不多。书里没有长篇大论的数字符号,都是通俗的语言解释了ChatGPT的运行原理。

ChatGPT产品的公司老大为此书特别写了书评:这是我见过的对ChatGPT原理最佳的解释。

书籍已经传到了百度网盘,大家订图片右下角,输入暗号“大模型”,就可以有书了。
我只花两个多小时就翻完了,今天姐妹们半天假,可以看看这书,在放松自己的同时,获得了知识,是不是一举两得呀。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









